




这件是比OpenAI发布深度研究更值得关注的大事

北京时间2月3日上午,OpenAI突然发布了一款全新的Agent——deep research。这款工具的核心能力,是利用推理合成大量在线信息,并替用户完成多步骤的研究任务。目前它已经整合到ChatGPT中,Pro用户已经能用,Plus和Team用户也将在后续获得访问权限。
说白了,你只需告诉ChatGPT需要一份什么样的报告,然后在对话框中勾选deep research,它就会自己去查找、分析并综合数百个线上资料,最终生成一份相当于分析师水平的综合报告——整个过程只需要5到30分钟。
这已经是OpenAI近两周内的第三次大动作了。此前,他们刚发布了首款AI Agent“Operator”和最新的推理模型o3-mini。而这三连发的时机也颇有意味——全都发生在DeepSeek-R1发布之后。
图片来源:OpenAI
Youtube上自然少不了看热闹的。有网友在deep research发布视频下留言:“Deepseek应该发布R2,这样我们下周就能接触到GPT5。”

图片来源:OpenAI Youtube账号
有意思的是,OpenAI自己似乎也在惦记DeepSeek。在deep research的直播演示画面中,历史聊天记录里有一个问题赫然写着:“Deeper Seeker是个好名字吗?”
这到底是“无心之失”还是“有意为之”不好说,但OpenAI很可能一开始没想给这个新Agent起名deep research,而是想“碰瓷”DeepSeek——至少留个彩蛋。
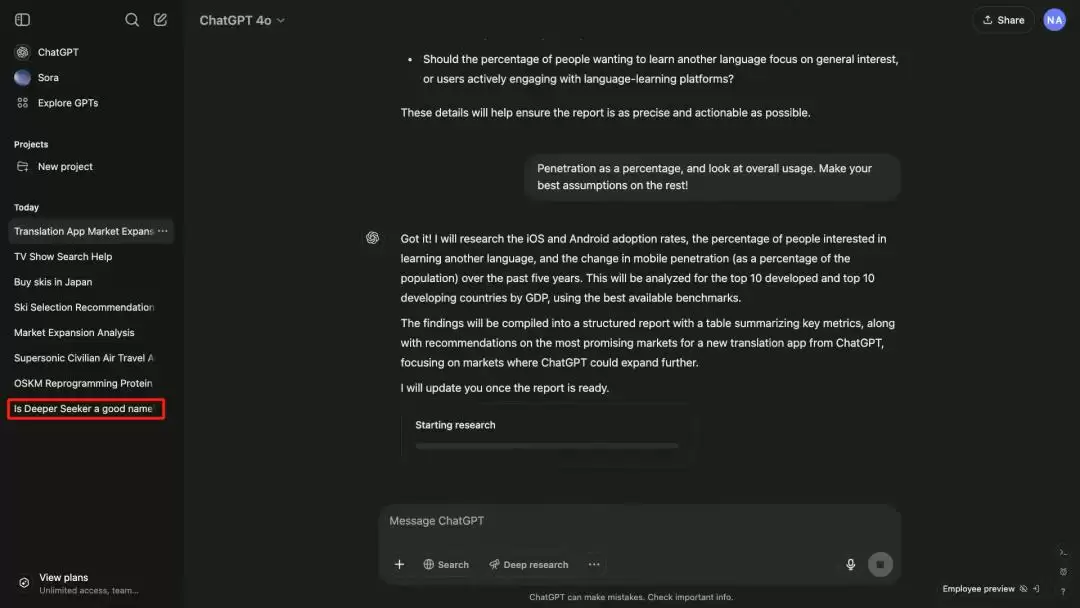
图片来源:OpenAI
从技术层面看,deep research由即将推出的OpenAI o3模型的一个版本驱动,这个版本专门针对网络浏览和数据分析进行了优化。它可以利用推理来搜索、解释和分析互联网上的大量文本、图像和PDF文件,并实时调整策略。
官方给出了不少应用案例,覆盖商业、大海捞针式检索、医学研究、用户体验设计甚至购物等领域。按照他们的说法,deep research能够提供“全面、精确、可靠的研究”“超个性化购买建议”,甚至挖掘出“小众的、非直观的信息”。
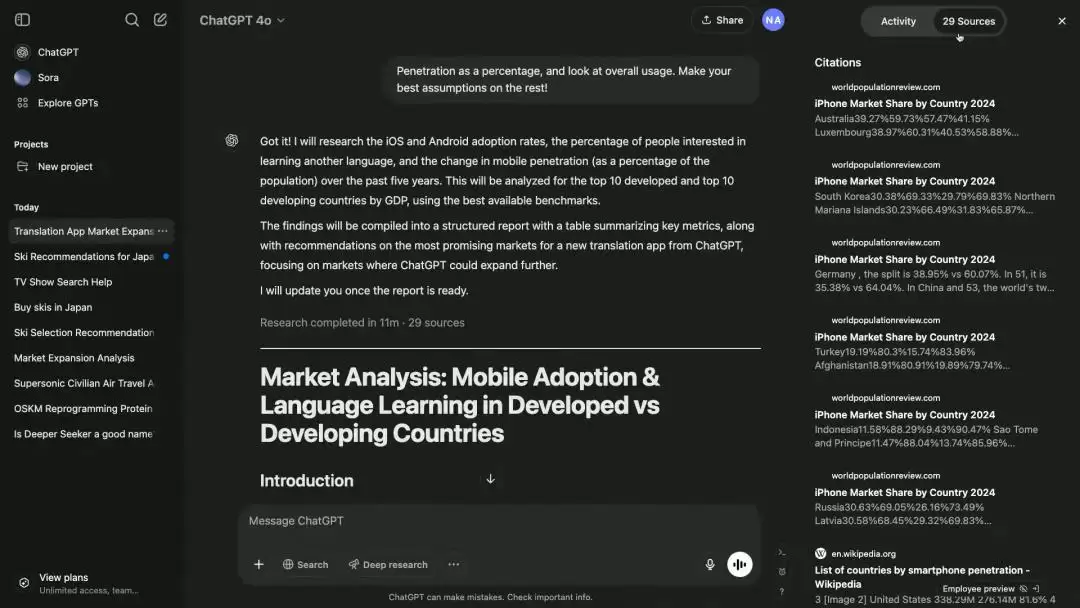
通过deep research生成的市场分析报告,有数据、图表、来源,图片来源:OpenAI

