




机器学习如何从数据中学习规则的全过程

让我们从一个最直观的场景入手——传统编程究竟是如何运作的。
一、传统编程:将规则固化在代码中
在学习之前,我们不妨先回顾一下传统编程的运行方式。
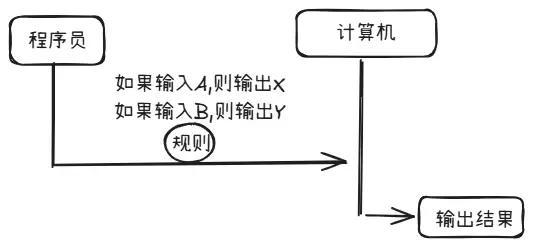
这实际上就是硬编码——程序员把每一条规则逐一写死,机器则严格按部就班地执行。
但问题是:当规则变得极其复杂,复杂到连程序员自己也难以清晰描述时,该怎么办?
举个例子,让你来描述“鸟”的特征:
- 鸟有两条腿——可鸡也有两条腿
- 鸟嘴巴是尖的——鸡也是尖的
- 鸟有两翅膀——鸡也有两翅膀
如果试图用规则一直穷举下去,你会发现永远也列不完。那么,为什么我们能一眼认出鸟?因为我们见过足够多的样本,依靠的是直觉,而非死板的规则。
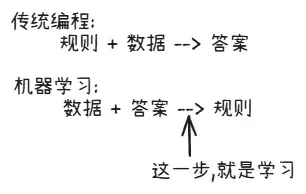
因此,机器学习的核心思想便逐渐清晰起来:让机器自行从数据中总结规律。
一张图就能说清楚两者的区别:
二、监督学习:从数据中学习规律
机器学习又细分出多种类型,其中最常见的就是监督学习。
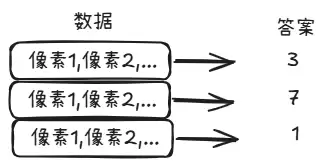
单纯讲概念可能有点抽象,下面用一张图来辅助理解:
算法会反复查看数据以及对应的正确标签,不断调整自身的内部参数,直到对绝大多数样本都能给出正确预测。这个过程被称为迭代。
每次预测错误就进行微调,这叫做最小化误差。
至此,整个流程就一目了然了:
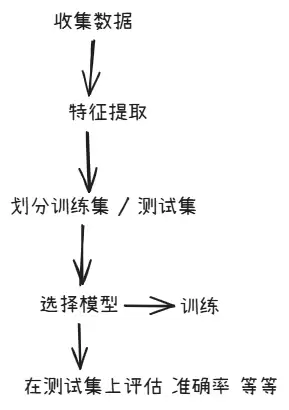
那么,机器究竟如何知道自己的预测错了,以及应该往哪个方向调整呢?
首先,正确答案一开始就已经存放在数据中——训练时,机器会将自己的预测结果与正确答案进行比对。
其次,遇到误差后的处理步骤如下:
- 计算当前的误差
- 计算误差对每个参数的斜率
- 朝着正确答案的方向微调参数
- 重复上述过程,直到答案正确为止
这个步骤叫做梯度下降。
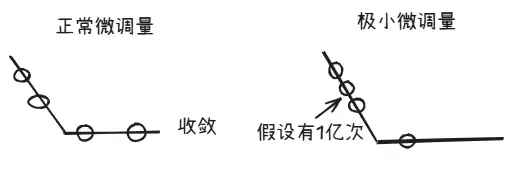
为什么每次都必须微调?因为调整幅度过大的话,很可能直接越过正确答案。
那如果每次调整幅度特别特别小,模型最终能训练好吗?理论上可行,但这会导致训练时间、算力、电力等资源消耗急剧增加,甚至可能永远无法训练完毕。
三、SVM:寻找分类边界
假设现在需要你将两类数据分开:
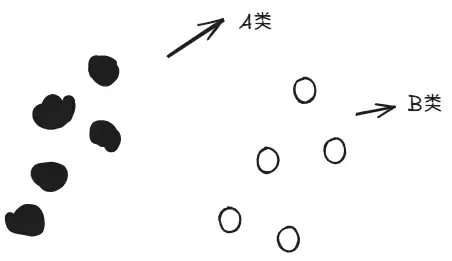
你需要画一条线,将两类数据区分开来。问题在于,能够分开的直线有无数条,怎样才能选出最好的一条?
