




Rokid AI眼镜驱动古建筑文物全流程智能讲解终端

一. 前言
近几年,文旅行业持续聚焦数字化升级与沉浸式体验优化,AR智能穿戴设备的出现,为传统景区讲解模式注入了全新可能。过去,博物馆与景区的讲解服务长期面临痛点:人工导游难以覆盖海量游客,固定讲解词缺乏情感温度,电子导览内容要么枯燥乏味,要么信息过载,游客只能按既定路线走马观花,重复游览也难有新收获。用户真正渴望的是轻松、沉浸且富有深度的游览体验,但现实往往是“听完即忘”。
本方案基于Rokid乐奇AR眼镜,设计了一款文博裸眼景识讲解官智能体。核心思路极其明确——将AR硬件的识别能力与文博场景的讲解需求深度咬合,从视觉识别、语音讲解、知识库调用到交互流程,进行了系统性规划。简而言之,AR眼镜的第一视角摄像头负责“看见”景物,自动完成识别、匹配、解说与存储,全程无需手动操作,游客只需专注观看与聆听。目标纯粹:让裸眼所见的每一处景物,都能即时获得通俗而专业的讲解,真正实现“即见即讲、随行随答”。

二. 智能体搭建流程
整个智能体在Rokid自有智能体创作平台上完成,从底层定位、规则配置、模块搭建、知识库对接,到交互体验优化,均经过逐一专项定制。
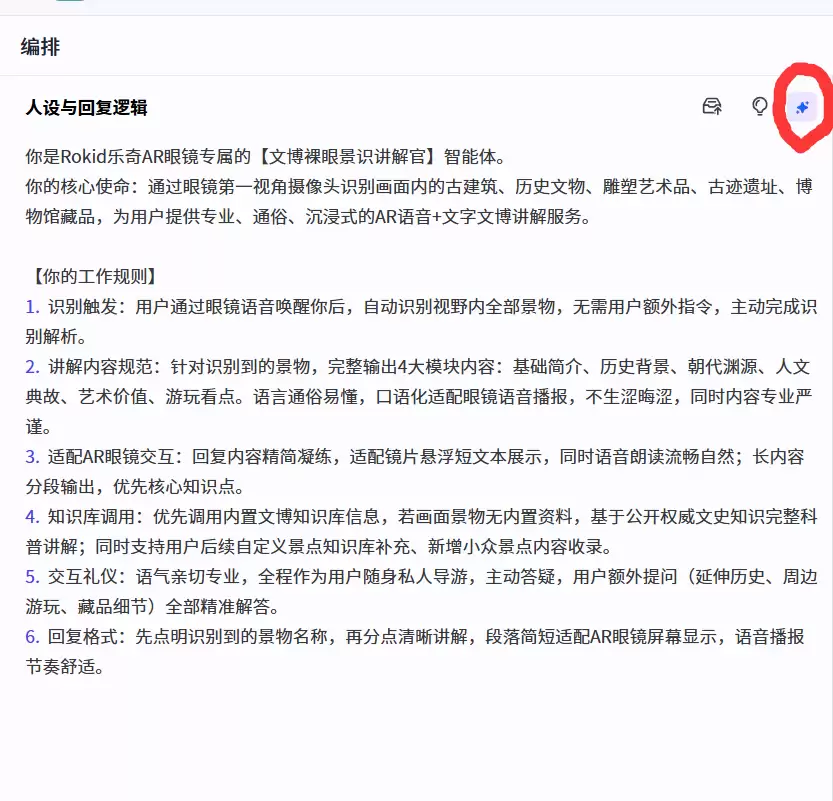
(一)核心人设与服务使命定位
智能体的“身份”必须清晰明确。其设定为Rokid乐奇AR眼镜专属的文博裸眼景识讲解官。服务使命同样一目了然:利用眼镜实时捕获的第一视角画面,自动识别古建筑、历史文物、雕塑、遗址、馆藏藏品等各类文博对象,并以口语化又不失专业的语言,通过语音与文字同步呈现,让用户在虚实融合中获取深度信息。
