




GPT-5.6发布性能强大但普通人难以使用

前文刚介绍完一个 9B 小模型,今天就迎来顶级模型更新:OpenAI 终于发布了 GPT-5.6。但严格来说,这次发布更像是一次“限量预览”——盲猜一下,Fable 5 那件事给 OpenAI 带来的心理阴影不小,再加上 Anthropic 天天喊狼来了,结果被严厉的父亲当头一棒,这次选择谨慎推进倒也在情理之中。
先搞懂:Sol、Terra、Luna 是啥
以前 OpenAI 的命名简直是灾难,5、5.1、5-pro、5-mini、o1、o3……普通用户根本分不清谁强谁弱。这次 GPT-5.6 干脆把命名规则重做了一遍,逻辑变得特别清爽:
- 数字(5.6):代表这一代的“代际”,类似 iPhone 的 16、17
- Sol / Terra / Luna:代表三个“能力档位”,而且这三个名字会长期存在,各自按自己的节奏进化
具体怎么分?
- Sol:旗舰中的旗舰,OpenAI 说这是“迄今为止最强的模型”,要榨干智能上限就用它
- Terra:均衡款,日常干活主力,性能跟上一代 GPT-5.5 打得有来有回,但价格便宜了一半
- Luna:快又便宜款,用最低的成本提供还不错的能力
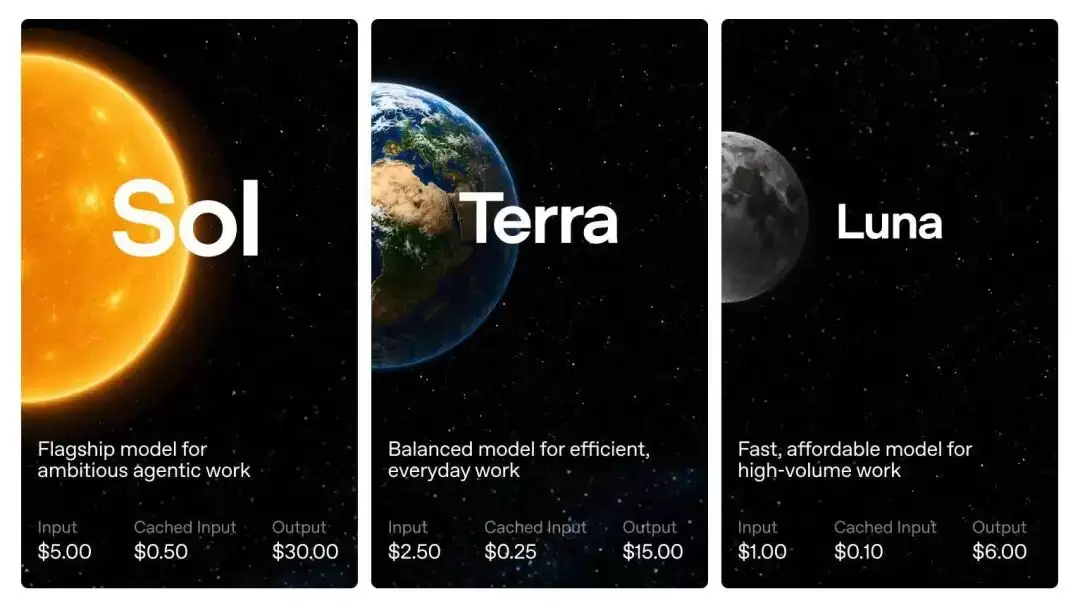
说白了就是把“拉丁语 = 太阳/大地/月亮”搬过来当档位名,听着挺有仪式感。这个改动是对的,至少以后跟人安利的时候,能直接说“预算紧就 Luna,要性能拉满就 Sol”,不用再背一长串型号。
一张图帮你把三个档位的定位和价格一眼看明白:
 GPT-5.6 Sol/Terra/Luna 三档位速查
GPT-5.6 Sol/Terra/Luna 三档位速查
