




端侧AI推理加速手机大模型提速策略

在手机上运行大模型,听起来确实很酷,但真正部署到设备端时,各种实际问题会接连涌现。
云端的模型可以依赖服务器和数据中心,计算资源充足。然而,手机上的大模型就没有这样的条件了——它必须兼顾电池续航、内存占用、发热控制,还要尽量不让用户等待过长。这几项限制叠加在一起,就成了一道棘手的优化难题。
Google 最近发布了一篇技术文章,专门介绍了他们在 Pixel 设备上针对 Gemini Nano 实现的一次推理加速优化:Frozen Multi-Token Prediction(冻结式多令牌预测)。目前,这一方案已经集成到 Pixel 9 和 Pixel 10 系列的 Gemini Nano v3 中,支撑着 AI 通知摘要(AI Notification Summaries)、文本校对(Proofread)等端侧 AI 功能。
接下来,我们就从这篇文章出发,探讨手机端大模型为什么会变得缓慢,Frozen Multi-Token Prediction 大致如何运作,以及它如何帮助 Gemini Nano 在 Pixel 上加速生成内容。
大模型为什么会出现性能瓶颈
大语言模型生成文字时,标准的做法是逐个 token 逐字输出。
打个比方,这就像一位特别谨慎的打字员,每打一个词都要重新审视之前写下的全部内容,再判断下一个词是什么。流程虽然稳妥,但在手机上就很容易变慢——因为手机的算力、内存和功耗都十分有限。每次只生成一个 token,意味着推理流程需要反复调用,频繁占用内存带宽。
Google 在原文中也提到,移动设备有严格的能耗预算和 RAM 限制,传统的自回归生成方式会形成瓶颈,既影响用户体验,也拖累电池消耗。因此,端侧 AI 想要提速,一个很自然的方向就是:能不能一次生成多个 token?
多猜测 token 再统一验证
Google 的 Frozen Multi-Token Prediction,核心思路是先让一个轻量模块提前猜测几个后续 token,再交回给主模型进行校验。
