




多模态基础:CNN与ViT详解

Transformer架构在自然语言处理领域已占据无可撼动的主导地位。从设计特性来看,这套框架能够有效处理任意类型的序列数据——不仅限于文本,图像同样在其适用范围内。有趣的是,与传统的卷积神经网络相比,Transformer在许多任务上同样能交出优异,甚至更出色的成绩。那么,这背后的原因是什么?本文将从卷积神经网络入手,逐步拆解分析。
2. 卷积神经网络
卷积神经网络(CNN),一提起它,人们首先联想到的是图像识别、语音识别等应用场景。尤其是在计算机视觉领域,CNN几乎是标配工具,从图像分类、目标检测到图像分割,处处可见它的身影。
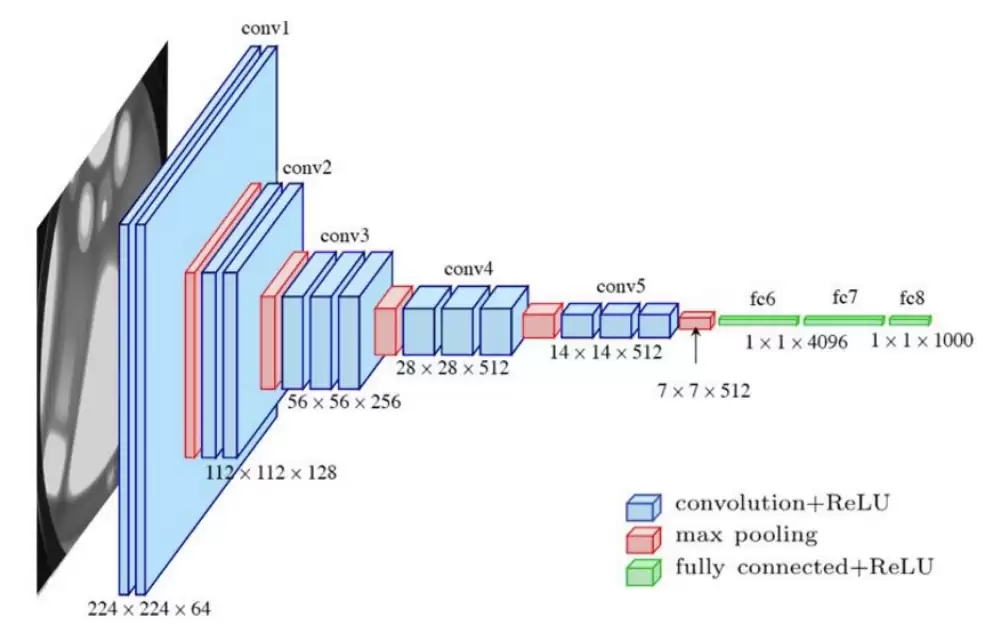
CNN的能力主要建立在几个核心组件上:卷积层、池化层以及不可或缺的残差网络(ResNet)。值得一提的是,残差网络已成为当代人工智能最重要的基础模块之一,几乎是深度网络的标配。下图展示了CNN的典型结构:
2.1 卷积层
卷积层主要负责从输入数据中提取局部特征。与全连接层需要将输入拉平为一维数据不同,卷积层能够完整保留空间位置信息,这一特性在处理图像时极为关键。
2.1.1 卷积计算
卷积层对数据执行的是卷积运算,这种运算本质上与图像处理中的滤波器操作相同。当处理三维数据时,输入数据的通道数必须与卷积核的通道数保持一致。在多通道场景下,计算过程如下:对每个通道分别执行卷积,然后将所有通道的结果相加,得到最终的输出。
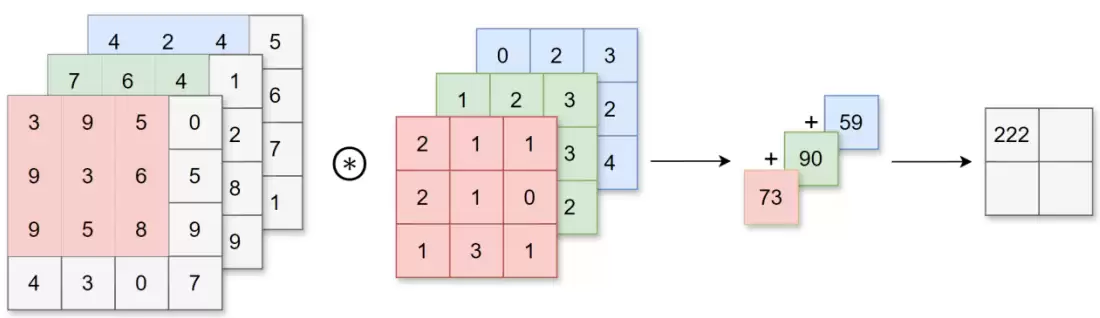
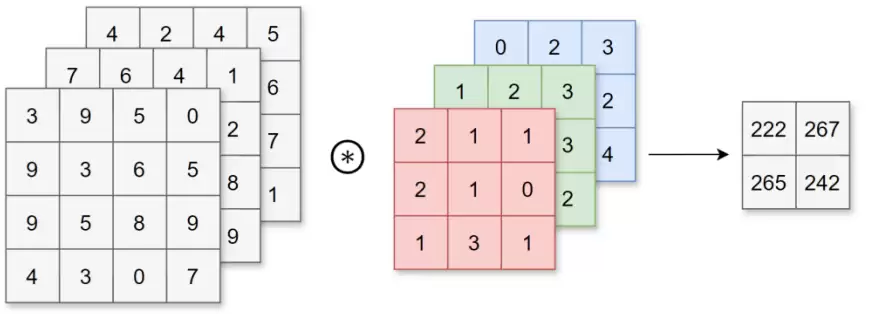
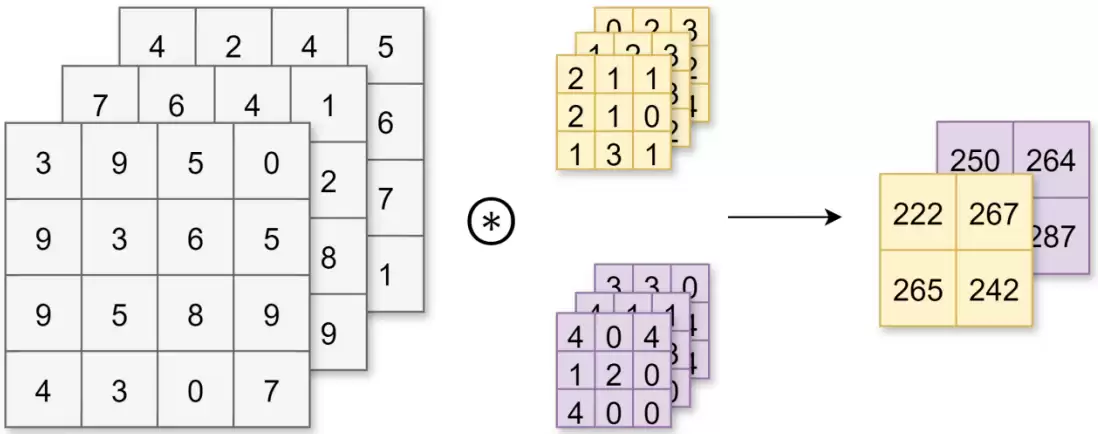
2.2 池化层
池化层的作用是缩小长宽方向上的空间尺寸,相当于对数据进行降维。这样做的好处显而易见:既能缩减模型规模,又能提升计算速度。与卷积层不同,池化层本身无需学习任何参数,而且池化运算按通道独立进行,因此池化后数据的通道数不会改变。池化还有一个有趣的特性——对微小偏差具有很强的鲁棒性。换句话说,只要输入数据没有发生显著变化,池化结果可能完全一致。常见的池化方式包括Max池化(取窗口内的最大值)和Average池化(取窗口内的平均值)。
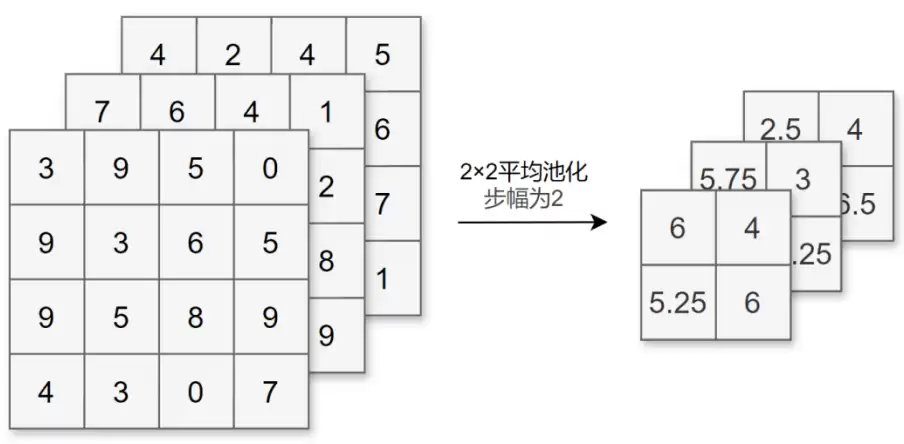
2.3 填充和步幅
在执行卷积或池化之前,通常需要在输入数据的周围填充固定值(通常是0),这称为填充。而卷积核或池化窗口每次移动的间隔则称为步幅。这两个参数直接决定输出特征图的大小。
2.4 残差网络
2015年,微软团队(何恺明等人)提出了残差网络,其网络结构比之前的模型更深。为了应对深度网络中的梯度消失问题,ResNet引入了“残差连接”或“跳跃连接”。效果立竿见影——梯度消失和梯度爆炸问题得到有效控制,网络深度增加的同时,性能反而得到提升。
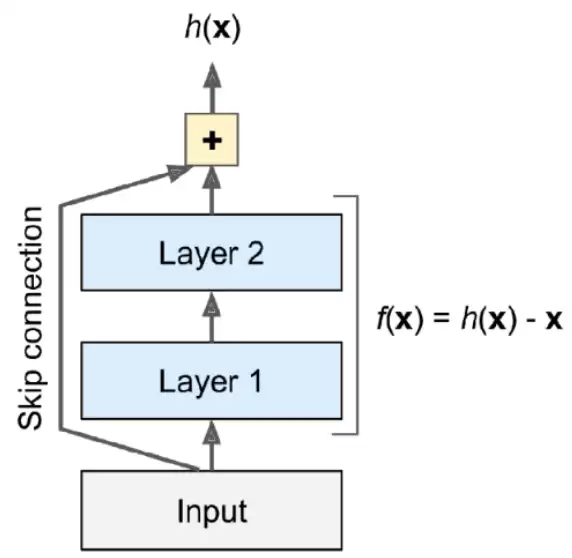
2.5 代码实践:手写数字识别
import time
from pathlib import Path
import torch
import torchvision.transforms as T