两个新玩法:max 和 ultra
除了三个档位,这次还塞了两个新的“推理强度”选项:
- max 推理强度:给 Sol 留出最长的时间去“深度思考”,遇到硬核难题,让它慢慢磨
- ultra 模式:这个就狠了,它不再是单个 agent 单打独斗,而是调度一群子 agent(subagents)协同,去加速复杂任务
ultra 这个思路很值得玩味。今年大家都在卷 Agent,OpenAI 直接把“多智能体协作”做成了模型自带的一个档位,等于把编排这件脏活累活帮你打包好了,复杂的长链条任务,理论上能跑得又快又稳。
实力到底强在哪
光吹没用,看 benchmark。这次预览 OpenAI 主要秀了编程、生物、网络安全三个方向:
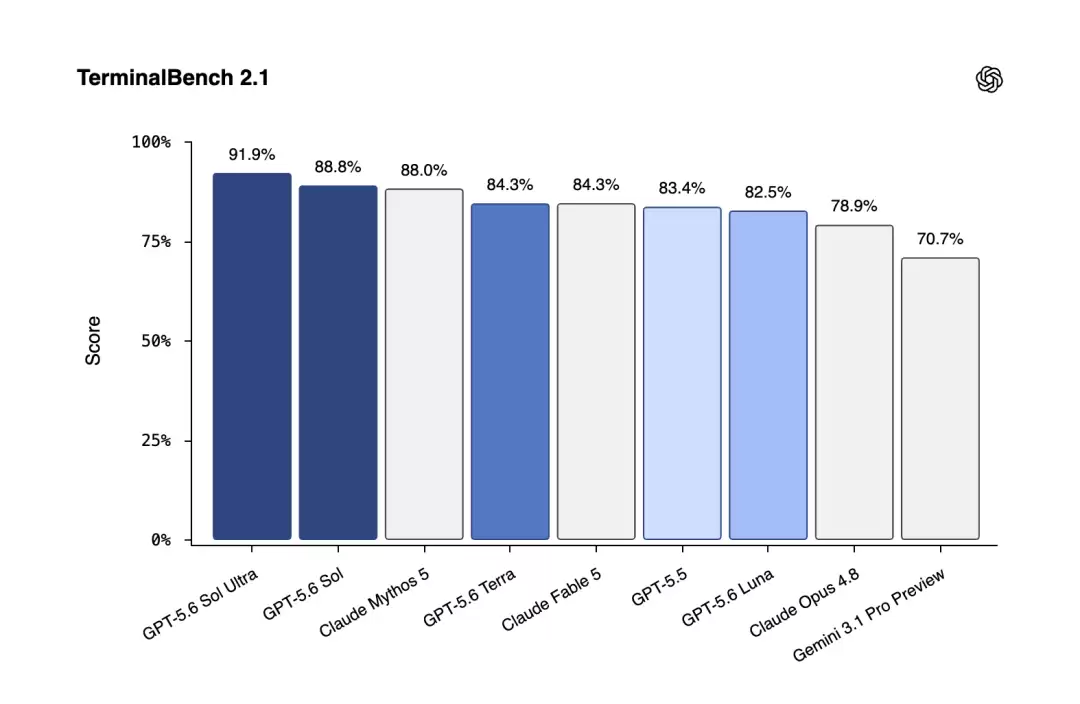
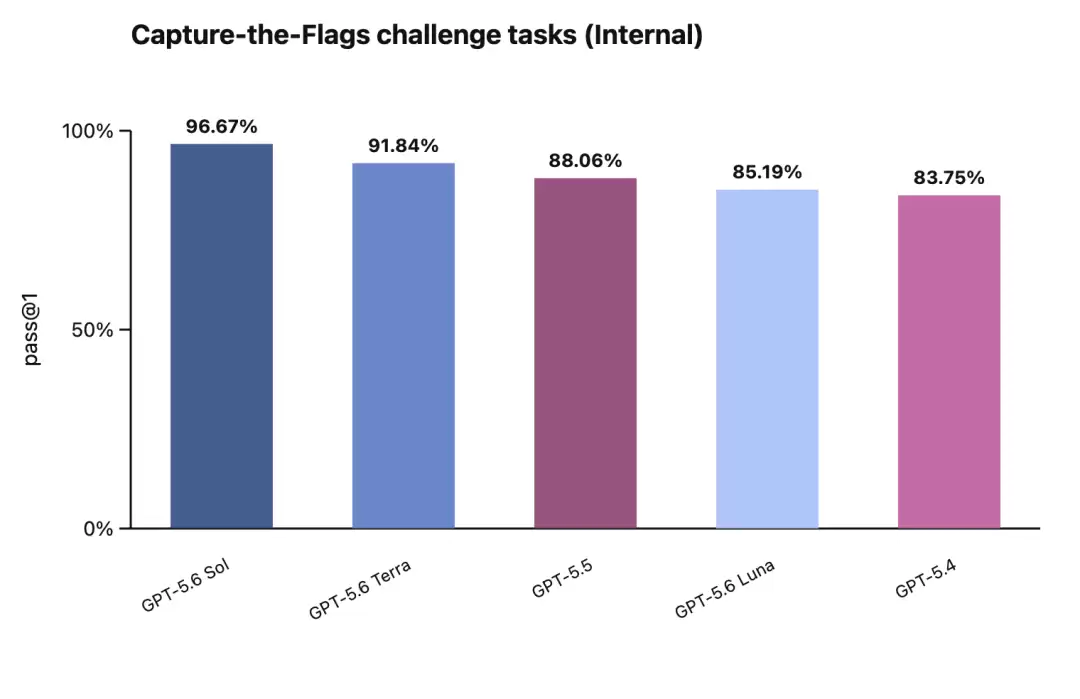
编程:GPT-5.6 Sol 在 Terminal-Bench 2.1 上刷出了新的 SOTA。这个榜专门测命令行工作流,要求模型会规划、会迭代、还会协调工具调用——说人话就是测它当“终端里的全能打工人”靠不靠谱。
生物:在 GeneBench v1 上(评测长周期基因组学和定量生物分析),Sol 不光成绩比 5.5 强,而且用了更少的 token。这点很关键,又强又省,对要烧钱跑科研的团队是真香。
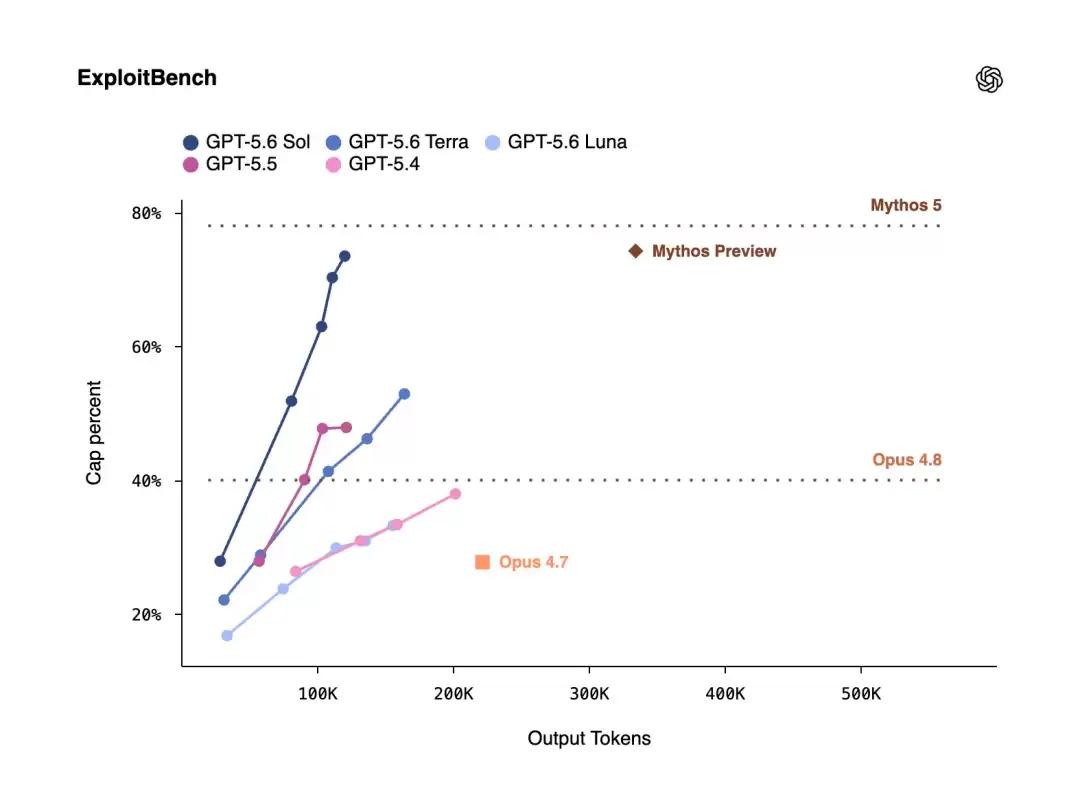
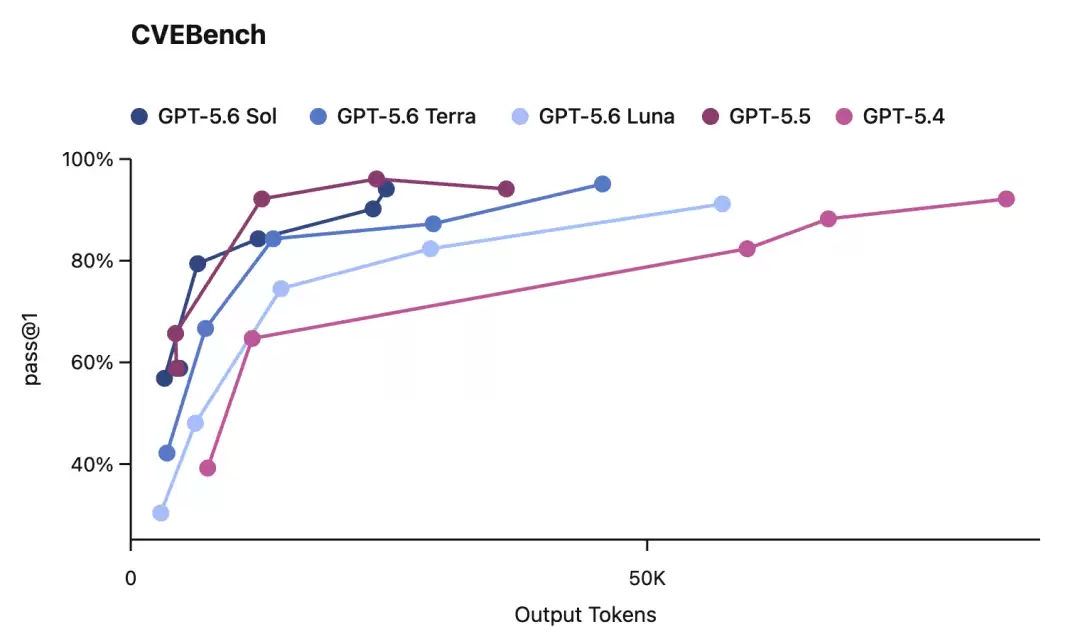