这其实与投机解码(speculative decoding)的思路类似。正常情况下,生成 N 个 token,大模型需要执行 N 次推理。而投机解码把过程拆成两步:先由一个小而快的模块生成候选 token,再由主模型并行验证。如果候选内容与主模型的判断一致,就可以一次性接受多个 token;如果中间出现分歧,就从分歧位置重新生成下一个 token。
这样一来,模型生成文字就不必永远一步一步地向前挪动了。只要猜测准确,就能一次向前推进好几个 token。
需要说明的是,Google 并没有为 Gemini Nano 单独部署一个重量级的草稿模型(drafter)。他们的做法是在 Gemini Nano v3 主模型后面接上一个轻量的 MTP head(多令牌预测头部),由这个小模块负责提前预测。
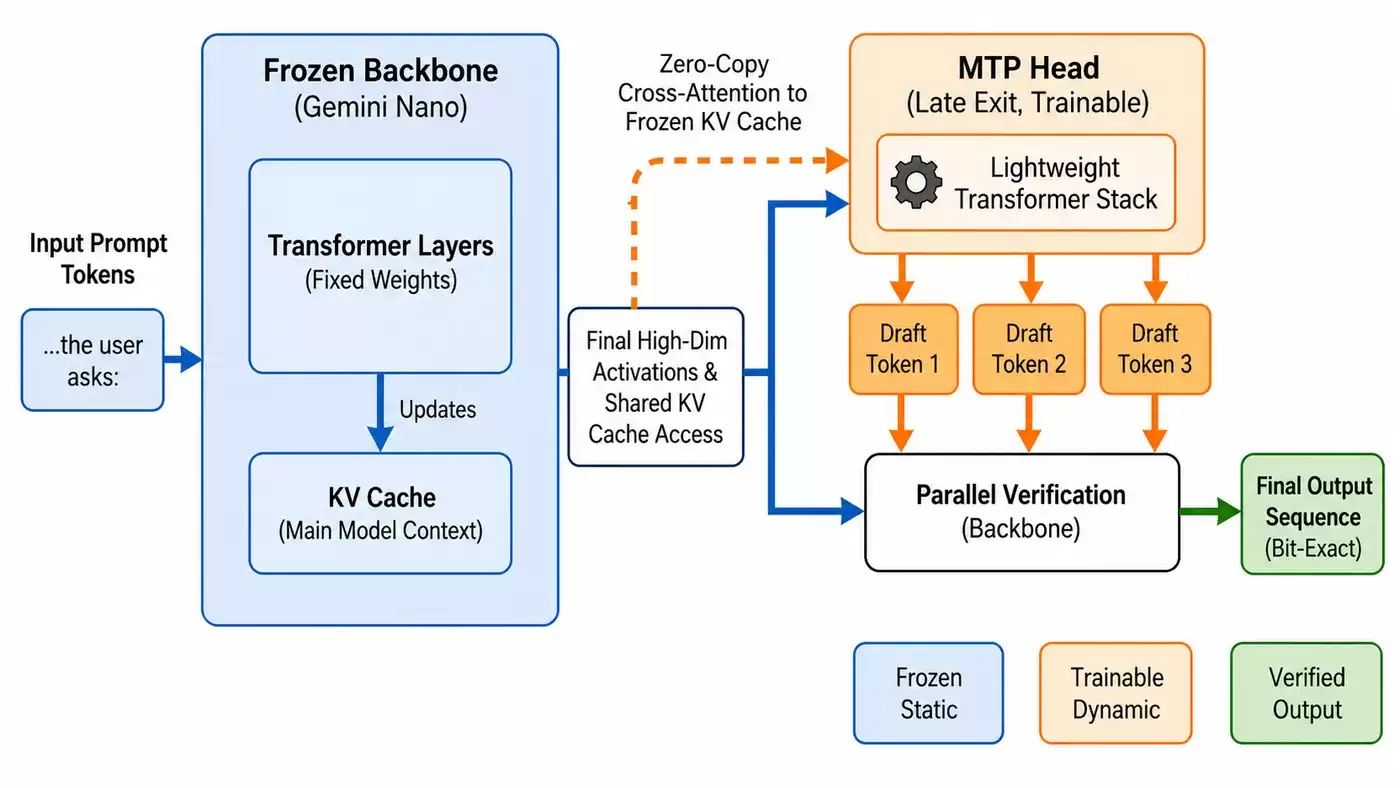
图 1:Frozen MTP 的 zero-copy 架构
MTP Head 复用了主模型已经计算好的 hidden states(隐藏状态)和 KV cache(键值缓存),生成候选 token 后,再由主模型统一验证。
Frozen Multi-Token Prediction 究竟是什么
这里的“Frozen”(冻结)含义是:主模型的权重被固定住,不再更新。
Google 拿已经训练完成的 Gemini Nano v3,将其权重冻结,然后接上一个新的 MTP head。训练时,只训练这个新增的模块,主模型本身不发生变动。Google 认为,这样一来 MTP 更像是一个效率优化层,不会影响基础模型原有的能力和安全对齐。即便提前预测出错,也会在验证阶段被丢弃,最终输出仍然由主模型全权决定。
这一点特别适合端侧部署——手机上的模型已经进入正式运行环境,重新训练或重新适配都非常麻烦。Frozen MTP 的做法相当于在原有模型旁边加装一个“提前预判器”,主要目标就是减少等待时间和资源浪费。
端侧优化:内存也是关键因素
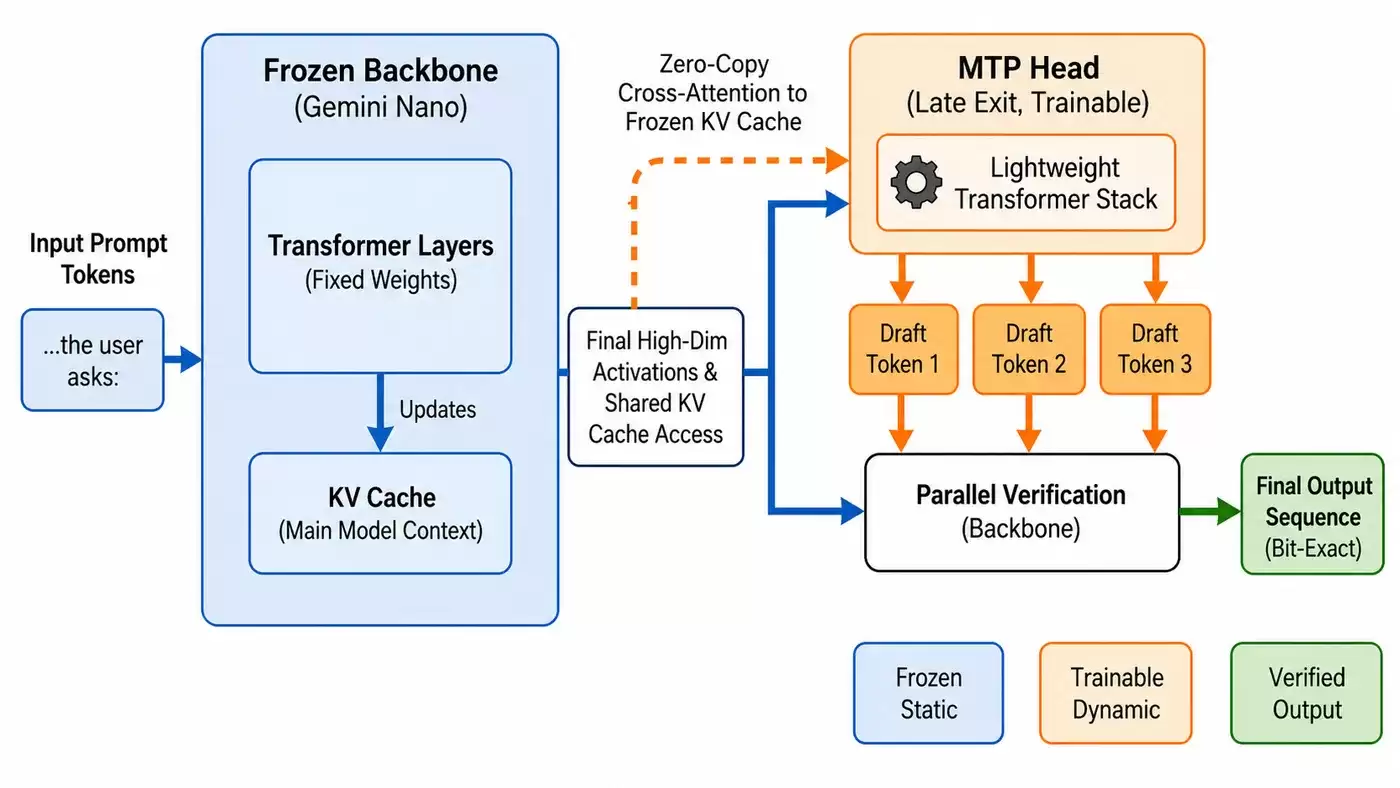
图 1 中还包含一个非常关键的细节:zero-copy architecture(零拷贝架构)。