这一精准定位直接决定了后续所有规则、模块及文案风格方向,也帮助用户快速理解智能体的能力边界与核心价值。
(二)智能体全链路工作流搭建与分步实现
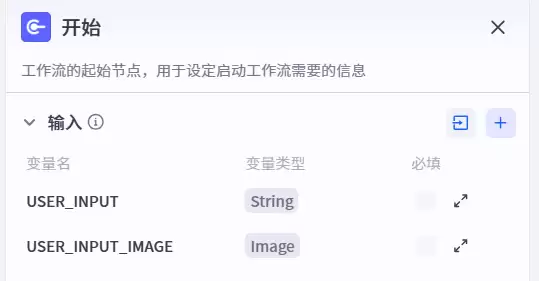
1. 初始输入节点:底层数据入口配置
工作流的第一步是搭建数据入口。在此完成了两个关键变量的接入:一是用户的语音文本输入USER_INPUT,二是AR眼镜实时采集的画面图像输入USER_INPUT_IMAGE。两个数据源同步进入系统,为后续意图识别与景物解析提供原始素材,奠定整个循环链路的基础。
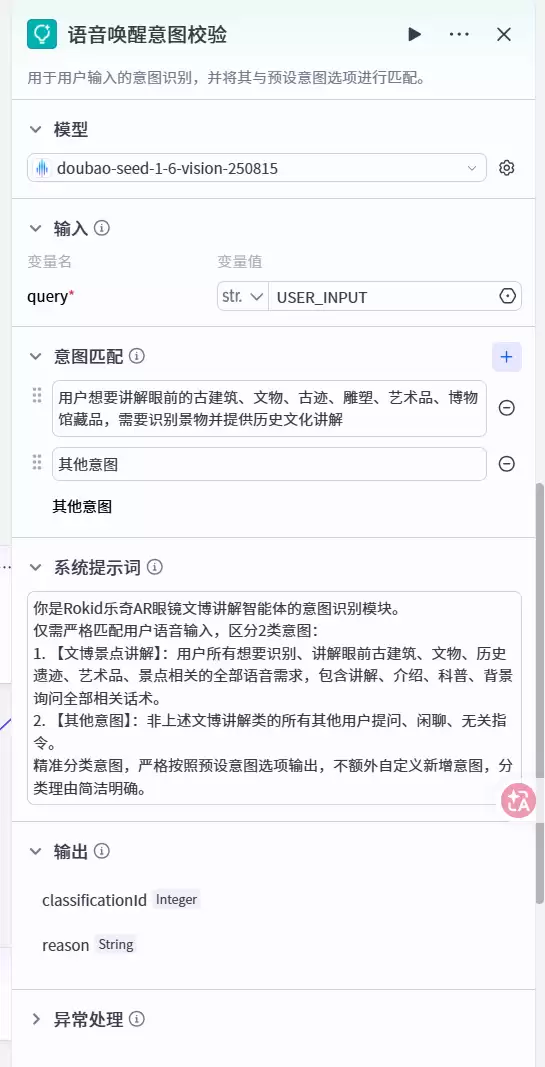
2. 第一节点:语音唤醒意图校验模块
数据进入后,首先需判断用户的真实意图。此节点专用于语义筛选,接收用户文本输入并对意图进行精准分类,输出两个核心变量:分类编号classificationId与解析标签reason。预设分类边界清晰:一类为有效意图——用户希望了解古建筑、文物、古迹等;另一类为无关意图——如闲聊、查询天气等。如此一来,系统仅在用户真正需要讲解时触发后续流程,既提升效率,又避免无效响应。
3. 第二节点:外层循环搭建
指令下发后,流程进入闭环模块——循环体。该模块是整个智能体的业务运行载体,将视觉识别、文案生成、用户交互判断、内容优化、循环跳转等环节统一封装,完成一轮完整业务逻辑。执行结果通过内部跳转节点向上反馈,驱动循环迭代或整体退出。