from torch import nn, optim, utils
from torch.utils.tensorboard import SummaryWriter
from torchvision.datasets.mnist import MNIST
# 基础配置
ROOT_DIR = Path(__file__).parent.parent
device = 'cuda' if torch.cuda.is_a vailable() else 'cpu'
log_dir = ROOT_DIR / 'ch08_cnn'/'logs'
# 超参数配置
epochs = 10
batch_size = 128
lr = 0.001
# 加载数据集
transform = T.Compose([T.ToTensor()])
train_set = MNIST(
root="./datasets", train=True, download=True, transform=transform
)
test_set = MNIST(
root="./datasets", train=False, download=True, transform=transform
)
train_loader = utils.data.DataLoader(train_set, shuffle=True, batch_size=batch_size)
test_loader = utils.data.DataLoader(test_set, shuffle=False, batch_size=batch_size)
# 初始化模型
model = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.A vgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.Sigmoid(),
nn.A vgPool2d(kernel_size=2, stride=2),
nn.Flatten(),# 拉平
nn.Linear(400, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10),
).to(device=device)
# 初始化损失函数
loss = nn.CrossEntropyLoss()
# 初始化优化器
optimizer = optim.Adam(model.parameters(), lr=lr)
# 开始训练
with SummaryWriter(log_dir=str(log_dir / time.strftime('%Y-%m-%d_%H-%M-%S'))) as writer:
for epoch in range(epochs):
training_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
optimizer.zero_grad()
loss_v = loss(outputs, labels)
loss_v.backward()
optimizer.step()
training_loss += loss_v.item()
