




人工智能YOLOv5目标检测必须掌握的全面核心知识

YOLOv5 train.py 文件详解:网络结构与模型加载核心
YOLOv5 的网络架构由四大组件构成——Input、Backbone、Neck 与 Head。每个模块的职责是什么?
Input 负责对输入图像进行预处理操作;Backbone 是主干特征提取网络,从图像中提炼出关键特征信息;Neck 模块充当特征的“融合器”,将不同尺度与层级的特征图进行整合或重组,从而生成更丰富的特征表示;最后 Head 负责最终决策,基于特征图来预测目标的位置(生成边界框)和类别。整个流程看似简单,但每个环节的细节都值得深入探究。
train.py 中模型加载的详细逻辑
以下代码是模型加载的核心部分,我们分步骤进行解析:
# ==============================================
# 步骤1:判断是否启用【预训练权重】
# ==============================================
# 检测权重文件是否以 .pt 结尾(PyTorch 模型文件标准格式)
# 若为 .pt,则代表使用预训练权重;否则从零开始训练
pretrained = weights.endswith('.pt')
# ==============================================
# 步骤2:若使用预训练权重 → 加载权重
# ==============================================
if pretrained:
# 多 GPU 训练时的同步保护:仅主进程下载权重,其余进程等待
with torch_distributed_zero_first(rank):
attempt_download(weights) # 权重文件缺失时自动从云端下载
# 加载 .pt 权重文件到当前设备
ckpt = torch.load(weights, map_location=device)
# 构建 YOLO 模型结构
# 优先采用命令行 --cfg 指定的配置,否则使用权重文件自带的配置
# ch=3 表示输入为 RGB 三通道图像
# nc=nc 表示数据集类别数量
# anchors= 传入锚框(若自动计算过则用新值)
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device)
# 定义加载权重时需要【排除】的键
# 若使用自定义模型或自定义锚框,则不加载原始权重中的 anchor 参数
exclude = ['anchor'] if (opt.cfg or hyp.get('anchors')) and not opt.resume else []
# 将权重转换为 FP32 高精度格式
state_dict = ckpt['model'].float().state_dict()
# 筛选权重:仅保留模型中存在的键(解决类别数不同导致的不匹配)
state_dict = intersect_dicts(state_dict, model.state_dict(), exclude=exclude)
# 将筛选后的权重加载到模型
# strict=False:允许缺失或多余的键,不报错
model.load_state_dict(state_dict, strict=False)
# 输出日志:成功加载的参数数量
logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model.state_dict()), weights))
# ==============================================
# 步骤3:无预训练权重 → 从零创建模型
# ==============================================
else:
# 直接创建一个全新的、随机初始化参数的模型
model = Model(opt.cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device)