Deep research处理大海捞针问题演示,图片来源:OpenAI
看到这里,不少做行业分析的人恐怕都要倒吸一口凉气:“年还没过完,工作就要没了?”我们把这事分别告诉了DeepSeek-R1和Kimi 1.5。DeepSeek-R1的回应还算温和:“这种变革本质上不是替代,而是将人类智慧从信息处理的‘体力劳动’中解放,转向更高维的价值创造。”而Kimi 1.5则直白得多:“尽管AI在生成研究报告方面展现出了惊人的效率和能力,但人类分析师在理解复杂问题、与客户沟通以及提供专业建议等方面仍然具有不可替代的优势。”
“AI能不能替代人类分析师”这个话题当然值得继续争论,但这次OpenAI o3模型通过deep research展现出的专业能力和复杂问题处理能力,确实非常值得关注。它采用了一种类似人类的方法,在“人类的最后考试”(Humanity’s Last Exam)中取得了迄今为止的最佳成绩。
1.什么是“人类的最后考试”?
这个新基准测试由Center for AI Safety(CAIS)和Scale AI联合推出,目的是评估大语言模型的深度推理能力,并判断专家级人工智能何时真正到来。
基准测试一直是衡量大模型能力的重要工具,但它们的难度并没有跟上模型发展的节奏。以MMLU(Massive Multitask Language Understanding)为例——这个2021年推出的测试涵盖57个学科领域,从基础到高级都有覆盖,包括STEM、社会科学、人文、医学、法律等。但现在很多大模型在MMLU上已经能拿到90%以上的准确率,这意味着它对最先进模型的区分度已经严重不足。
智源研究院副院长兼总工程师林咏华就曾公开表示,有些测评榜单完全可以靠定向训练数据来拔高分数。“C-Eval、MMLU以及CMMLU,这几个类似的测评集已经有点被各个模型过度训练了。”他说,“所以观察大模型能力时,不用过度关注这几个测试集的评分。”
时代呼唤新的基准测试。2024年9月,就在OpenAI发布o1模型后,CAIS和Scale AI开始筹划“人类的最后考试”。2025年1月,这个新基准测试正式推出,相关论文也发到了arXiv上。
在组织团队中,我们发现了一个熟悉的名字——丹·亨德里克斯(Dan Hendrycks)。