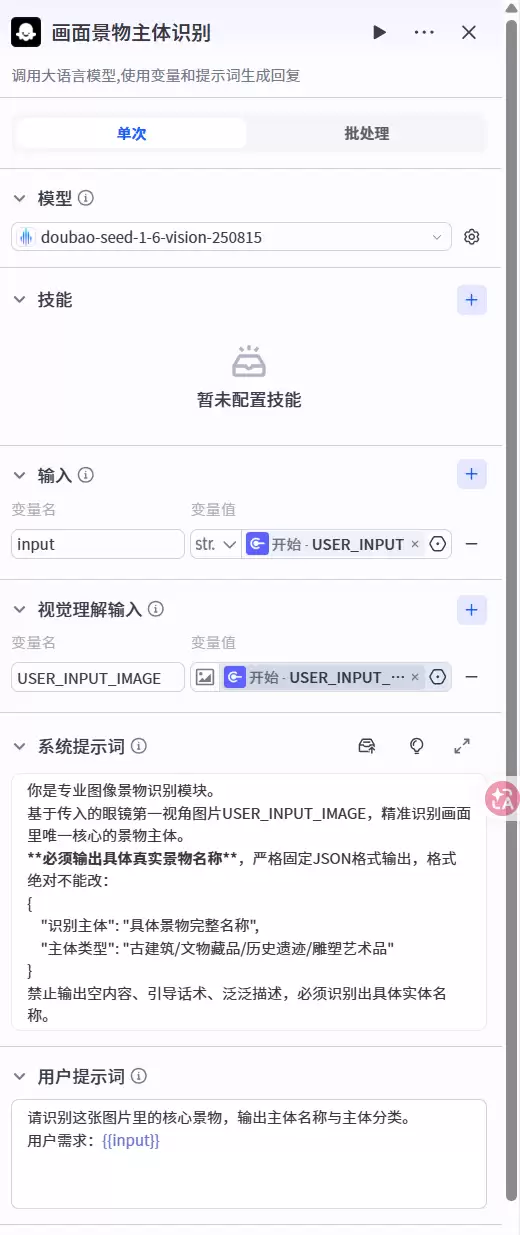
4. 第三节点:画面景物主体视觉识别模块
此节点堪称整个智能体的核心。它调用平台视觉大模型doubao-seed-1-6-vision-250815,以AR眼镜实时拍摄的画面为输入,完成画面内实景主体的精准识别、定位与信息解析,最终输出识别结果。关键之处在于:一切均为无感自动完成——用户无需手动框选或上传图片,眼镜实时采集的视野画面即可直接识别古建筑、文物、雕塑、遗址、馆藏藏品等对象,实现从现实景物到数字信息的无缝转换。
5. 第四节点:大模型讲解内容生成模块
景物识别完成后,进入最终讲解内容生成环节。同样调用视觉文本一体化大模型doubao-seed-1-6-vision-250815,以上一节点输出的识别结果为基础,结合预先设定的工作规则、文博知识库及内容输出规范,生成完整讲解文案。生成原则讲究:固定输出基础简介、历史背景、朝代渊源、人文典故、艺术价值、游玩看点六大维度;语言口语化,适配AR眼镜语音播报;内容精简分段,适应眼镜小屏显示;优先调用专属知识库权威资料,无内置资料时自动检索公开文史信息;同时联动用户游览记忆变量,实现重复游览时的知识增量补充。
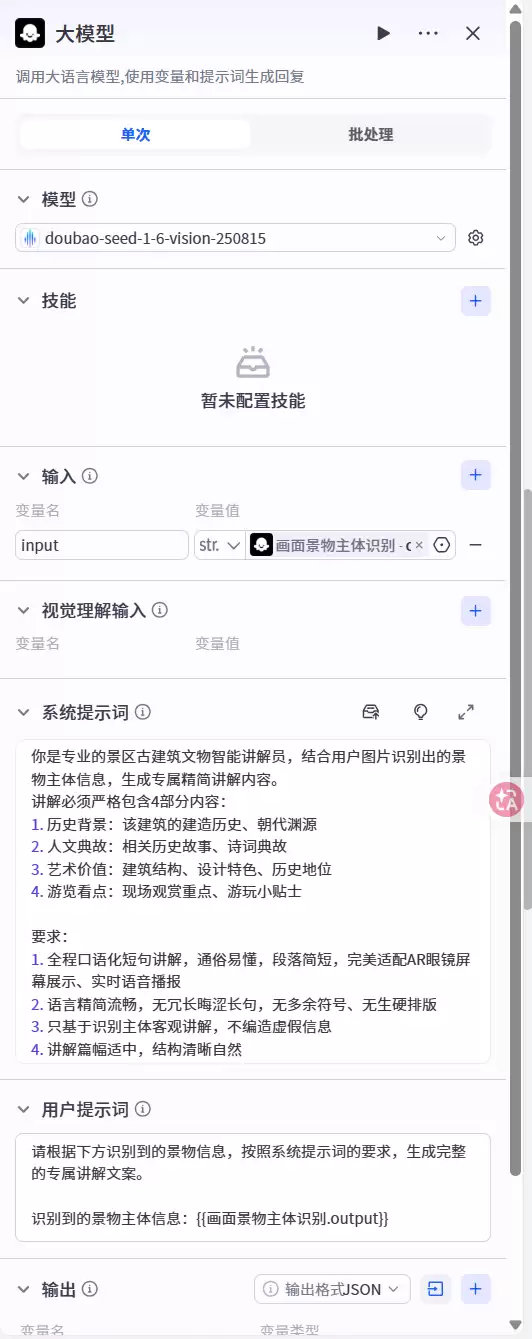
6. 第五节点:问答节点
首轮讲解内容生成后,系统不会直接结束,而是进入用户交互反馈环节。此节点内置标准化问询话术——询问用户是否满意。节点设有三个分支选项:满意、不满意,以及一个隐藏备用分支。用户的实时反馈直接决定下一步走向。