网络安全:这是这次的重头戏。在 ExploitBench 上,Sol 跟 Mythos Preview 性能掰手腕,但只用了对方约 1/3 的输出 token。另外在 UC Berkeley 联合 OpenAI 搞的 ExploitGym 上,Sol、Terra、Luna 三个档位随着推理强度提升,网络安全能力都有明显增长。
这次三档位的“成本-效果”曲线特别值得关注。系统卡里放了一张幻觉率对比图,能直观看出四个模型的取舍:横轴是模拟延迟,纵轴是错误率,左边是“任意幻觉”、右边是“报告的问题仍然存在”。可以看到 GPT-5.6 Sol(蓝色方块)那条线整体压在最下面,同样的延迟下幻觉率明显更低。
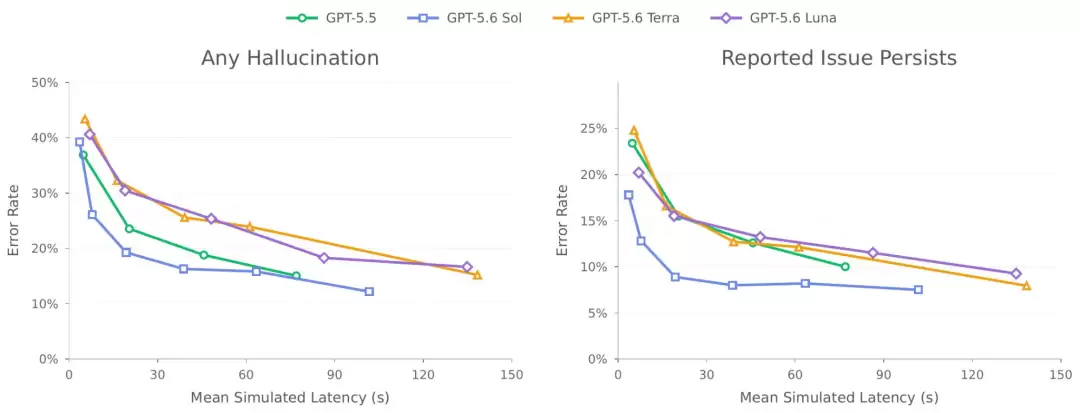 GPT-5.6 Sol/Terra/Luna 与 5.5 的幻觉率对比
GPT-5.6 Sol/Terra/Luna 与 5.5 的幻觉率对比
网络安全:一把双刃剑
这次 OpenAI 花了大量篇幅聊网络安全,态度挺微妙的。一方面,它承认 GPT-5.6 Sol 是“迄今最强的网络安全模型”,能在长周期任务里做漏洞研究和漏洞利用;但另一方面,它反复强调一句话:在 Chromium 和 Firefox 上,Sol 能找到 bug、能搞出“漏洞利用的 building blocks(构件)”,但在测试条件下,没能自主跑通一条完整的攻击链。按照 OpenAI 自己的 Preparedness Framework(准备度框架),它没有跨越“Cyber Critical(网络关键)”这条红线。
但 OpenAI 也很诚实地补了一句:benchmark 的阈值没法覆盖模型所有的使用方式和组合玩法。这种不确定性,加上模型能力的整体跃升,就是它这次要“能力升级配护栏升级、分阶段发布”的根本原因。
一套分层的安全护栏