“人类的最后考试”组织团队,图片来源:arXiv

Dan Hendrycks,图片来源:UC Berkeley
这位在机器学习、深度学习鲁棒性和AI安全领域颇有影响力的研究者,目前担任非营利组织CAIS的主任,同时也是xAI和Scale AI的顾问。更关键的是——他是当年MMLU基准测试论文的一作。

《MEASURING MASSIVE MULTITASK LANGUAGE UNDERSTANDING》论文,图片来源:arXiv
真正让亨德里克斯下定决心发起“人类的最后考试”的,是OpenAI o1模型——在他看来,这个模型“摧毁了最受欢迎的推理基准”。Scale AI的CEO亚历山大·王(Alexandr Wang)也有同感,去年9月他就呼吁:“我们迫切需要更严格的测试来评估专家级模型,以衡量人工智能的快速进展。”
大约四个月后,CAIS和Scale AI正式推出了这个新基准测试——一个处于人类知识前沿的多模态测试。
“人类的最后考试”共有3000道题目,别小看这个数字——这些题目是从70000道题目中经过重重筛选而来。
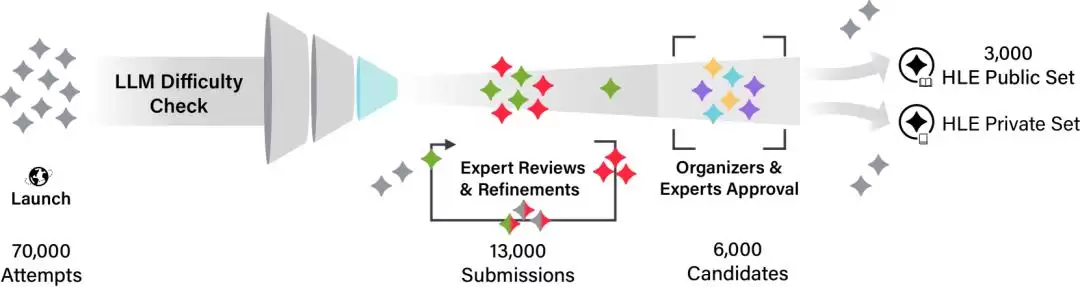
题目筛选过程,图片来源:“人类的最后考试”
这些题目涵盖数学、人文、自然科学等100多个学科,由来自全球500多所机构的近1000名专家精心设计。题型包括选择题和简答题,适用于自动评分。关键是,所有题目都有明确且易于验证的标准答案,但大模型无法通过简单的互联网搜索快速得出结果。

“人类的最后考试”题目学科类型占比,图片来源:“人类的最后考试”
之所以叫“人类的最后考试”,是因为它想成为“最终的”封闭式学术能力评估基准。
我们找了一些样题,看得出来,这些专家们为了难住AI大模型确实是“绞尽脑汁”。比如牛津大学墨顿学院的Henry T出了一道题:“这是一段罗马铭文,最初是在墓碑上发现的,请提供帕尔米拉文字的译文。”

图片来源:“人类的最后考试”
还有一道:“在希腊神话中,伊阿宋(Jason)的外曾祖父是谁?”
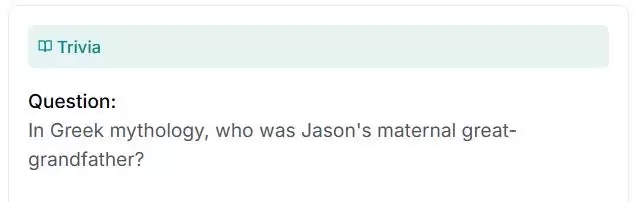
图片来源:“人类的最后考试”
当然还有大量来自各大名校的数学、物理、化学、计算机科学等学科的题目。