writer.add_scalar('loss', training_loss, epoch + 1)
print(
f'Epoch {epoch + 1}/{epochs} loss: {training_loss / len(train_loader):.3f}')
# 开始测试
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'\n预测准确率: {100 * correct // total} %')
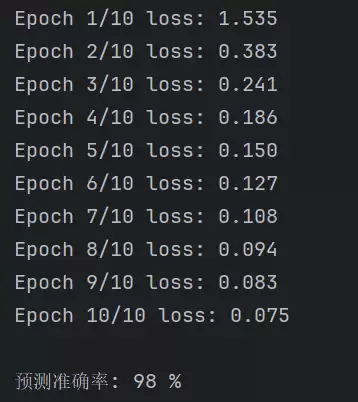
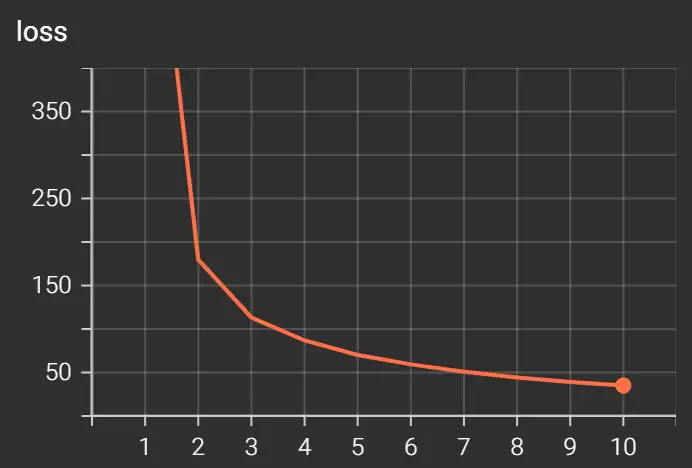
3. Vision Transformer
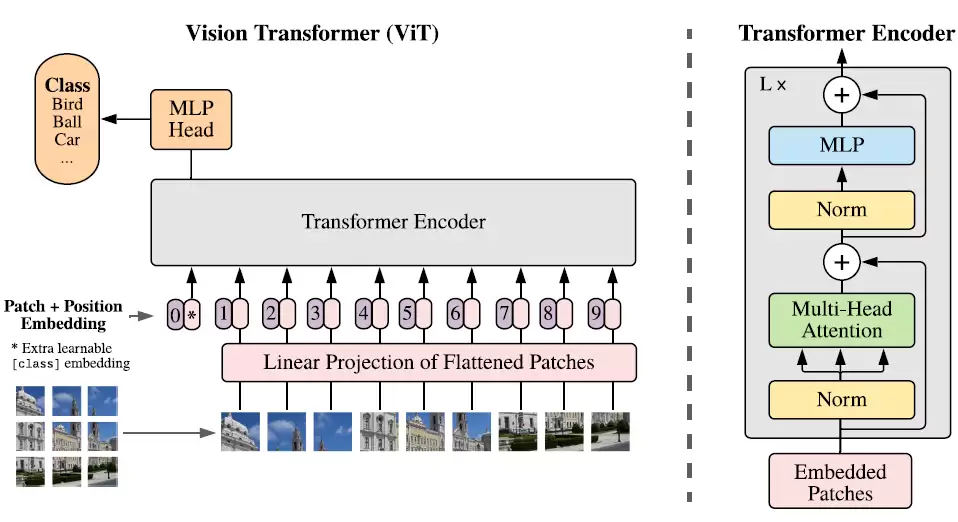
3.1 补丁嵌入
构建Vision Transformer的第一步,是将输入图像拆分成多个小补丁,再将每个补丁转换为线性嵌入序列。在PyTorch中,这一操作可通过Conv2d方法实现。Conv2d接收输入图像,将其切分为补丁,然后输出一个大小为d_model的线性投影。只需将kernel_size和步幅均设为补丁大小,即可保证补丁尺寸正确且互不重叠。
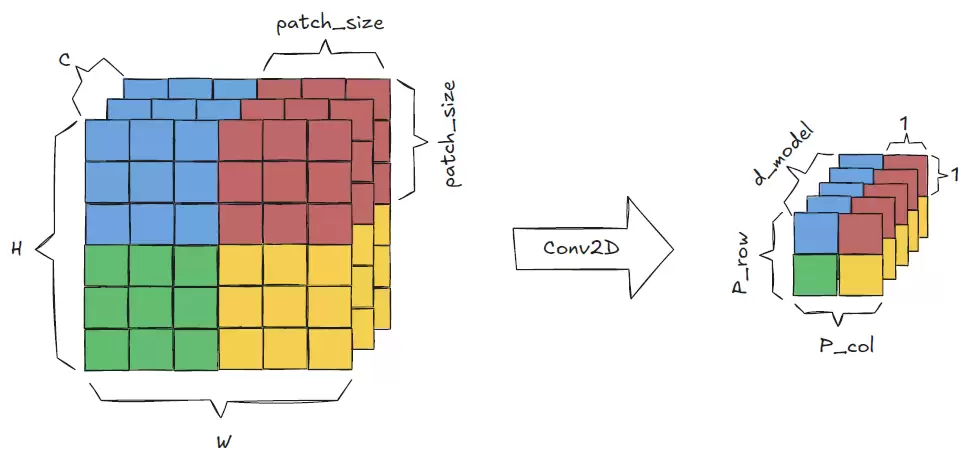
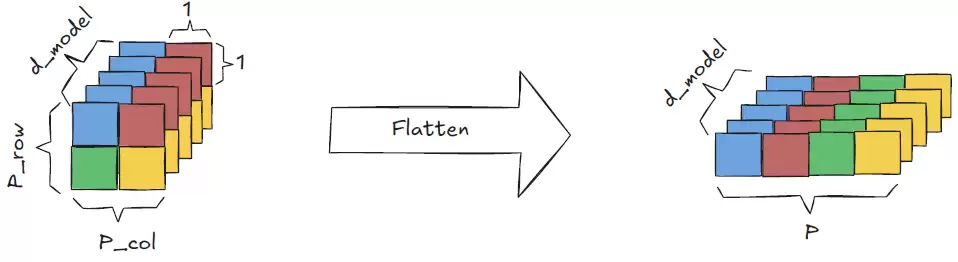
接下来调用flatten方法,将补丁的列和行维度合并为一个补丁维度,得到形状为(B, d_model, P)的张量。
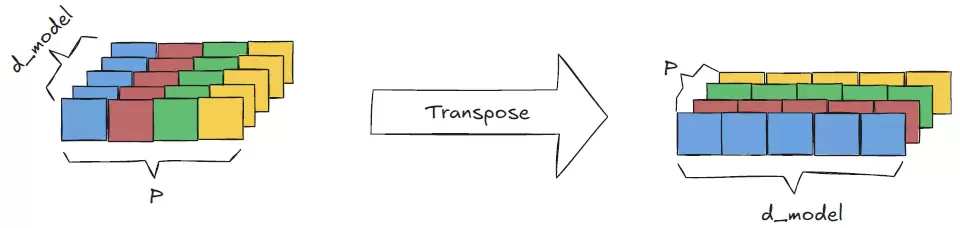
最后使用转置操作交换d_model和补丁维度,得到(B, P, d_model)的形状——这正是模型所需的输入格式。
3.2 位置编码补足补丁嵌入的空间信息
这里存在一个关键问题:补丁嵌入本身不包含空间位置信息。可以想象,将一张图片切成小块并打乱顺序后,模型无法区分每块的原位置。因此,必须借助位置编码来补充这一信息。
3.3 类别对应的Token
这一思路源自BERT——编码器模型的代表。参考BERT处理单句分类任务的方式,我们借用[CLS]特殊标记的输出向量,通过线性层来完成分类任务,例如情感极性判断、语法可接受性判断等。
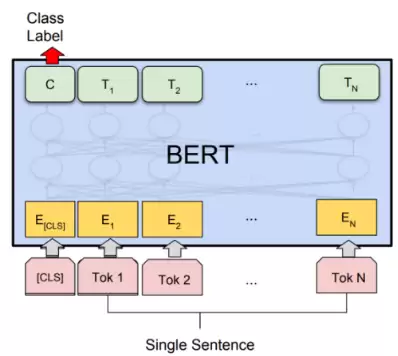
3.4 Transformer编码器
Transformer编码器由两个子层组成:第一层执行多头注意力,第二层是MLP。每个子层都搭配了残差连接和层归一化,这一组合能够有效缓解训练中的梯度消失和收敛困难问题——这对Transformer实现多层堆叠至关重要。
3.5 代码实践:手写数字识别
import torch
import time
import torch.nn as nn
import torchvision.transforms as T
from torch.optim import Adam
from torchvision.datasets.mnist import MNIST
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from pathlib import Path