OpenAI 这次把安全护栏做成了“千层饼”,核心逻辑是:没有任何单一护栏能挡住铁了心要搞事的人。所以它叠了好几层:
- 模型层:训练时就让模型学会拒绝违规的网络攻击请求,哪怕你伪装意图、想越狱也不行
- 实时层:生成过程中,网络安全和生物两个实时分类器盯着输出,一旦发现可能违规,就暂停生成,让一个更大的推理模型回头审一遍上下文,判定违规就直接拦下
- 账号层:可疑行为会触发跨对话的账号级审查,用来区分“持续的恶意行为”和“正常的双用途安全研究”
- 差异化访问:最敏感的能力默认不向所有人开放
这套组合拳打下来,比单靠任何一层都要稳。不过 OpenAI 也提前打了预防针:预览期间,你可能会遇到正常请求被误拦、或者因为要复审而变慢的情况,尤其是那些“攻防看起来很像”的双用途场景。这也正是预览要测的东西——既要挡住坏人,又不能耽误好人干活。
700,000 GPU 小时砸出来的红队
这次最令人瞩目的是这个数字:OpenAI 投了超过 70 万 A100 等效 GPU 小时,用自己的模型去做自动化红队(automated red-teaming)。目标也很明确:找“通用越狱(universal jailbreaks)”——那种能跨多个 prompt、多种场景生效的攻击,而不是只在某个窄场景里灵的小把戏。用 AI 攻 AI,能探索的攻击模式远比人类手测多得多,发现弱点到修复的链路也短得多。
这个思路效果有多猛?系统卡里有张 CyberGym 越狱鲁棒性的图,看完直接让人“哦豁”:四根柱子从左到右,没护栏时通用越狱成功率高达 83%,加上 autoRT 之前的护栏降到 10%,而加上 autoRT 之后的护栏,成功率直接干到了 0.0%。