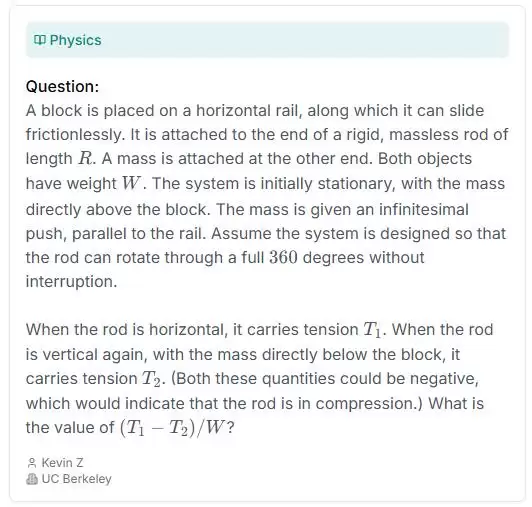


从上至下为数学、物理、化学、计算机科学的题目,图片来源:“人类的最后考试”
这些题目一出,一众大模型纷纷“扑街”。和以往的基准测试相比,包括OpenAI的GPT-4o、o1,以及Anthropic的Claude 3.5 Sonnet、谷歌的Gemini 1.5,在“人类的最后考试”中的准确率都呈现“断崖式下降”。
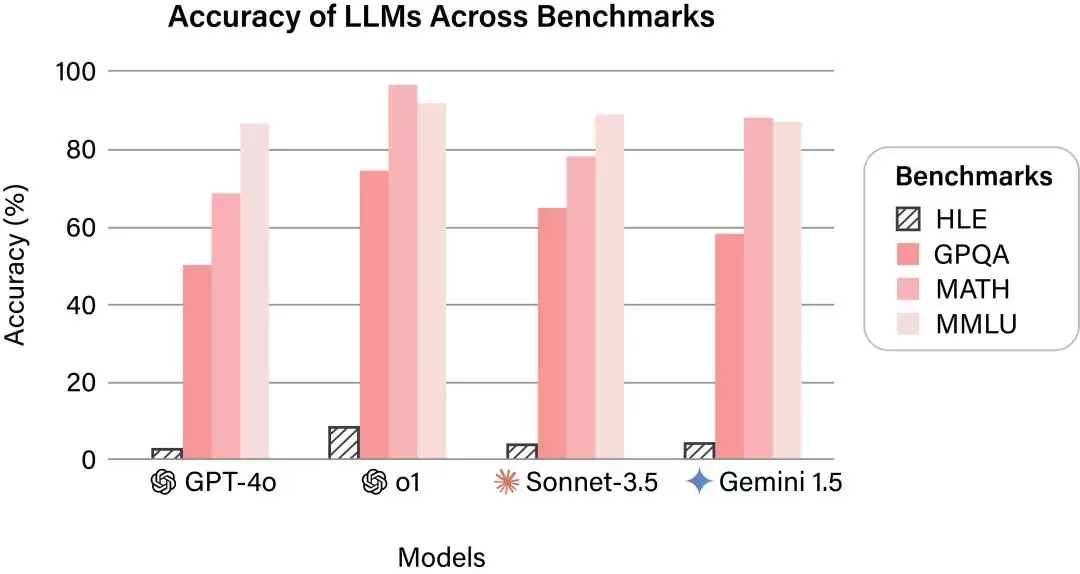
大模型在不同基准测试中的准确率,HLE指的是“人类的最后考试”,图片来源:“人类的最后考试”
可以看出,“人类的最后考试”相比于MMLU等老牌测试,更专注于通过原创且高难度的题目——尤其是数学和深度推理题——来考察模型的极限推理和解决问题能力。其中还有10%的题目考察了多模态能力(比如理解图片),这进一步提升了难度。
“人类的最后考试”团队在介绍文档中不无得意地写道:“这表明它在测量高级、封闭式学术能力方面非常有效。”
但是今天,OpenAI deep research刷新了大模型在这个测试中的最佳成绩——几乎是此前o1准确率的三倍。
2.OpenAI deep research是如何做到的?
根据OpenAI发布的数据,在deep research的加持下,OpenAI o3模型在“人类的最后考试”中取得了26.6%的准确率。相比o1,模型在化学、人文和社会科学、数学领域的进步最为明显。更重要的是,deep research展示了一种类人化的方式——在必要时高效地找到专业信息。