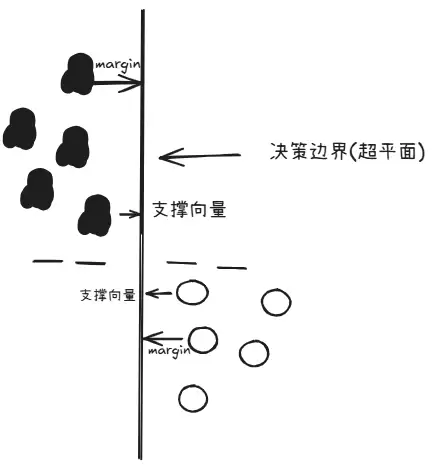
简单来说:你需要找到一条距离两边大致相等的直线。
- Margin:间距,也叫缓冲带
- 支撑向量:位于缓冲带边缘的那些数据点,决策边界的位置完全由这几个点决定
那么,如果遇到下面这种情况——两类数据混在一起,根本画不出一条直线,该怎么办?
*。 *。 *。 *。 *。*。 *。 *
四、核函数:将不可分问题升维解决
核函数正是专门用来解决这个问题的——它将数据映射到更高维度的空间。
一维困境:

用二维解决:
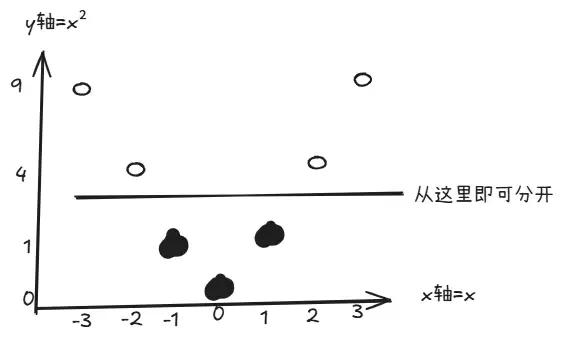
如果在二维中仍然无法分开,那就引入三维来解决。以上述二维例子为例,将 * 的 z 轴抬高,一下子就分开了。
五、交互模式与 Anaconda
先说说目前使用的工具——Python 交互模式。为什么偏偏是 Python?
在2000年之前,数据分析主要依赖 Matlab 和 R,转折点发生在2000年前后。
对比一下之前常规编程的方式:
常规编程:写完一个文件(可能100行代码)→ 运行(一次性)→ 查看结果是否正确。如果出错,根本不知道是哪一行出了问题,必须重新运行。
而交互模式则完全不同:
每输入一行,立刻就能看到执行结果,然后再继续输入下一行
>>> x = 5
>>> x * 3
15
>>>三个非常实用的特性:
- 输入变量名直接能看到对应的值,不需要使用 print()
- 可以逐行调试,随时检查中间结果
- 上下键能够调出历史命令
Anaconda:解决版本冲突
Anaconda 的作用简单来说,就是解决不同项目之间的版本冲突,让每个环境相互独立,互不干扰。
Anaconda
环境A(Python 3.8 sklearn 0.24)← 项目A用这个
环境B(Python 3.11 sklearn 1.3)← 项目B用这个
环境C(Python 3.9 tensorflow)← 深度学习用这个六、数据集从哪里来
一直在讨论数据集,那数据集究竟是如何产生的?数据长什么样?
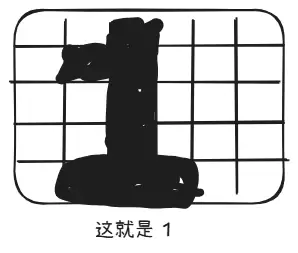
1990年,NIST 收集了大量手写数据用于邮政编码识别——邮局需要机器自动读取信封上的数字。我们现在使用的 digits 数据集就是它的精简版:1797张图,每张 8×8 像素。
一张 8×8 的手写“0”,数值从0到16,0代表白色,16代表黑色。
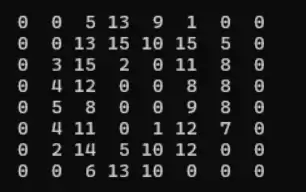
把它画出来就是这样的:

数据的结构:
使用 train_test_split() 可以自动完成训练集和测试集的切分。
为什么要切分训练集和测试集?
训练集好比练习题,测试集则是正式的考试。如果你拿测试集来训练,就相当于提前把考卷做了很多遍再去参加考试——这不叫学会,而是背答案。在机器学习中,这种“背答案”的现象被称为过拟合。
那么问题来了,train_test_split() 切分时,是随机切还是顺序切?