如果单独引入一个草稿模型,它也需要读取上下文、维护自己的 KV cache,并占用额外内存。对手机来说,这些都是高昂的成本。
Google 的方案是让 MTP Head 直接利用主模型已经计算好的状态,包括 hidden states 和 KV cache。这样一来,小模块不需要重新处理完整的 prompt,也无需重复维护一份上下文缓存。Google 提到,这种设计可以消除草稿模型的额外 prefill 延迟,而且相比独立的草稿模型,每个实例最多能节省约 130MB 的运行内存。
这恰恰是手机端 AI 和云端 AI 非常不同的地方。云端可以靠堆算力解决问题,手机端则要算得快,同时还得尽量少占内存、少唤醒重处理器、少消耗电量。
优化后的性能表现
在 Pixel 9 设备上的实验中,MTP drafter 相比参数量接近的独立 drafter,在部分任务上实现了 50% 以上的加速。对于智能回复(smart replies)这类结构更可预测的任务,token 接受率最高提升到 55%。在 AI 通知摘要和文本校对等生产负载中,MTP 平均每次推理可以正确多预测接近 2 个 token。
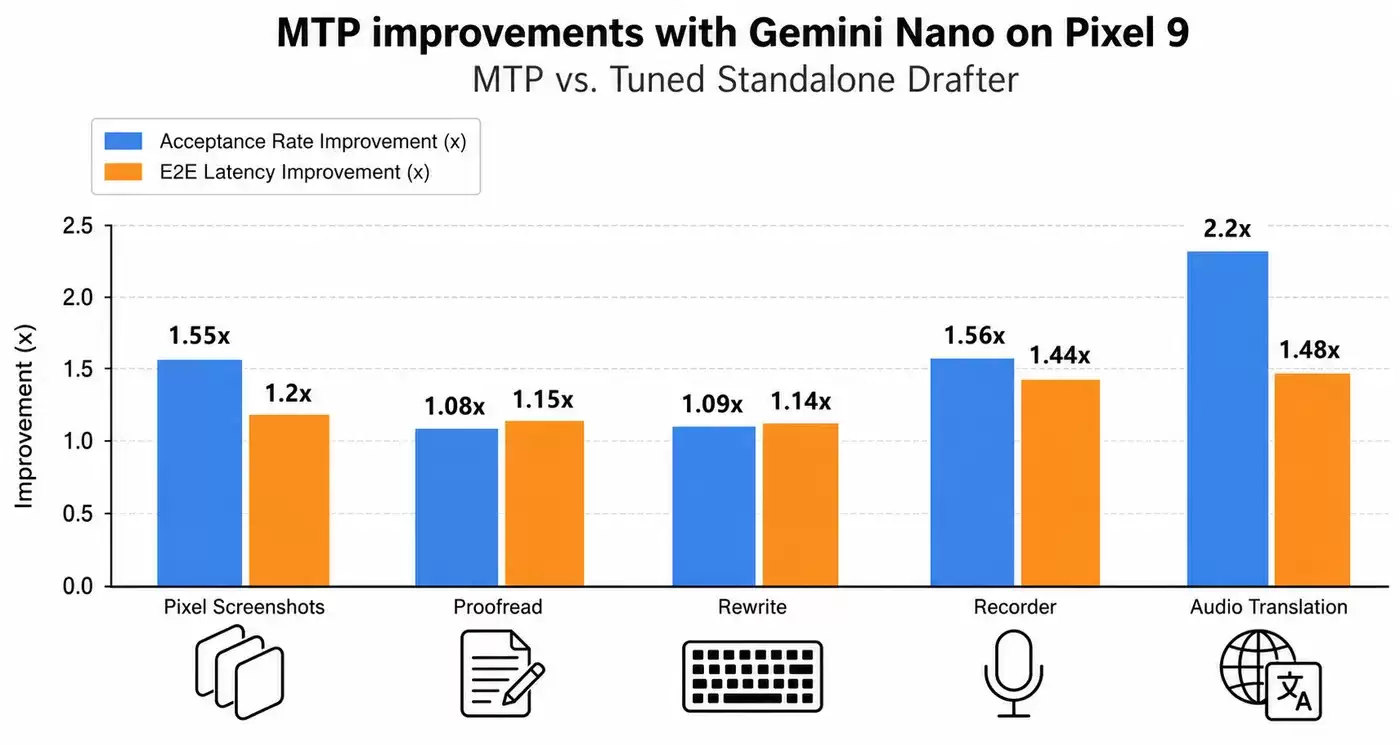
图 2:MTP 结果图
上图展示了 Gemini Nano 在 Pixel 9 不同应用场景中,引入 MTP 后的 token generation 效果对比。
小结
这篇文章可以看作是 Google 对端侧大模型推理的一次工程优化记录。
核心逻辑并不复杂:手机里的大模型生成内容时,如果每次只生成一个 token,就容易变慢;如果能提前预测几个 token,再让主模型统一验证,就有机会减少推理步数。
Frozen MTP 的做法,就是在 Gemini Nano v3 后面加一个轻量预测模块。主模型保持不动,小模块负责提前猜测,主模型负责检查。猜中了,生成更快;猜错了,丢弃重来。
说到底,手机端大模型要获得更快的速度,除了模型本身要轻量,生成方式也需要更少的步骤、更节约的内存。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