# ==============================================
# 步骤4:验证数据集的正确性(路径与标签格式)
# ==============================================
with torch_distributed_zero_first(rank):
check_dataset(data_dict) # 检查数据集路径、图片及标签是否正常
通常情况下,我们都会使用预训练权重,这样模型收敛速度更快、性能更佳。核心代码其实只有一行:
model = Model(
opt.cfg or ckpt['model'].yaml, # 参数1:模型结构配置文件
ch=3, # 参数2:输入通道数(RGB)
nc=nc, # 参数3:类别数量
anchors=hyp.get('anchors') # 参数4:锚框配置
).to(device) # 将模型迁移到指定设备
关键参数说明:opt.cfg 是用户通过 --cfg models/yolov5s.yaml 显式指定的配置路径,常用于从零开始训练或修改网络结构后的重新训练;ckpt['model'].yaml 则是加载预训练权重时,checkpoint 文件中保存的原始结构配置,常用于断点续训或微调。
而 Model 类是 YOLOv5 官方定义在 models/yolo.py 文件中的核心类,专门用于创建 YOLO 检测模型。其导入方式也十分简洁:from models.yolo import Model。
yolo 文件中的核心代码解析
Detect 函数实现细节
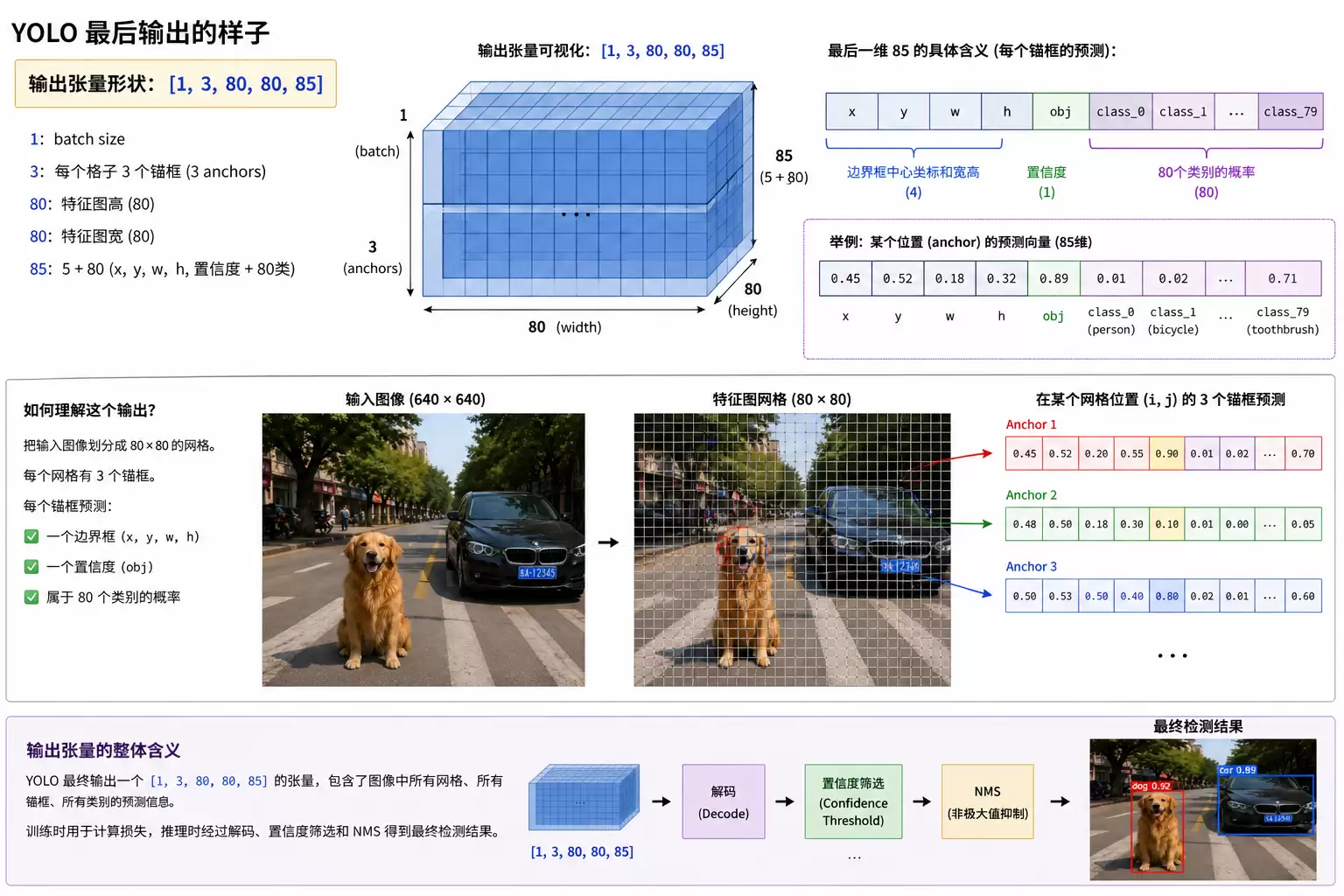
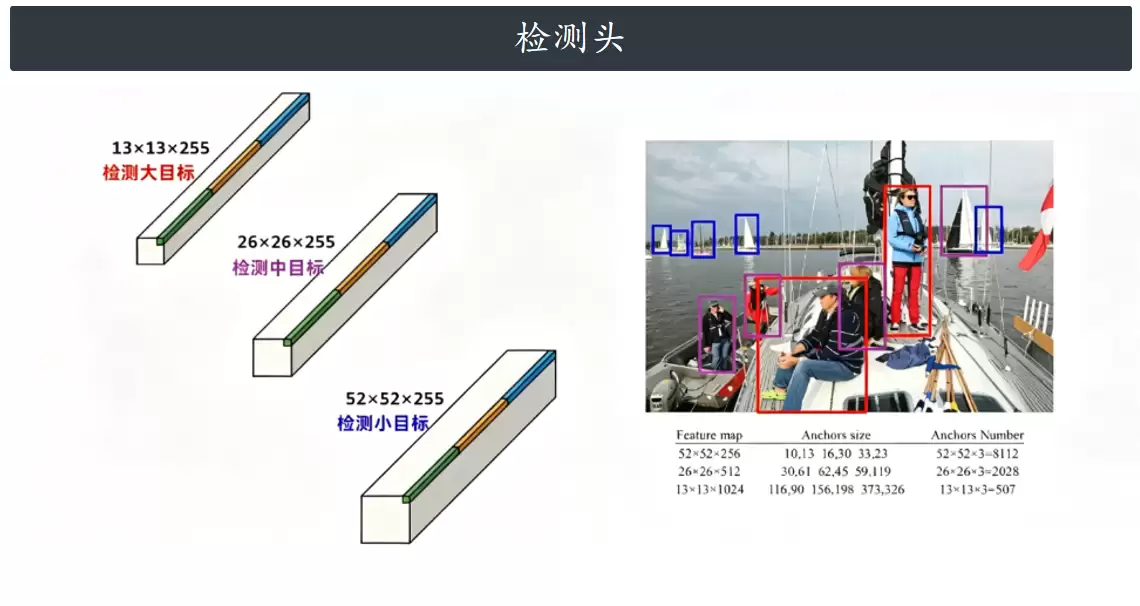
输入:假设输入图像尺寸为 640×640,模型会输出 3 个检测层:80×80(小目标)、40×40(中目标)、20×20(大目标)。每个层配置 3 个锚框,类别数 nc=80(COCO 数据集标准)。
输入是一个列表,包含来自网络上一层的三个不同尺度特征图:
x = [
# 检测层1:80×80 尺度
torch.Size([1, 256, 80, 80]),
# 检测层2:40×40 尺度
torch.Size([1, 512, 40, 40]),
# 检测层3:20×20 尺度
torch.Size([1, 1024, 20, 20])
]
输出分为两种模式:训练模式输出和推理模式输出。
- 情形 A:训练模式,输出三个检测层的原始特征:
[
torch.Size([1, 3, 80, 80, 85]),
torch.Size([1, 3, 40, 40, 85]),
torch.Size([1, 3, 20, 20, 85])
]
其中 [1, 3, 80, 80, 85] 的含义:1 为 batch size,3 表示每个网格有 3 个锚框,80 和 80 为特征图的高与宽,85 是 5(x,y,w,h,置信度) + 80 类。
- 情形 B:推理模式,输出展平后的所有检测框:
torch.Size([1, 25200, 85])
这里的 1 代表一张图,25200 是所有层的检测框总数(80×80×3 + 40×40×3 + 20×20×3),85 则包含 x, y, w, h, confidence 以及 80 个类别的概率。
 编辑
编辑
Model 类初始化——parse_model 函数
def parse_model(d, ch): 是模型构建的核心函数。参数 d 是从 YAML 文件解析得到的字典(即模型配置),ch 是输入通道数列表,初始值为 [3](RGB 三通道)。
先看一段典型配置:
anchors = [[10,13, 16,30, 33,23], [30,61, 62,45, 59,119], [116,90, 156,198, 373,326]]
nc = 80
gd = 0.33 # depth_multiplier(深度缩放因子)
gw = 0.50 # width_multiplier(宽度缩放因子)