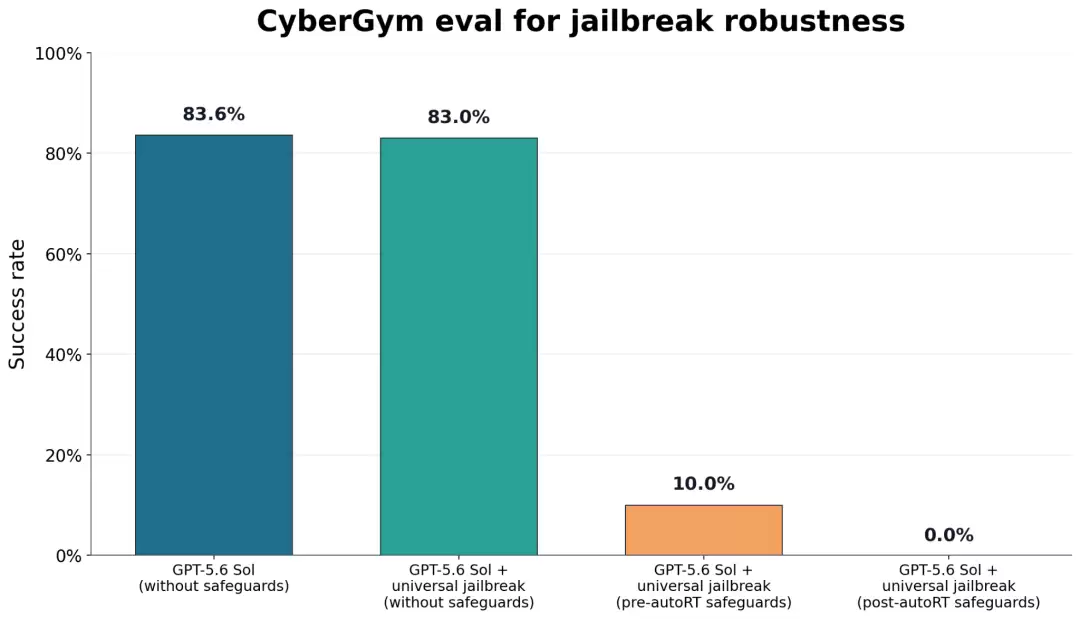 CyberGym 越狱鲁棒性测试:autoRT 护栏后成功率归零
CyberGym 越狱鲁棒性测试:autoRT 护栏后成功率归零
当然,自动化红队之外,OpenAI 还请了第三方专家做人工红队,预览期会继续搞。毕竟人类专家那种天马行空的骚操作,是自动化系统暂时想不到的。
顺带一提,系统卡里还有不少“可监控性(Monitorability)”的评测图,对比了 5.5 和 5.6 Sol 在不同环境下被监控的难易程度,感兴趣的可以去翻原文。
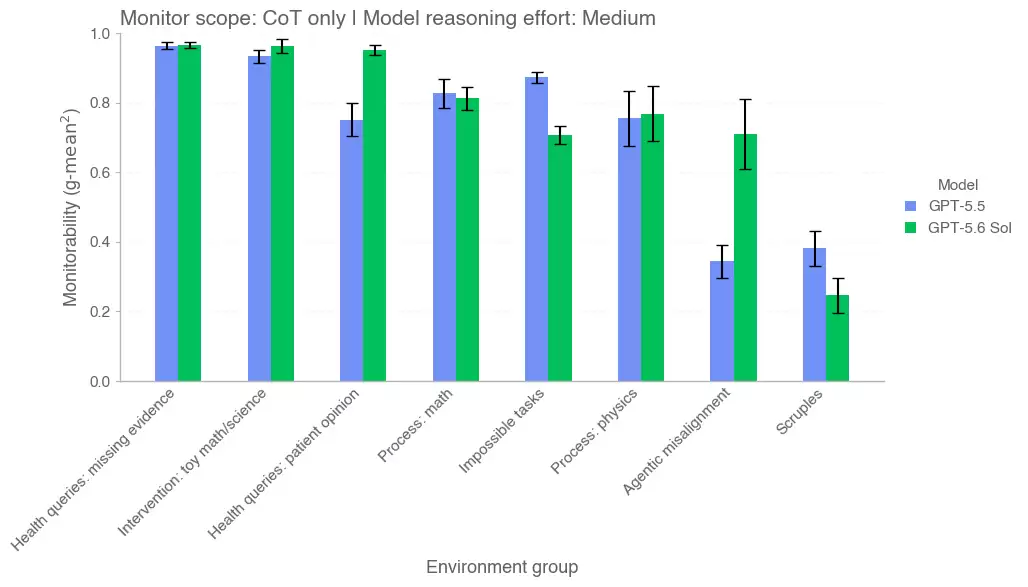 GPT-5.5 与 5.6 Sol 在各环境下的可监控性对比
GPT-5.5 与 5.6 Sol 在各环境下的可监控性对比
价格和怎么用
聊点实在的,多少钱、怎么用得上。
定价(每 100 万 token,输入 / 输出):
- Sol:30 / 120 美元
- Terra:15 / 60 美元
- Luna:6 / 24 美元
Terra 这个定价堪称甜点位,性能接近 5.5、价格砍一半,日常批量任务用它最划算。Luna 则是把成本压到极致,适合那种走量、对智能要求没那么极致的场景。
缓存(prompt caching)也升级了,对开发者是实打实的省钱:
- 支持显式的 cache breakpoints(缓存断点)
- 缓存最短存活 30 分钟
- 从 5.6 开始,cache writes(写缓存)按 1.25 倍未缓存输入价计费,cache reads(读缓存)继续享受 90% 的折扣