import numpy as np
class PatchEmbedding(nn.Module):
def __init__(
self,
d_model,# 模型的维度
img_size, # 图片大小
patch_size,# 补丁大小
n_channels# 通道数量
):
super().__init__()
self.d_model = d_model
self.img_size = img_size
self.patch_size = patch_size
self.n_channels = n_channels
self.linear_project = nn.Conv2d(
self.n_channels,# in_channels
self.d_model,# out_channels
kernel_size=self.patch_size,# kernel_size
stride=self.patch_size# stride
)
# B: 批次大小
# C: 通道数量
# H: 图像高度
# W: 图像宽度
# P_col: 补丁的列
# P_row: 补丁的行
def forward(self, x):
# (B, C, H, W) -> (B, d_model, P_col, P_row)
x = self.linear_project(x)
x = x.flatten(2)# (B, d_model, P_col, P_row) -> (B, d_model, P)
x = x.transpose(1, 2)# (B, d_model, P) -> (B, P, d_model)
return x
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super().__init__()
# 类别token
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))
# 创建位置编码
pe = torch.zeros(max_seq_length, d_model)
for pos in range(max_seq_length):
for i in range(d_model):
if i % 2 == 0:
pe[pos][i] = np.sin(pos/(10000 ** (i/d_model)))
else:
pe[pos][i] = np.cos(pos/(10000 ** ((i-1)/d_model)))
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
# 为批次中的每张图片分配一个类别token
tokens_batch = self.cls_token.expand(x.size()[0], -1, -1)
# 将类别token添加到每个图像的补丁嵌入数组的开头
x = torch.cat((tokens_batch, x), dim=1)
# 将位置编码添加到嵌入中
x = x + self.pe
return x
class AttentionHead(nn.Module):