OpenAI deep research在“人类的最后考试”中取得了26.6%的准确率,创下新高,图片来源:OpenAI
顺便提一句,DeepSeek-R1在这个测试中的准确率略高于o1,这同样是对其推理能力的认可。表格中也注明,DeepSeek-R1和OpenAI o3-mini不是多模态模型,仅在文本子集进行了评估。
那么,deep research到底是怎么做到的?答案藏在这张表格的**号部分——浏览和Python工具。
Deep Research通过端到端强化学习,在多个领域的复杂浏览和推理任务上进行了训练。通过这种训练,它学会了如何规划和执行多步骤的操作流程——找到需要的数据,在必要时回溯,并对实时信息做出反应。模型还能浏览用户上传的文件,使用Python工具绘制和迭代图表,将生成的图表和网站上的图像嵌入回答中,并引用来源中的特定句子或段落。
正是这种训练,让它在多个针对现实世界问题的公开评估中达到了新的高度。
不过OpenAI也坦诚地表示,deep research解锁了新能力,但它仍处于早期阶段,存在一些局限性。根据内部评估,它有时会在响应中产生幻觉或做出错误推断——虽然发生率明显低于现有的ChatGPT。它在区分权威信息和谣言方面还有困难,在信心校准方面表现较弱,常常无法准确传达不确定性。发布时,报告和引用中也可能出现轻微的格式错误,任务启动时间也可能更长。
当然,OpenAI预计这些问题都会随着使用和时间的推移而迅速改善。
这不禁让人思考一个问题:“人类的最后考试”真的会是人类给AI大模型的“最后一场考试”吗?如果新的大模型取得了更高的准确率,这又是否意味着AGI的到来?
“人类的最后考试”团队自己给出的观点是:虽然当前的大模型在这个测试上的准确率还比较低,但根据历史经验,基准测试会很快饱和。他们直截了当地说:“‘人类的最后考试’可能是我们需要给模型进行的最后一次学术考试,但它远非针对AI的最后一个基准测试。”团队预计,到2025年底,大模型有可能在这个测试上实现超过50%的准确率。这固然意味着模型在封闭式、可验证的问题以及尖端科学知识方面达到了专家级水平,但“这并不意味着它具有自主研究能力或者AGI”。
有趣的是,团队发表这些观点的时间是1月24日——而现在,距离那时还不到两周,OpenAI deep research就已经展现了“大模型+Agent”具备的一定自主研究能力。
那么,AGI呢?OpenAI首席研究员Mark Chen在deep research发布会直播的最后说了一句话:“Deep research对我们的AGI路线图非常重要。”
剩下的事情,只能交给时间了。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

企业组织级AI赋能具体实施方法
前段时间收到一位读者的留言,希望聊聊企业级、组织级的AI赋能究竟该怎么落地。巧的是,前几天刚看到一份咨询调研机构的数据:对近一两年所有企业级AI赋能项目的统计显示,超过90%的甲方企业认为,AI赋能在核心业务价值链上没有发挥任何实质性作用。除了AI辅助办公、企业智能知识库这类边缘应用起到了一些辅助效

Scrapy与Redis分布式架构的日本电商多平台数据聚合系统
从事日本电商数据聚合工作时,最大的难点在于要同时应对雅虎拍卖、煤炉(Mercari)、乐天和亚马逊日本站等截然不同的平台。以往使用单机爬虫,经常出现运行中崩溃的情况——单点故障、带宽利用率不足、数据存储混乱,这三大痛点令人困扰。 本文分享一套基于Scrapy + Redis的分布式爬虫方案,专门解决

详细PuTTY 0.81安装教程 SSH远程连接与自定义路径设置
PuTTY(简称PT)是一款轻量级开源SSH Telnet客户端,凭借简洁高效的特性,多年来始终是系统管理员与开发者进行远程连接的首选利器。本教程将详细介绍PuTTY 0 81版本的完整安装过程,并指导您自定义安装路径,以便更灵活地管理SSH远程连接工具。 安装准备 首先需要说明的是,整个安装流

在线教育系统必备功能:直播课堂与题库考试架构
很多人一想到做在线教育系统,第一反应往往是先把直播间和课程播放器搭起来,觉得“能看课”就万事大吉了。真到落地那天才发现,系统能不能顺滑跑起来,关键全藏在那些细节里——课程怎么组织、学习进度怎么记、考试怎么处理、后台怎么管得住。前端看起来就几个页面,后端其实是一整条业务链路。不管你是要做在线教育APP

ZStack源码级AI诊断套件让故障排查秒出答案
一次故障排查,到底要花多少时间? 运维人员处理私有云、虚拟化平台的问题,流程大致都是这样:先翻日志看现象,再去文档里找对应机制,然后搜社区有没有类似案例,最后综合判断给出答复。简单问题半小时,复杂问题可能要跨天——而这些时间里,大部分精力耗在了“找信息”而不是“做决策”上。 类似的问题,也许每天都在








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-06-30 16:16
2026-06-30 16:16
2026-06-30 16:16
2026-06-30 16:15
2026-06-30 16:15
2026-06-30 16:15
2026-06-30 16:15
2026-06-30 16:14
热门教程
2026-06-30 16:16
2026-06-30 16:16
2026-06-30 16:16
2026-06-30 16:15
2026-06-30 16:15
2026-06-30 16:15
2026-06-30 16:15
2026-06-30 16:14
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