速度方面,OpenAI 还宣布 7 月会在 Cerebras 上跑 GPT-5.6 Sol,速度最高能到 750 tokens/秒,前沿智能配上这个吞吐速度,体验估计会很爽,不过初期也是限量给部分客户。
怎么拿到:预览期 GPT-5.6 系列先通过 API 和 Codex 开放给一小撮受信任的合作伙伴,之后才会逐步铺开到 ChatGPT、Codex 和 API 的普通用户。
总的来说,GPT-5.6 是一次“能力 + 安全 + 商业化”三线并进的更新。如果你是开发者,Terra 和缓存升级值得重点关注;如果你做安全相关工作,这次的网络安全能力和护栏设计都值得研究一番。至于普通用户,再耐心等等吧,OpenAI 说了“soon”,咱就盼着这个 soon 别太久。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

AI幻觉变真功能实战教程:App Inventor 2视频录制拓展一周开发实录
先讲一个颇具戏剧性的开端。 这件事的开端颇显荒诞——有用户前来咨询,称AI Pro版的介绍中提到我们有一款“视频录制拓展”。团队全体成员都感到困惑,翻遍产品列表,发现根本不存在该组件。AI那种“一本正经胡说八道”的能力,这次确实让我们陷入尴尬。 按常理,此事到此便可结束——一句“抱歉,暂时没有这个拓

别再混淆OLAP和SQL-on-Hadoop两者查询本质不同
OLAP和SQL-on-Hadoop虽都使用SQL查询数据,但本质不同。SQL-on-Hadoop负责海量数据批量计算与ETL,查询速度秒级至分钟级;OLAP通过预聚合实现毫秒级多维分析,适合BI报表。两者在数据平台分工协作,前者是后厨加工,后者是前台快速服务。

GEO优化深度解析:AI偏好FAQ还是长文内容?