# 计算 anchor 数量
# anchors[0] = [10,13, 16,30, 33,23] 共 6 个数 → 3 对 (w,h) → na = 3
na = len(anchors[0]) // 2 = 6 // 2 = 3
# 计算每个 anchor 的输出维度
# no = 3 × (80 + 5) = 255
no = na * (nc + 5) = 3 * 85 = 255
然后初始化容器:
layers, sa ve, c2 = [], [], ch[-1]
其中 layers 存放所有构建好的 PyTorch 模块,sa ve 存放需要“保存输出”的层索引(供后续跨层连接使用),c2 是当前层的输出通道数,初始值为 ch[-1] = 3。
来看 YAML 配置中的典型一行(以第一层为例):
# yolov5s.yaml 片段
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 6, 2, 2]] # 第0层
这一行的含义:-1 表示输入来自上一层,1 表示重复 1 次,Conv 表示卷积层,[64,6,2,2] 表示输出通道 64、卷积核 6×6、步长 2、padding 2。
解析时,实际会执行:
i, (f, n, m, args) = (0, -1, 1, 'Conv', [64,6,2,2])
m = eval('Conv') # 此时 m 指向我们定义的 Conv 类
深度因子缩放:n = round(1 * 0.33) = 1
c1 = ch[f] # f=-1 → ch[-1] = 3(输入通道数)
c2 = args[0] = 64 # 输出通道
# 宽度因子缩放:64 * 0.5 = 32
c2 = make_divisible(64 * 0.5, 8) = 32
# 最终参数变为:
args = [3, 32, 6, 2, 2]
最终创建:m_ = Conv(3, 32, 6, 2, 2),并设置层索引:m_.i = 0,m_.f = -1,更新通道列表:ch.append(32),最后 layers.append(Conv(3,32,6,2,2))。
parse_model 能够识别并创建这些层,是因为 from models.common import * 导入了所有基础网络层(Conv、C3、SPP、Bottleneck 等),from models.experimental import * 导入了实验性层。
YOLOv5 的 YAML 配置文件详解
先看 anchors 部分:
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
每个 anchor 是一对 (w, h) 数值:
[10,13, 16,30, 33,23]
↓ ↓ ↓ ↓ ↓ ↓
w h w h w h
第1个 第2个 第3个
anchor anchor anchor
它们对应不同的检测尺度和特征图大小:
| 尺度 | 下采样倍数 | 特征图大小(640输入) | 适合检测 | Anchor 大小 |
|---|---|---|---|---|
| P3/8 | 8 倍 | 80 × 80 | 小目标 | 10~33 像素 |
| P4/16 | 16 倍 | 40 × 40 | 中目标 | 30~119 像素 |
| P5/32 | 32 倍 | 20 × 20 | 大目标 | 116~373 像素 |
接下来看 backbone 配置:
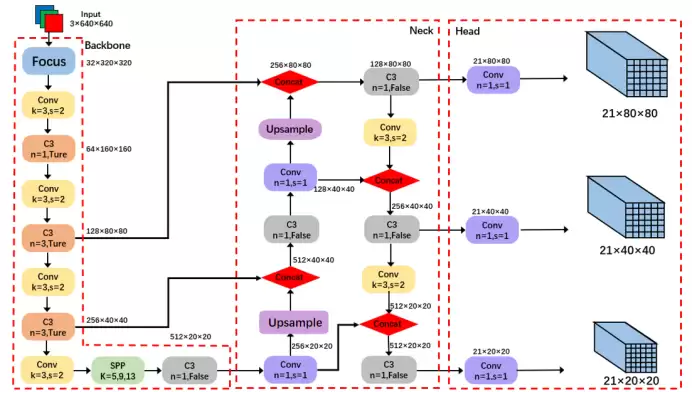
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2 ← 320×320
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4 ← 160×160
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8 ← 80×80 ⭐ 小目标
