




MATLAB实现高斯混合模型与马尔可夫模型结合

在高斯混合模型(GMM)与马尔可夫模型(Markov)的联合框架下,时序数据的建模能力会得到显著增强——简而言之,就是将马尔可夫链的状态转移机制与GMM的概率密度估计能力融为一体。下面从理论推导到代码实现,再到真实场景的应用案例,完整走一遍这条技术路线。
一、算法原理与模型架构
1. 模型组合形式
GMM-Markov联合模型的核心思路是:利用马尔可夫链刻画序列中隐含状态的转移规律,而每个隐藏状态下的观测值则通过一个高斯混合分布来描述。这种结构非常适合那些观测数据呈现多峰分布、且状态在时间上存在依赖关系的场景。
数学上可以表示为:
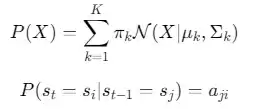
其中 $\pi_k$ 是混合权重,$a_{ji}$ 是状态转移概率——前者决定了GMM中每个分量的占比,后者决定了马尔可夫链中状态j转移到i的可能性。
2. 关键参数
| 参数类型 | 定义域 | 典型取值范围 | 作用 |
|---|---|---|---|
| 混合分量数 K | 状态数 | 2-10 | 决定模型复杂度 |
| 协方差类型 | 'full'/'diag' | 视数据维度而定 | 影响模型灵活性 |
| 转移矩阵约束 | 行随机矩阵 | 各行和为1 | 保证马尔可夫性质 |
这些参数的选择直接决定了模型的拟合能力与泛化性能。例如,K值过大容易导致过拟合,过小则欠拟合;而协方差选用'full'还是'diag',取决于特征之间相关性的显著程度。
二、MATLAB实现代码
1. 数据准备与初始化
首先构造一组模拟数据:两个正弦信号分别代表两种隐藏状态,并叠加随机噪声,用于验证模型能否正确区分。代码非常简洁直观:
% 生成模拟数据(两状态交替过程)
t = 0:0.1:10;
data1 = 2*sin(2*pi*t) + 0.5*randn(size(t));
data2 = -2*sin(2*pi*t) + 0.5*randn(size(t));
data = [data1; data2]';
% 初始化参数
K = 2; % 混合分量数
Q = 2; % 隐状态数
max_iter = 100; % 最大迭代次数2. GMM-Markov联合训练
接下来定义初始转移矩阵与GMM参数,然后调用hmmtrain进行EM迭代训练。这里借助了MATLAB统计与机器学习工具箱,核心代码仅需几行:
% 定义状态转移矩阵(初始猜测)
trans_init = [0.8 0.2; 0.3 0.7];
% 定义观测模型(GMM参数)
mu_init = [1; -1]; % 均值向量
sigma_init = cat(3, [0.5 0.2; 0.2 0.5]); % 协方差矩阵
mix_init = [0.6; 0.4]; % 混合权重
% 使用EM算法联合训练
options = statset('MaxIter', max_iter);
[estTrans, estMu, estSigma, estMix] = hmmtrain(data, trans_init, ...
'emOptions', statset('Display', 'iter'), ...
'CovType', 'full', ...
'MixModel', { mu_init, sigma_init, mix_init });训练过程中会输出每次迭代的似然值变化,便于监控收敛情况。
3. 模型验证与可视化
用另一段测试数据进行状态解码,检验模型能否正确识别隐藏的状态序列:
% 生成测试序列
test_data = [2*sin(2*pi*(0:0.1:5)) + 0.3*randn(1,51);
-2*sin(2*pi*(0:0.1:5)) + 0.3*randn(1,51)]';
% 状态解码
[~, loglik, state_seq] = hmmviterbi(test_data, estTrans, estMu);
% 可视化结果
figure;
subplot(2,1,1);
plot(1:length(data), data(:,1), 'b', 1:length(data), data(:,2), 'r');
hold on;
stem(find(state_seq==1), data(state_seq==1,1), 'go');
title('状态序列与观测数据');
subplot(2,1,2);
plot(1:length(test_data), test_data(:,1), 'b', 1:length(test_data), test_data(:,2), 'r');
hold on;
stem(find(state_seq==1), test_data(state_seq==1,1), 'go');
title('测试数据状态解码结果');三、核心算法优化
1. 收敛性加速策略
一个非常实用的技巧是使用K-means来初始化GMM的中心,这比随机初始化收敛更快、更稳定:
[idx, centers] = kmeans(data(:,1), K);
mu_init = centers';另外,协方差矩阵在迭代过程中容易变得奇异,可以添加一个小正则项来防止数值问题:
estSigma(:, :, i) = estSigma(:, :, i) + 1e-6 * eye(size(estSigma, 1));2. 计算效率提升
如果数据量较大,EM迭代可以利用parfor进行并行加速(需安装Parallel Computing Toolbox):
parfor iter = 1:max_iter
% 并行计算E-step和M-step
end值得注意的是,高维数据通常噪声多、冗余大,可先做PCA降维再建模,效果往往会更好:
[coeff, score] = pca(data);
data_pca = score(:, 1:2); % 保留前两个主成分四、典型应用场景
1. 语音信号处理
在连续语音识别中,每个音素可视为一个隐藏状态,其声学特征(如MFCC)服从一个GMM分布。实现方法是先用mfcc提取特征,再套用GHMM框架:
% 使用mfcc特征作为观测序列
[coeff, score] = mfcc(audio_signal);
% 构建GHMM模型
model = hmmtrain(score, trans_init, obs_init);2. 金融时间序列分析
股票市场常被划分为“牛市”和“熊市”两种状态,状态间转移概率可用马尔可夫链建模,而每种状态下的收益率则服从高斯分布(或混合高斯)。以S&P 500为例:
% 加载S&P500数据
data = readtable('sp500.csv');
returns = diff(log(data.AdjustedClose));
% 定义状态转移约束(牛市/熊市转换概率)
trans = [0.95 0.05; 0.1 0.9];
% 训练GHMM模型
[estTrans, estMu] = hmmtrain(returns, trans);3. 工业设备故障诊断
设备振动信号通常包含正常和异常两种隐藏状态,通过GHMM可以实时计算当前信号属于正常状态的概率,当似然概率低于阈值时触发报警:
实现流程:
- 采集振动信号并提取时频特征
- 构建包含正常/异常状态的GHMM
- 计算观测序列的似然概率
% 计算测试序列的似然
logprob = hmmlogprob(test_vibration, estTrans, estMu);
% 设置阈值进行故障判断
if logprob < threshold
disp('异常状态报警!');
end五、注意事项
- 数据预处理:时序数据务必先做标准化或归一化,否则不同量纲的特征会严重影响GMM的似然计算。
- 状态数量选择:不要凭经验确定K值,建议采用BIC(贝叶斯信息准则)对不同K值进行对比,选取使BIC最小的那个。
- 计算资源:若数据量达到几百兆甚至上G,可考虑使用GPU加速(需安装Parallel Computing Toolbox),从而大幅节省运行时间。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