在GEO优化中,AI对内容形式无统一偏好:FAQ在简单查询中引用率41%,长文在复杂查询中达58%。内容应基于用户意图选择形式,FAQ适配简单事实类问题,长文建立主题权威,两者互补而非替代。

架构师视角下程序员避免AI反噬的进阶之路
AI时代程序员角色从执行者向指挥官转型,核心能力转向系统架构设计与问题分析。编码效率提升65%-80%,但安全漏洞率35%-70%。技能断层与K型分化加剧,系统架构师薪资上涨16%,AI指挥官等新岗位需求激增。

AI答案黑箱下技术人如何重构流量新秩序专访GEO优化师罗长才
生成式引擎优化(GEO)从传统SEO的“被点击”转向“被引用”,基于RAG与向量检索的语义相似度计算重构流量秩序。面对AI引用不可追踪的“黑箱”困境,技术人需通过内容结构化、高频问题覆盖及多源覆盖提升被AI引用的概率,实现从排名竞争到知识网络节点价值的转变。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-01 16:26
2026-07-01 16:23
2026-07-01 16:23
2026-07-01 16:23
2026-07-01 16:22
2026-07-01 16:22
2026-07-01 16:21
2026-07-01 16:21
热门教程
2026-07-01 16:26
2026-07-01 16:23
2026-07-01 16:23
2026-07-01 16:23
2026-07-01 16:22
2026-07-01 16:22
2026-07-01 16:21
2026-07-01 16:21
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