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16 ← 40×40 ⭐ 中目标
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 ← 20×20 ⭐ 大目标
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]]] # 9
逐层解读:
- 第 0 层使用 Focus 模块,通过 3×3 卷积将特征图下采样至 320×320×64,实现无信息损失的空间下采样与通道扩充;
- 第 1 层通过 Conv 模块(128 通道、3×3 卷积核、步长 2)将特征图尺寸压缩至 160×160×128;
- 第 2 层堆叠 3 个 C3 模块,在 160×160×128 尺度完成残差特征融合与强化;
- 第 3 层通过 Conv 模块(256 通道、步长 2)下采样至 80×80×256,形成小目标检测基础特征层;
- 第 4 层堆叠 9 个 C3 模块,在 80×80×256 尺度完成深层特征提取;
- 第 5 层经 Conv 模块(512 通道、步长 2)下采样至 40×40×512,构成中目标特征层;
- 第 6 层再次堆叠 9 个 C3 模块,在 40×40×512 尺度进一步增强特征表达能力;
- 第 7 层通过 Conv 模块(1024 通道、步长 2)下采样至 20×20×1024,形成大目标高语义特征层;
- 第 8 层接入 SPP 空间金字塔池化模块,使用 5×5、9×9、13×13 池化核在 20×20×1024 尺度融合多感受野全局特征;
- 第 9 层通过 3 个 C3 模块(无 shortcut)完成最终特征整合,输出 20×20×1024 的深层语义特征,为后续多尺度检测提供强表征能力的特征支撑。
接着看 head 配置:
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
YOLOv5 的 Head(检测头)基于 PANet 结构构建,负责多尺度特征融合、上采样、下采样与目标检测,整体分为自上而下的上采样融合和自下而上的下采样融合两个阶段,最终输出三个尺度的检测特征图,并接入 Detect 层完成预测。
- 第 10 层采用 Conv 模块(512 通道、1×1 卷积核),将输入的 20×20×1024 特征图压缩为 20×20×512,实现通道降维;
- 第 11 层通过 nn.Upsample 上采样模块,将特征图放大 2 倍,尺寸变为 40×40×512;
- 第 12 层将上采样特征与主干网络第 6 层的 40×40×512 特征进行 Concat 拼接,输出 40×40×1024 融合特征;
- 第 13 层堆叠 3 个 C3 模块(无 shortcut),在 40×40×512 尺度完成特征精炼;
- 第 14 层使用 Conv 模块(256 通道、1×1 卷积),将特征压缩为 40×40×256;
- 第 15 层通过上采样放大 2 倍,得到 80×80×256 特征图;
- 第 16 层将其与主干网络第 4 层 80×80×256 特征 Concat 拼接,输出 80×80×512;
- 第 17 层堆叠 3 个 C3 模块,输出 80×80×256 特征,对应 P3 小目标检测分支;
- 第 18 层采用 Conv 模块(256 通道、3×3 卷积、步长 2)下采样,得到 40×40×256;
- 第 19 层与第 14 层 40×40×512 特征 Concat 拼接,输出 40×40×768;
- 第 20 层堆叠 3 个 C3 模块,输出 40×40×512 特征,对应 P4 中目标检测分支;
- 第 21 层通过 Conv 模块(512 通道、3×3 卷积、步长 2)下采样至 20×20×512;
- 第 22 层与第 10 层 20×20×512 特征 Concat 拼接,输出 20×20×1024;
- 第 23 层堆叠 3 个 C3 模块,输出 20×20×1024 特征,对应 P5 大目标检测分支;