旅行社活动策划:AI写作提升客户体验与市场份额
适合需求: 旅行社活动策划总结与优化指南 过去一年,旅行社在活动策划和组织执行方面交出了一份亮眼的成绩单。团队在每个环节主动突破舒适区,目标非常明确——让客户真正体验到旅行的核心价值与深度乐趣。 范文 Demo: 旅行社活动策划总结报告 转眼间一年过去,回顾来看,旅行社在活动策划与组织领域积累了诸多

猿辅导飞象老师AI教学辅助工具
飞象老师是什么 你或许已经留意到,2025年末教育领域出现了一款名叫「飞象老师」的创新工具——确切来说,这是猿辅导专门为教师群体量身打造的AI教学辅助平台。该产品于2025年12月1日正式上线,恰巧在教育部发布《教师生成式人工智能应用指引》之后亮相,成为首个落地的教师端AI应用。其背后支撑来自猿辅导

咖啡馆市场策略:激烈竞争中脱颖而出
适合需求: 放眼当下的咖啡馆市场,单凭一杯精品咖啡就想脱颖而出,已经越来越难了。业界普遍认同,真正决定胜负的关键,恰恰在于市场策略。从选品构思到品牌传播,从外卖运营到堂食体验,每个环节都需要精准布局。越来越多的创业者和商家已深刻意识到,与其陷入价格内卷,不如在策略层面找到属于自己的节奏,这样才能真正

CNKI全球学术资源平台 连接中国与世界的知识共享
CNKI产品介绍 CNKI作为知网的国际化版本,是一个面向全球学术资源的综合性平台,其核心使命在于打破语言壁垒,助力不同母语的研究者轻松获取和分享知识。 它的具体功能可从以下六大模块来理解: 多语言支持:提供韩语、日语、俄语及阿拉伯语等界面,非中文母语用户可直接使用熟悉语言操作,大幅降低了学术资源访

咖啡店会员卡营销方案设计策略与AI工具应用指南
适合需求:打造高吸引力的咖啡店会员卡营销策划方案在如今这个节奏飞快的时代,咖啡早已融入许多人的日常,成为一种生活方式。随着咖啡消费量不断攀升,越来越多咖啡店选择推出会员卡来增强顾客忠诚度。这不仅是营销手段的体现,更是优化顾客体验、提升留存率的关键举措。范文 Demo:设计具有吸引力的咖啡店会员卡营销








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