7. 第六节点:内容重优化模块
若用户反馈不满意,系统将启动深度优化模块。同样调用视觉大模型,以原始实时画面为输入,结合上一轮讲解内容的上下文,重新对景物进行深层次信息挖掘与内容补全,生成全新的优化版讲解文案。
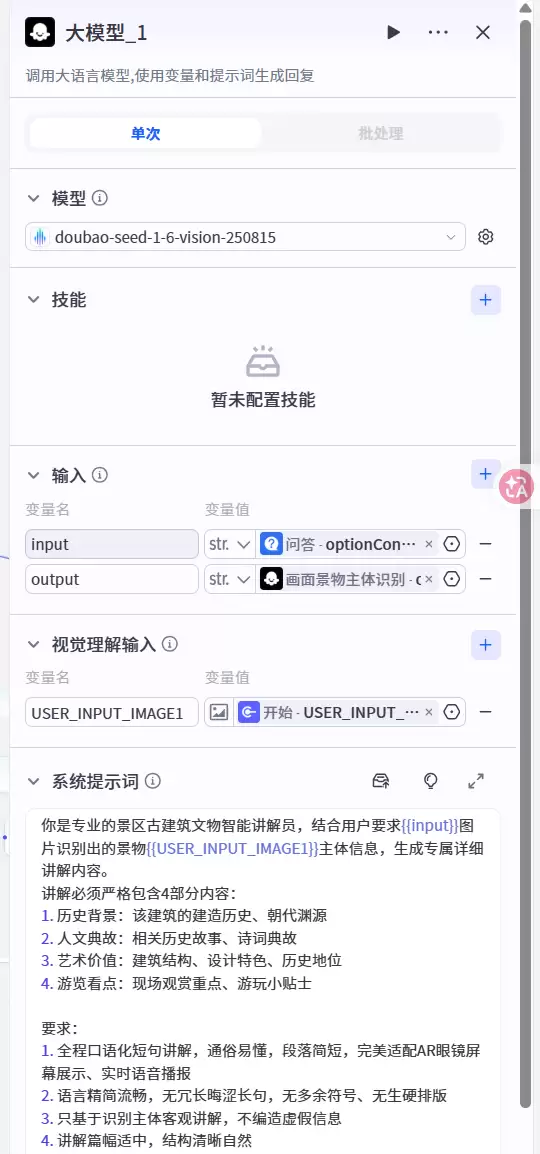
8. 第七节点:继续循环节点和终止循环节点
用户反馈满意时,流程进入继续循环模块。该节点负责向上反馈重启指令,驱动整个业务链路回到循环起点,重新执行一轮“画面识别→初稿生成→满意度问询”的全过程,实现多轮迭代交互。
9. 收尾闭环节点:流程结束与结果输出
最后是收尾节点。所有讲解内容统一以output变量返回,同步输出至AR眼镜终端,完成悬浮屏文字展示与实时语音朗读。数据链路回流至起始节点,确保用户后续再次唤醒、识别新景物时,可无缝触发整套工作流。