- 第 24 层为 Detect 检测层,接收 P3(80×80×256)、P4(40×40×512)、P5(20×20×1024) 三个尺度特征,完成目标框坐标、置信度与类别的预测输出。
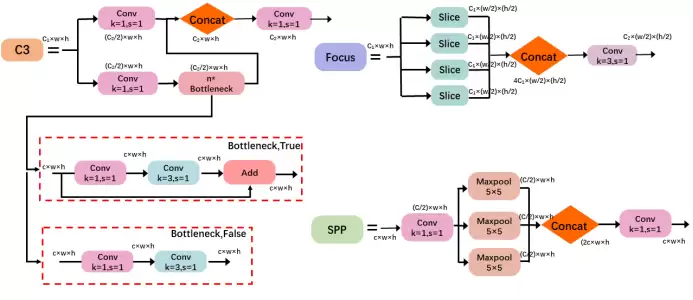
common.py 中的 Concat 层定义
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
这个 Concat 模块的功能非常直观:接收多个具有相同高宽但不同通道数的特征图,沿着通道维度(dim=1)进行拼接融合,输出通道数叠加、空间尺寸保持不变的融合特征图。其目的是增强多尺度上下文信息与特征表达能力——简单来说,就是将不同层次的信息整合在一起,让检测头能够“看清”更多细节。
 编辑
编辑
 编辑
编辑
标签标注部分
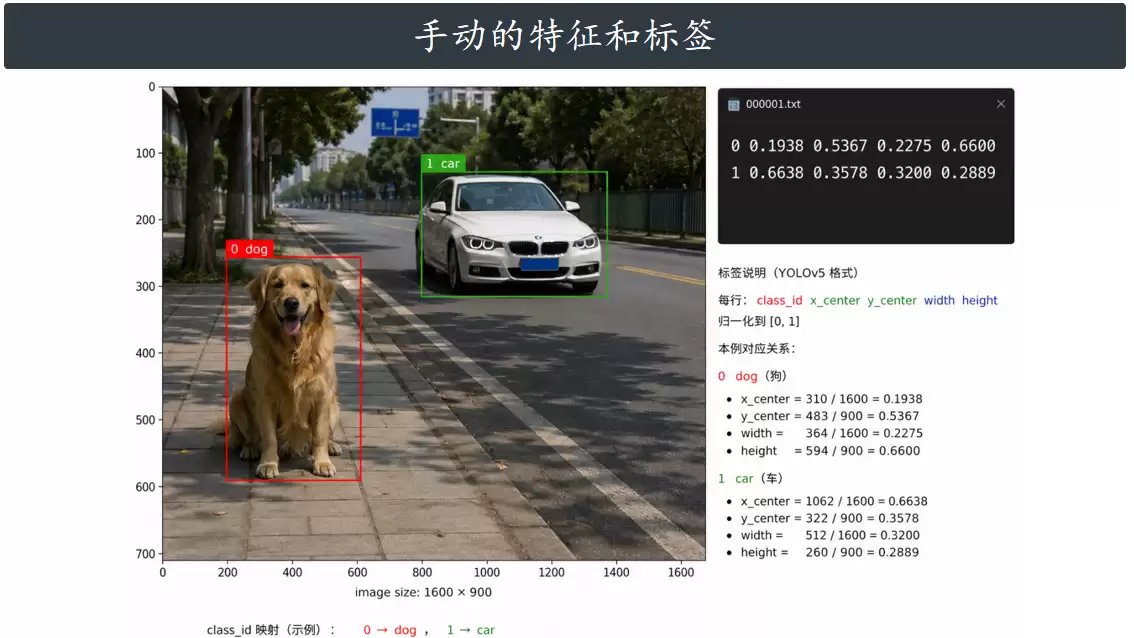
这张图展示了在 YOLO 目标检测任务中,如何为图像中的物体进行标注(写入 txt 文件),这是模型训练前最基础的步骤。假设有一张图片,其标签格式如下:
16 0.412 0.530 0.234 0.661 # 狗
2 0.812 0.620 0.180 0.290 # 车
| 数字 | 含义 | 通俗解释 |
|---|---|---|
16 |
class_id | 该物体属于第 0 类,即“狗” |
| 0.412 | x_center | 狗的中心在图片宽度方向上的相对位置 |
| 0.530 | y_center | 狗的中心在图片高度方向上的相对位置 |
| 0.234 | width | 狗的边界框占图片总宽度的比例 |
| 0.661 | height | 狗的边界框占图片总高度的比例 |
 编辑
编辑
train.py 文件中的数据集读取部分
数据配置文件的读取
以下代码的功能是读取一个 YAML 格式的配置文件,并将其解析为 Python 字典,以便后续训练脚本能够访问其中的配置项(例如训练集路径、类别数量、类别名称等)。
# 打开由命令行参数 --data 指定的 YAML 配置文件
# opt.data 通常是一个字符串路径,例如 'data/coco128.yaml'
# 使用 with 上下文管理器,可以在读取完毕后自动关闭文件,避免资源泄露
with open(opt.data) as f:
# 使用 PyYAML 库的 load 函数,将文件内容解析成 Python 字典
# 参数 f:已打开的文件对象,作为输入流
# 参数 Loader=yaml.SafeLoader:指定安全加载器
# - SafeLoader 仅解析 YAML 标准的基本数据类型(字典、列表、字符串、数字等)
# - 它会拒绝执行 YAML 中可能包含的任意 Python 代码,防止恶意代码注入
# - 相比之下,默认的 yaml.Loader 存在安全风险,官方已不推荐使用
# 解析结果赋值给 data_dict,这是一个 Python 字典对象
data_dict = yaml.load(f, Loader=yaml.SafeLoader) # data dict
以 YOLOv5 自带的 coco128.yaml 为例:
# 训练集和验证集的路径
train: ../datasets/coco128/images/train2017/
val: ../datasets/coco128/images/train2017/
# 类别数量
nc: 80
# 类别名称列表(索引与 class_id 对应)
names: ['person', 'bicycle', 'car', 'motorcycle', ...]
经过解析,上述文件会变成这样一个 Python 字典:
data_dict = {
'train': '../datasets/coco128/images/train2017/',
'val': '../datasets/coco128/images/train2017/',
'nc': 80,
'names': ['person', 'bicycle', 'car', 'motorcycle', ...]