def __init__(self, d_model, head_size):
super().__init__()
self.head_size = head_size
self.query = nn.Linear(d_model, head_size)
self.key = nn.Linear(d_model, head_size)
self.value = nn.Linear(d_model, head_size)
def forward(self, x):
# 计算Q, K, V
Q = self.query(x)
K = self.key(x)
V = self.value(x)
# Q和K的点积
attention = Q @ K.transpose(-2, -1)
# 缩放
attention = attention / (self.head_size ** 0.5)
attention = torch.softmax(attention, dim=-1)
attention = attention @ V
return attention
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.head_size = d_model // n_heads
self.W_o = nn.Linear(d_model, d_model)
self.heads = nn.ModuleList([
AttentionHead(d_model, self.head_size) for _ in range(n_heads)
])
def forward(self, x):
# 拼接多个注意力头
out = torch.cat([head(x) for head in self.heads], dim=-1)
out = self.W_o(out)
return out
class TransformerEncoder(nn.Module):
def __init__(self, d_model, n_heads, r_mlp=4):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
# 层归一化
self.ln1 = nn.LayerNorm(d_model)
# 多头注意力
self.mha = MultiHeadAttention(d_model, n_heads)
# 层归一化
self.ln2 = nn.LayerNorm(d_model)
# MLP
self.mlp = nn.Sequential(
nn.Linear(d_model, d_model*r_mlp),
nn.GELU(),
nn.Linear(d_model*r_mlp, d_model)
)
def forward(self, x):
# 第一次层归一化之后的残差
out = x + self.mha(self.ln1(x))
# 第二次层归一化之后的残差
out = out + self.mlp(self.ln2(out))
return out
class VisionTransformer(nn.Module):
def __init__(
self,
d_model,