微软Copilot插件安装全流程:浏览器与扩展市场配置
围绕MicrosoftCopilot在浏览器、编辑器和扩展市场中的安装与配置,梳理账号准备、安装步骤、权限检查、常见故障及安全使用边界,适合新手快速完成AI办公工具部署。

Microsoft Copilot Docker 一键部署指南:镜像拉取、端口映射与数据目录配置
围绕Copilot类AI办公工具的Docker部署流程,说明镜像选择、拉取校验、端口映射、数据目录挂载、环境变量配置、更新回滚与常见故障处理。

微软Copilot API密钥注册获取与国内网络配置
围绕MicrosoftCopilot相关接口接入流程,梳理账号准备、Azure资源创建、密钥获取、环境变量配置、国内网络连通性优化、常见报错处理与安全管理要点。

微软Copilot Linux部署:环境准备到后台运行全流程
MicrosoftCopilot不适合按本地模型方式安装,Linux服务器更常见的是部署企业入口或集成服务。流程需完成账号授权、运行环境、服务配置、反向代理、进程守护与日志监控,并注意数据权限、访问控制和合规边界。

Microsoft Copilot macOS安装教程:Apple Silicon与Intel配置步骤
MicrosoftCopilot在Mac上可通过网页应用、Edge侧边栏或Microsoft365组件使用,AppleSilicon与Intel机型重点在系统版本、浏览器、账号授权和隐私设置。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-01 06:47
2026-07-01 06:47
2026-07-01 06:47
2026-07-01 06:47
2026-07-01 06:46
2026-07-01 06:46
2026-07-01 06:46
2026-07-01 06:46
热门教程
2026-07-01 06:47
2026-07-01 06:47
2026-07-01 06:47
2026-07-01 06:47
2026-07-01 06:46
2026-07-01 06:46
2026-07-01 06:46
2026-07-01 06:46
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