}
获取数据集路径
train_path = data_dict['train'] # 训练集路径
test_path = data_dict['val'] # 验证集路径
创建训练数据加载器
# ===================== 核心功能 =====================
# 创建【训练集】的数据加载器(DataLoader)和数据集(Dataset)对象
# 作用:批量、多线程加载训练图片+标签,是模型训练的"数据搬运工"
# =====================
dataloader, dataset = create_dataloader(
train_path, # 1. 训练集图片/标签的根路径
imgsz, # 2. 模型输入的统一图像尺寸 (如 640)
batch_size, # 3. 批次大小:每次喂给模型多少张图片
gs, # 4. 网格步长(Grid Stride):YOLO下采样倍数(8/16/32),保证尺寸整除
opt, # 5. 命令行参数对象(所有运行参数都在这里)
hyp=hyp, # 6. 训练超参数字典(学习率、损失函数系数等)
augment=True, # 7. 开启训练数据增强(翻转、缩放、色域变换等,提升泛化能力)
cache=opt.cache_images, # 8. 是否缓存图片到内存/磁盘:加速训练(避免重复读取硬盘)
rect=opt.rect, # 9. 矩形训练模式:按图片原始比例缩放,节省显存
rank=rank, # 10. 多GPU训练时:当前进程的GPU编号
world_size=opt.world_size, # 11. 多GPU训练时:总GPU数量
workers=opt.workers, # 12. 数据加载线程数:多线程并行读图片,速度更快
image_weights=opt.image_weights, # 13. 样本权重:给困难样本/小目标加权训练
quad=opt.quad, # 14. 四边形数据加载:适配超大批次训练的加速选项
prefix=colorstr('train: ') # 15. 日志打印前缀:终端输出带颜色的"train: "标识
)
| 返回值 | 含义 | 作用 |
|---|---|---|
dataset |
数据集对象 | 管理所有训练图片、标签路径,负责读取单张图 + 解析标签 |
dataloader |
数据加载器 | 核心搬运工:批量、多线程、乱序把数据递给模型训练 |
该函数从 utils/datasets.py 导入。
数据预处理与标签处理
# 仅在【不恢复训练】时执行(从头训练才走这里,断点续训跳过)
if not opt.resume:
# 1. 拼接训练集中所有图片的标签数据 (形状: [总目标数, 5]),5列=类别+中心x+中心y+宽+高
labels = np.concatenate(dataset.labels, 0)
# 2. 提取所有目标的【类别ID】,转为PyTorch张量
c = torch.tensor(labels[:, 0]) # classes
# 以下两行是注释掉的代码:根据类别频率初始化模型偏置,官方默认关闭
# cf = torch.bincount(c.long(), minlength=nc) + 1. # 统计每个类别的目标数量
# model._initialize_biases(cf.to(device))
# 3. 如果开启可视化(plots=True),绘制标签分布图(类别、框大小、位置)
if plots:
plot_labels(labels, names, sa ve_dir, loggers)
# 如果启用TensorBoard,将类别分布写入日志,方便可视化查看
if tb_writer:
tb_writer.add_histogram('classes', c, 0)
# 4. 锚框(Anchor)优化:核心功能!自动计算适配数据集的最优锚框
# 如果没有关闭自动锚框(opt.noautoanchor=False),就执行检查/计算锚框
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
# 5. 模型精度预处理:先转半精度再转回单精度,优化锚框计算精度(不影响训练)
model.half().float()
这里的核心操作是拼接所有标签。假设:
- 图片 1:有 2 个物体(狗 = 0,车 = 1)→ 标签 2 行
- 图片 2:有 1 个物体(人 = 2)→ 标签 1 行
- 总目标数:3 个
标签文件内容如下:
img1.txt(一张图两个物体)
0 0.412 0.530 0.234 0.661 # 狗
1 0.812 0.620 0.180 0.290 # 车
img2.txt
2 0.500 0.500 0.100 0.200 # 人
数据集存储时,dataset.labels 是一个列表:
dataset.labels = [
# 图片1:2个物体 → 形状 (2, 5)
np.array([
[0, 0.412, 0.530, 0.234, 0.661],
[1, 0.812, 0.620, 0.180, 0.290]
]),
# 图片2:1个物体 → 形状 (1, 5)
np.array([
[2, 0.500, 0.500, 0.100, 0.200]
])
]
执行 np.concatenate(dataset.labels, 0) 后,所有标签被合并为一个二维数组:
labels = [
[0, 0.412, 0.530, 0.234, 0.661], # 图1-狗
[1, 0.812, 0.620, 0.180, 0.290], # 图1-车
[2, 0.500, 0.500, 0.100, 0.200] # 图2-人
]
# 最终形状:(3, 5) → 3个物体,5列参数
提取类别 ID:c = torch.tensor(labels[:, 0]),得到 c = tensor([0, 1, 2]),对应三个物体的类别:狗、车、人。
网络最终的输出
来看一个完整的测试流程:
import torch
from models.yolo import Model
model = Model('models/yolov5m.yaml')
model.eval()
x = torch.randn(2, 3, 640, 640)
# 推理模式
with torch.no_grad():
out = model(x)
print(type(out)) # tuple
print(out[0].shape) # torch.Size([2, 25200, 85])
print(len(out[1])) # 3
print([o.shape for o in out[1]])