n_classes,
img_size,
patch_size,
n_channels,
n_heads,
n_layers
):
super().__init__()
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
"img_size 必须能被 patch_size 整除"
assert d_model % n_heads == 0, \
"d_model 必须能被 n_heads 整除"
self.d_model = d_model# 模型维度,嵌入的维度(宽度)
self.n_classes = n_classes# 类别的数量
self.img_size = img_size# 图片大小
self.patch_size = patch_size# 补丁大小
self.n_channels = n_channels# 通道数
self.n_heads = n_heads# 注意力头的数量
# 补丁的数量 = (32x32) // (4x4)
self.n_patches = (self.img_size[0] * self.img_size[1]) // (self.patch_size[0] * self.patch_size[1])
# 序列的长度 = 1(分类token) + 补丁的数量
self.max_seq_length = self.n_patches + 1
# 补丁嵌入
self.patch_embedding = PatchEmbedding(
self.d_model,
self.img_size,
self.patch_size,
self.n_channels
)
# 位置编码
self.positional_encoding = PositionalEncoding(
self.d_model,
self.max_seq_length
)
self.transformer_encoder = nn.Sequential(*[
TransformerEncoder(self.d_model, self.n_heads)
for _ in range(n_layers)
])
# 用于分类的MLP
self.classifier = nn.Sequential(
nn.Linear(self.d_model, self.n_classes),
nn.Softmax(dim=-1)
)
def forward(self, images):
# 将图片转换成补丁的嵌入(embedding)
x = self.patch_embedding(images)
# 添加位置编码
x = self.positional_encoding(x)
# 编码
x = self.transformer_encoder(x)
# 分类的线性层
x = self.classifier(x[:, 0])
return x
# 基础配置
ROOT_DIR = Path(__file__).parent.parent
device = 'cuda' if torch.cuda.is_a vailable() else 'cpu'
log_dir = ROOT_DIR / 'logs'