这里补充一个重要知识点:无论是随机切还是顺序切,每一张图都不会重复出现,也就是说训练集中不会包含测试集的样本。
如果按顺序切,假设数据集是 [1,2,3,4,5,6,7,8,9,10] 这样排列的,那么只训练前面的1~8,后面的9和10永远不会被抽到。测试时模型完全没见过9和10,所以测试分数会比较低。
而按照随机切分,最终切出来的顺序可能是 [1,3,5,7,9,2,4,6,8,10],这样模型就能接触到所有类型的数据,测试分数才具有意义。
reshape:将一维数据还原为二维图像
训练之前,我们需要先亲自确认一下:标签的答案和图像是否真的对应得上。
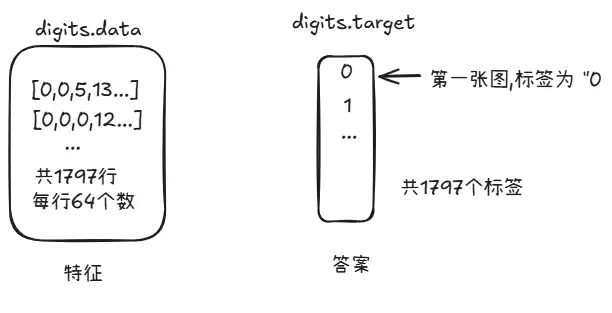
机器存储数据的方式是:
digits.data[0] = [0,0,5,13 ...] 共64个数但这是一维的,而图像是二维的——一维数组我们无法直观判断数字长什么样。这时就需要 reshape。
reshape(8,8) 之后:
第一行: [0,0,5 ... ,0] 共八个数
...
第八行: [0,0,6 ... ,0] 8×8 = 64然后用 imshow() 将数字转换为颜色:0→白,8→灰,16→黑。
用代码展示一下:
// 选索引
index = 100
// 取出数据
image = digits.data[100]
label = digits.target[100]
// 折叠、展示
image_2d = image.reshape(8,8)
plt.imshow(image_2d)
plt.title(f"标签:{label}")
plt.show()而且不能只看一张,要多看几张。这一步叫做探索性数据分析(EDA),目的是提前预判模型可能在哪里出错。
训练流程
总结一下上面的流程:
第一步:导入工具
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score- load_digits → 数据集
- train_test_split → 切分工具
- SVC → SVM分类工具
- accuracy_score → 评分工具
第二步:加载数据并切分
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(
digits.data, digits.target)切分后:
- X_train:1300张图
- y_train:1300个对应标签
- X_test:450张图
- y_test:450个对应标签
第三步:创建模型并训练
model = SVC()
model.fit(X_train, y_train)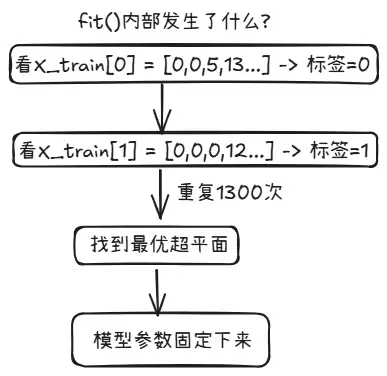
第四步:预测并评估
y_pred = model.predict(X_test)
print(accuracy_score(y_test, y_pred))predict() 做的事:经过 SVM 决策函数,输出结果。
输入:[0,0,4,5,9...] 一张没见过的图
经过SVM决策函数
输出:"1"accuracy_score 用来判断准确率:
y_pred = [1,2,3,4,5,...] 模型猜的
y_test = [1,2,3,4,6,...] 正确答案
准确率 = 猜对的数量 / 总数 = 4 / 5 ≈ 0.8上面的流程用一张图表示就是:
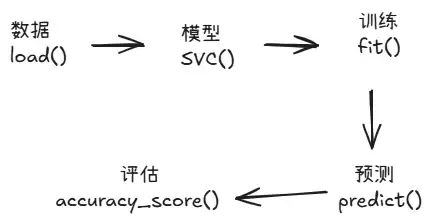
这也是监督学习的通用框架——把 SVC() 换成其他算法,其余步骤完全无需改动。
七、交叉验证:评估模型的稳定性
核心思路非常直观:避免偶然事件,多测试几次,取平均值。
from sklearn.model_selection import cross_val_score
model = SVC()
scores = cross_val_score(model, digits.data, digits.target, cv=3)
print(scores) #[0.96, 0.98, 0.97]
print(scores.mean()) #0.97- cv 就是测试次数
- scores 代表每次测试的准确度
- scores.mean() 代表平均准确度
如何判断模型是否存在问题?常用的方法就是观察测试数据的结果:
情况1: scores = [0.97,0.98,0.99] mean = 0.97 波动小,稳定
情况2: scores = [0.60, 0.98, 0.95] mean = 0.84 波动大,不稳定总结
最后,如果只用一句话来理解机器学习,那就是:机器学习不是把规则一条条写死,而是让机器从数据里自己总结规律。
前面讲到的监督学习、梯度下降、SVM、核函数、交互模式、Anaconda、数据集、reshape 和交叉验证,其实都在回答同一个问题:怎么让模型更容易学、学得更稳,也更方便验证结果。
所以这一章真正想传达的,不是某一个具体算法,而是机器学习的基本思路:先用数据喂给模型,再用误差去调整模型,最后用测试和交叉验证确认它到底学得怎么样。