# [torch.Size([2, 3, 80, 80, 85]),
# torch.Size([2, 3, 40, 40, 85]),
# torch.Size([2, 3, 20, 20, 85])]
# 训练模式
model.train()
out = model(x)
print(type(out)) # list
print([o.shape for o in out])
# [torch.Size([2, 3, 80, 80, 85]),
# torch.Size([2, 3, 40, 40, 85]),
# torch.Size([2, 3, 20, 20, 85])]
实际运行结果:
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
torch.Size([2, 25200, 85])
3
[torch.Size([2, 3, 80, 80, 85]), torch.Size([2, 3, 40, 40, 85]), torch.Size([2, 3, 20, 20, 85])]
[torch.Size([2, 3, 80, 80, 85]), torch.Size([2, 3, 40, 40, 85]), torch.Size([2, 3, 20, 20, 85])]
三个输出分支的含义:
[2, 3, 80, 80, 85]:小目标分支,负责检测小尺寸物体[2, 3, 40, 40, 85]:中目标分支,负责检测中等尺寸物体[2, 3, 20, 20, 85]:大目标分支,负责检测大尺寸物体
 编辑
编辑
推理阶段
获取类别名称和颜色
names = model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
假设有 3 个类别:
names = ['cat', 'dog', 'bird']
colors = [
[123, 45, 67], # cat 的颜色:RGB(123, 45, 67)
[255, 100, 200], # dog 的颜色:RGB(255, 100, 200)
[50, 200, 150] # bird 的颜色:RGB(50, 200, 150)
]
图像预处理(直接调用 letterbox 函数)
流程如下:
输入图像 (720×1280×3, uint8, BGR)
│
▼
┌──────────────────────────────────┐
│ letterbox(img0, new_shape=640) │
└──────────────────┬───────────────┘
│
▼
(640×640×3, uint8, BGR)
│
▼
┌──────────────────────────────────┐
│ [:, :, ::-1] → BGR→RGB │
│ .transpose(2, 0, 1) → HWC→CHW │
└──────────────────┬───────────────┘
│
▼
(3×640×640, uint8, RGB)
│
▼
┌──────────────────────────────────┐
│ torch.from_numpy() → tensor │
│ .float() / 255 → 归一化 │
│ .to(device) → 移动到设备 │
└──────────────────┬───────────────┘
│
▼
(3×640×640, float32, RGB, 0~1)
│
▼
┌──────────────────────────────────┐
│ .unsqueeze(0) → 添加批次维度 │
└──────────────────┬───────────────┘
│
▼
最终输出: (1×3×640×640, float32, RGB, 0~1, device)
推理
print("正在推理...")
with torch.no_grad():
pred = model(img)[0] # 直接获取检测结果
模型输出是一个元组:
output = model(img)
# output = (detections, raw_features)
# detections: 解码后的检测框,形状 [batch, 25200, 85]
# raw_features: 原始特征图列表,包含3个张量
所以 pred = model(img)[0] 获取的是元组的第一个元素——detections:
print(pred.shape) # torch.Size([1, 25200, 85])
| 维度 | 含义 | 值 | 说明 |
|---|---|---|---|
| 第0维 | 批次大小 | 1 | 我们只输入了一张图片 |
| 第1维 | 检测框总数 | 25200 | 3个检测层 × 8400个网格点 |
| 第2维 | 每个检测框的输出 | 85 | 5个坐标 + 80个类别概率 |
25200 这个数字怎么来的?
3个检测层:
- 第一层:80×80 = 6400 个网格
- 第二层:40×40 = 1600 个网格
- 第三层:20×20 = 400 个网格
每个网格有3个锚点,所以:
(6400 + 1600 + 400) × 3 = 8400 × 3 = 25200
假设输入一张包含“人”和“车”的图片,图像尺寸 640×640,内容是一个人站在车旁边。那么推理结果可能是:
pred[0] = [
# 检测框 0:检测到一个人
[0.5, # x_center: 图像水平中心位置
0.3, # y_center: 图像上部(30%高度处)
0.2, # width: 宽度占图像的20%
0.4, # height: 高度占图像的40%
0.95, # conf: 95%置信度
1.0, # cls_0: person类别概率100%
0.0, # cls_1: bicycle类别概率0%
0.0, # cls_2: car类别概率0%
...], # 其他77个类别概率都是0%
# 检测框 1:检测到一辆车
[0.7, # x_center: 图像右侧(70%宽度处)
0.6, # y_center: 图像中部偏下(60%高度处)
0.3, # width: 宽度占图像的30%
0.5, # height: 高度占图像的50%
0.88, # conf: 88%置信度
0.0, # cls_0: person类别概率0%
0.0, # cls_1: bicycle类别概率0%
1.0, # cls_2: car类别概率100%
...], # 其他类别概率都是0%
# 检测框 2~25199:背景或低置信度检测
[0.1, 0.1, 0.05, 0.05, 0.01, 0.0, 0.0, ...], # 置信度只有1%
...
]
我们可以把它想象成一个 25200×85 的矩阵,每一行代表一个检测框对应的 85 维向量。
NMS 过滤
print("正在进行NMS过滤...")