print(log_dir)
d_model = 9# 嵌入的维度9
n_classes = 10# 类别数量为10
img_size = (32, 32)# 图片大小为32x32
patch_size = (16, 16)# 补丁的大小是16x16
n_channels = 1# 灰度图片通道数量为1
n_heads = 3# 3个注意力头
n_layers = 3# 3层编码器
batch_size = 128# 每个批次128张图片
epochs = 10# 训练5个epoch
alpha = 0.005# 学习率5e-3
transform = T.Compose([
T.Resize(img_size),# 28x28 --> 32x32
T.ToTensor()# 转换成torch.tensor
])
train_set = MNIST(
root="./datasets", train=True, download=True, transform=transform
)
test_set = MNIST(
root="./datasets", train=False, download=True, transform=transform
)
train_loader = DataLoader(train_set, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_set, shuffle=False, batch_size=batch_size)
device = torch.device("cuda")
ViT = VisionTransformer(
d_model,
n_classes,
img_size,
patch_size,
n_channels,
n_heads,
n_layers
).to(device)
optimizer = Adam(ViT.parameters(), lr=alpha)
criterion = nn.CrossEntropyLoss()
with SummaryWriter(log_dir=str(log_dir / time.strftime('%Y-%m-%d_%H-%M-%S'))) as writer:
for epoch in range(epochs):
training_loss = 0.0
for i, data in enumerate(train_loader, 0):
# 取出图像和对应的标签
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# 前向传播
outputs = ViT(inputs)
# 交叉熵损失
loss = criterion(outputs, labels)
# 求导数
loss.backward()
# 梯度下降
optimizer.step()
training_loss += loss.item()
writer.add_scalar('loss', training_loss, epoch + 1)
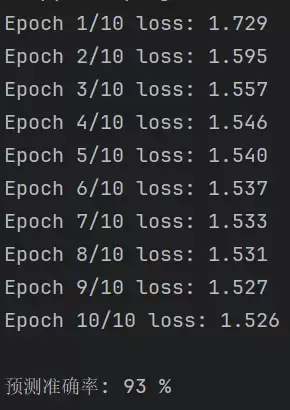
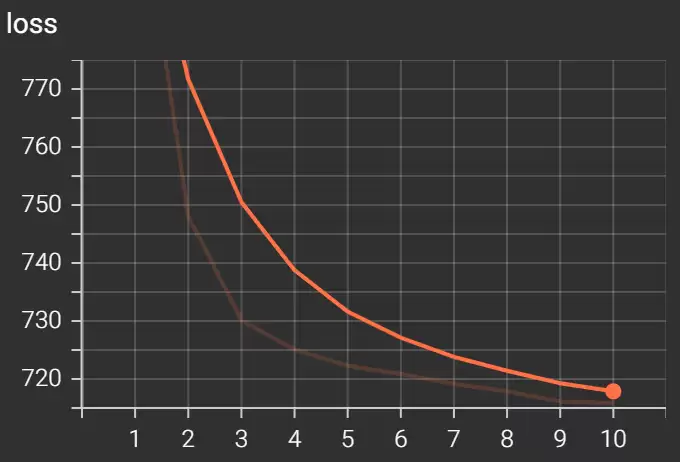