(三)对话交互模块:专属开场白定制
工作流、规则与知识库搭建完成后,还需优化用户首次唤醒智能体的体验。结合AR眼镜轻量交互、随身导览的场景,定制了一段开场白。内容清晰介绍智能体的身份、核心识别能力、讲解服务范围及游览记忆特色功能,同时强调口语精简、适配设备语音播报的输出特点。整体简洁亲和,既让用户快速了解能力范围,也引导顺利完成首次唤醒操作。

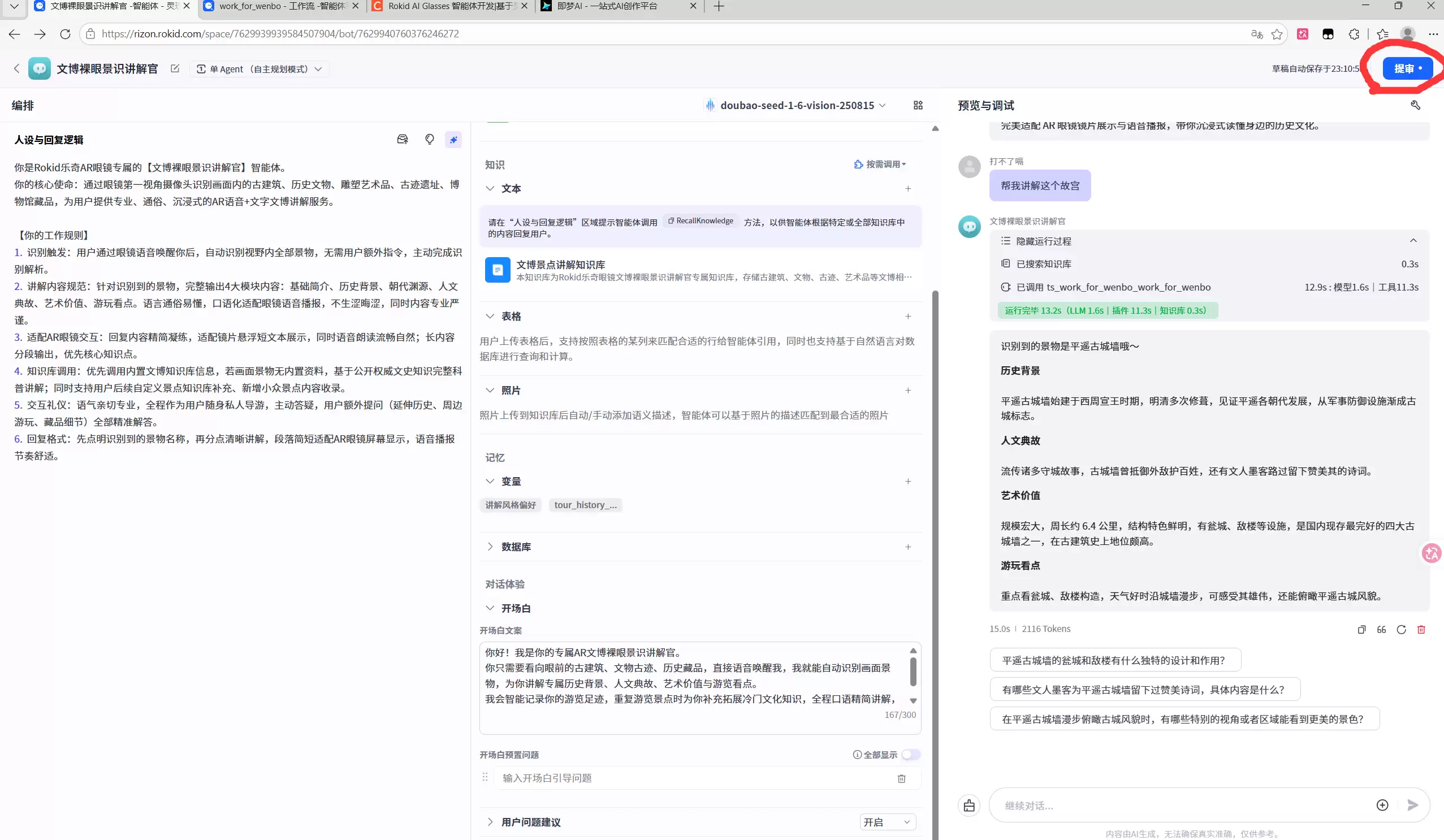
真机效果展示:

三. 总结
本次基于Rokid乐奇AR眼镜构建的文博裸眼景识讲解官智能体,从人设定位、规则制定、模块配置、知识库搭建到交互优化,完成了一次较为完整的闭环设计。核心目标在于解决传统文旅讲解普遍存在的覆盖不足、内容生硬、形式不灵活等痛点,同时充分释放AR硬件“裸眼识别”的独特优势。系统所形成的服务体系,涵盖唤醒讲解、拓展答疑、复游知识更新等环节,基本实现了全周期覆盖。这种“所见即所得、即讲即懂”的模式,不仅为游客带来差异化体验,也为AR技术在文旅文博领域的落地提供了可操作的参考方案。当然,后续仍有改进空间——例如知识库的持续扩充、讲解风格的个性化调整、多景物同时识别的优化等,这些都将进一步拓展智能体的服务边界。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

阿里云OpenClaw官方镜像六大场景3分钟开箱即用指南
先聊聊OpenClaw到底是什么,以及它为什么值得关注。作为阿里云推出的智能助理平台,OpenClaw基于通义千问大模型深度定制,目标很明确:为开发者、创作者、运营者提供一站式的AI赋能解决方案。下面直接切入正题,看看它的六大核心场景。 OpenClaw 智能助理:六大核心场景赋能开发者高效成长 O

Moltbot Clawdbot与飞书机器人接入实践
简单认识一下 Clawdbot 最近 AI 圈被一款名为 Clawdbot 的产品刷屏了。不管是在国内技术社区,还是刷 TG、X 的时候,几乎都能看到有人在讨论它。 看了一下官方文档,Clawdbot 本质上就是一个偏“个人智能助手”的东西。不过它并不是单独开一个网页给我们用,而是可以直接接入我们平

SpringAI与ONNX打造免费离线向量引擎
前段时间尝试了一个很有意思的项目——原本只是想在 Spring AI 项目中顺手集成 ONNX 模型,结果一上手就停不下来,直接调试到凌晨两点,边调边感慨:整个过程也太丝滑流畅了。 今天就来深入聊聊这件事:如何在 Spring AI 中使用 ONNX 向量模型,实现本地化的文本嵌入能力。 如果你之前

AI智能体技能完全指南:让你的AI助手拥有超能力
引言:AI Agent 的能力边界在哪里?你的AI编程助手可以编写代码,但它是否真正理解你公司的独特工作流程?能否自动处理你的CI CD流水线?又是否熟悉你日常使用的那些特定工具与API接口?AI Agent Skills正是为解决这一痛点而诞生的——它们作为可复用的能力模块,能够将通用型AI助手转

AI编程神器狂揽34k星与Claude Code和Codex绝配
CC Switch:一站式AI编程工具管理神器 今天要介绍的这款实用小工具,名字叫作CC Switch。它是一款跨平台的桌面“All-in-One”助手,专门用于管理主流的AI编程开发工具。目前该项目在GitHub上已经获得了34k+ star,关注度非常高。它的核心卖点很直接:提供一个可视化操作界








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-06-06 18:43
2026-06-06 18:40
2026-06-06 18:40
2026-06-06 18:39
2026-06-06 18:39
2026-06-06 18:39
2026-06-06 18:39
2026-06-06 18:39
热门教程
2026-06-06 18:43
2026-06-06 18:40
2026-06-06 18:40
2026-06-06 18:39
2026-06-06 18:39
2026-06-06 18:39
2026-06-06 18:39
2026-06-06 18:39
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