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45)
| 参数 | 含义 | 值 |
|---|---|---|
pred |
输入检测结果 | [1, 25200, 85] |
conf_thres |
置信度阈值 | 0.25 |
iou_thres |
IOU阈值 | 0.45 |
经过 NMS 过滤后,只剩下两个有效检测框:
pred_output = [
tensor([[256, 64, 384, 320, 0.95, 0]]), # person
tensor([[352, 256, 544, 576, 0.88, 2]]) # car
]
| 检测框 | x1 | y1 | x2 | y2 | conf | cls | 含义 |
|---|---|---|---|---|---|---|---|
| 0 | 256 | 64 | 384 | 320 | 0.95 | 0 | person(类别0) |
| 1 | 352 | 256 | 544 | 576 | 0.88 | 2 | car(类别2) |
处理检测结果
det = pred[0]
det = tensor([
[256, 64, 384, 320, 0.95, 0], # person
[352, 256, 544, 576, 0.88, 2] # car
])
det.shape = (2, 6) # 2个检测框,每个6个维度
转换坐标
经过坐标转换后:
det = tensor([
[512, 0, 768, 360, 0.95, 0], # 原始图像坐标
[704, 232, 1088, 872, 0.88, 2]
])
每个检测框的六个值:
| 索引 | 名称 | 含义 | 示例值 |
|---|---|---|---|
| 0 | x1 | 检测框左上角的 x 坐标(像素) | 512 |
| 1 | y1 | 检测框左上角的 y 坐标(像素) | 0 |
| 2 | x2 | 检测框右下角的 x 坐标(像素) | 768 |
| 3 | y2 | 检测框右下角的 y 坐标(像素) | 360 |
| 4 | conf | 目标存在的置信度(0~1) | 0.95 |
| 5 | cls | 目标的类别索引(0~79) | 0 |
在原始图像上的位置示意:
图像左上角为原点 (0, 0)
┌─────────────────────────────────────────────────────────────────────┐
│ (0,0) ← x轴方向 (向右) │
│ ↓ │
│ y轴方向 (向下) │
│ │
│ 检测框0 │
│ ┌─────────────────────────────┐ │
│ │ (512,0) │ │
│ │ person │ │
│ │ 0.95 │ │
│ └─────────────────────────────┘ (768,360) │
│ │
│ 检测框1 │
│ ┌─────────────────────────────┐ │
│ │ (704,232) │ │
│ │ car │ │
│ │ 0.88 │ │
│ └─────────────────────────────┘ (1088,872) │
│ │
└─────────────────────────────────────────────────────────────────────┘
原始图像尺寸:1280 × 720 像素
获取类别名称:
names = model.names # ['person', 'bicycle', 'car', ...]
# 检测框0
cls_idx = int(det[0, 5]) # 0
class_name = names[cls_idx] # 'person'
# 检测框1
cls_idx = int(det[1, 5]) # 2
class_name = names[cls_idx] # 'car'
最后的检测效果
原始图像 (1280×720)
┌─────────────────────────────────────────────────────────────────────┐
│ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ person 0.95 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────┐ │
│ │ car 0.88 │ │
│ └─────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────┘

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

FlutterFlow零基础低代码开发从入门到精通完整教程
FlutterFlow全面解析:什么是低代码开发平台 谈及低代码与无代码开发平台,FlutterFlow在行业内已逐渐为开发者所熟知。该平台由Sirian M 与团队共同创立的GiftIt公司推出,本质上是一个视觉化开发环境——用户只需在浏览器中通过拖拽操作,即可构建移动端、网页端及桌面端应用,同

AI工具助力财务工作计划:年终总结、项目总结与日常预算
适合需求:财务工作的高效开展,很大程度上取决于年度财务工作计划的制定质量。一份科学严谨的财务计划,能够帮助企业全面掌握经营状况,为管理决策提供可靠依据,避免仅凭经验拍脑袋。具体如何落地?财务年终总结、项目财务复盘以及日常财务预算编制,是财务人员最核心的三个工作场景。本文将介绍如何借助AI财务工具,在

Moonhub AI招聘加速人才获取降低雇佣成本
Moonhub产品介绍在招聘这件事上,效率就是竞争力。Moonhub这家公司,瞄准的正是用AI把招聘流程重新梳理一遍。它的核心逻辑很简单:让机器把海量候选人筛一遍,再交给人类来做判断和决策。说白了,就是帮你更快地找到对的人,而且成本更低。先来说一个核心判断:Moonhub并不只是搞个简历筛选工具那么

利用Opus 4.8实现大规模并行子袋里编排
Claude Opus 4 8 为 Claude Code 带来了一项真正值得关注的能力:Dynamic Workflows。简单来说,在一个会话里,编排智能体可以同时启动数百个并行子袋里,去处理那些分支多、规模大的任务——比如跨几十个文件的重构、跑一个庞大的测试矩阵,或者并行探索多种实现方案。在终

AI写作机器人提升文档效率成办公自动化利器
如何利用AI写作机器人提升文档创作效率,成为办公自动化的利器 先抛出一个核心问题:在快节奏的办公环境中,文档撰写到底能不能“开挂”?从市场反馈和技术演进来看,答案是肯定的。AI写作机器人正在从辅助工具升级为文档创作的核心引擎,尤其对于那些需要频繁输出报告、提案、合同的企业来说,这玩意儿已经不是“锦上








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