print(
f'Epoch {epoch + 1}/{epochs} loss: {training_loss / len(train_loader):.3f}')
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = ViT(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'\n预测准确率: {100 * correct // total} %')
4. 总结
Vision Transformer的核心启示在于:只要能够将文本、图像、音频等不同类型的数据均处理为合适的Embedding,Transformer架构就能同时理解并融合这些信息。这意味着什么?意味着在处理多模态任务时,我们不再需要为每种数据专门设计独特的网络结构——一个统一的框架,就有望处理所有输入。这才是其最令人振奋之处。
```
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

短视频批量制作产线搭建:素材处理到矩阵分发实践
短视频制作从单条走向批量之后,许多团队会发现,真正拖慢进度的往往不是剪辑技术本身,而是流程难以复用。每次制作都要重新搜集素材,同一主题想要输出多个版本却必须从零开始,字幕和配音反复操作,成片之后还得逐个平台手动上传分发。这些重复性工作累积起来,整体效率自然难以提升。 在实际业务中,我们构建了一条短视

Claude 4.8发布,模型迭代加速背后原因分析
昨天凌晨,Anthropic 正式发布了 Claude Opus 4 8。 说它强,到底强在哪?官方案例就很有冲击力:项目 Bun,11 天时间,75 万行代码从 Zig 迁移到了 Rust,测试通过率高达 99 8%。 但这组数字背后的真正含义,并不仅仅是模型变强了——而是 AI 的工作方式,正在

代购网站架构演进从个人操作到系统化支撑
刚开始做代购那会儿,代购网站开发基本靠“人肉运维”。客户下单→手动去1688下单→Excel记库存→微信收款→手写快递单。日单量二三十的时候,这套流程勉强跑得动。直到有一天,一个客户下了50单,熬到凌晨三点还没对完账,第二天发现汇率从6 8涨到了6 9,那批货直接亏了将近两千块。 那是我第一次意识到

Bub作者专访 开发好记性懂人Agent的核心方法
Bub 深度对话:一个轻量级 AI Agent 框架的诞生与演进 上周我这边刚发了一篇用 Bub 和飞书搭建群聊机器人的实践,没成想这篇东西居然帮我们搭上了 Bub 开发团队的线。趁着这个机会,我和三位核心开发者聊了近两个小时,从项目起源聊到技术细节,从用户场景聊到未来规划。如果你对 Agent

AI开发代码高效优化策略
AI Dev Codes是什么 如果你还在为“想快速搭个网页但不懂代码”这件事头疼,那AI Dev Codes的诞生,多少能缓解一下这种焦虑。简单说,它就是一个由开发者打造的AI工具,核心能力是通过对话帮你生成定制化、交互式的网页。从底层来看,它拿的是OpenAI的ChatGPT模型作为文本生成引擎








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
