




MySQL B+树索引:百万行查询毫秒级的秘密武器

你写了一条 SELECT * FROM user WHERE id = 1,执行计划显示走了主键索引,几毫秒就返回了。换成 SELECT * FROM user WHERE id = 999999,还是几毫秒。表里有五百万行数据,不管查哪一行,速度都相差无几。
你是否好奇过这背后的原理?五百万行数据堆积在磁盘中,MySQL 凭什么能一次精准地定位到你需要的目标行?
答案就藏在“聚簇索引”这四个关键字里。但要真正领悟聚簇索引为什么如此高效,我们得先弄清楚一个更底层的问题——它底层的数据结构到底是什么。
聚簇索引:数据与索引融为一体
在 InnoDB 存储引擎中,表本身就是按主键组织的一棵 B+ 树。所谓“聚簇”,就是指数据行与主键索引紧密绑定,不再分开存放。
打个比方。字典的正文部分本身按照拼音顺序排列。你想查“张”字,翻到 Z 开头的位置,就能直接看到“张”的释义——无需先查一个单独的拼音索引,再到别处找释义。正文和索引其实是同一份数据。
聚簇索引正是这个思路。主键索引的叶子节点里,直接存储的就是完整的数据行。当你通过主键查询一行数据时,找到叶子节点就能获取全部字段,不需要“回表”,也不需要二次查找。
聚簇索引(主键索引)的 B+ 树结构: [1 | 100 | 500] / | [1|10|50] [100|200|300] [500|800|1000] │ │ │ 叶子节点 叶子节点 叶子节点 (完整行数据) (完整行数据) (完整行数据)
非叶子节点只存放主键值,用于导航;叶子节点存放完整的行数据,按主键顺序排列,并且叶子节点之间通过双向链表串联起来。
如果没有聚簇索引会怎样
理解了聚簇索引,我们再反向思考:如果没有它,会是什么情况。
假设表没有主键,数据就是一堆散落在磁盘上的行。你要查找 id = 500 这一行,数据库只能从头开始逐行扫描,直到找到为止。五百万行数据,最坏情况下需要扫描五百万次。这就是全表扫描。
如果存在一棵 B+ 树作为索引呢?同样是五百万行,树的高度大约在 3 到 4 层。你只需从根节点下行到叶子节点,经过 3-4 次磁盘 I/O,就能定位到目标行。
全表扫描是 O(n),走索引是 O(log n)。 当 n 为五百万时,这个差距就是几毫秒和几十秒的天壤之别。
抛出问题:为什么选择 B+ 树
到这里,我们知道了聚簇索引的底层数据结构是 B+ 树。但为什么偏偏是 B+ 树?MySQL 为什么不用其他数据结构?
这并非一个显而易见的问题。直觉上,我们可能想到很多方案:有序数组、二叉搜索树、红黑树、哈希表、B 树。每种方案看似都有道理,但每种都有致命缺陷。
我们来打一场淘汰赛。
淘汰赛:其他数据结构为何被否决
选手一:有序数组
有序数组支持二分查找,O(log n) 的查询效率,确实很快。但它有一个致命问题:插入和删除的成本过高。
在数组中间插入一个元素,后面所有元素都需要往后移动。五百万行数据,每插入一次可能就要移动几百万个元素。对于更新频繁的业务表,根本承受不住。
| 优点 | 缺点 |
|---|---|
| 查询 O(log n) | 插入/删除 O(n) |
| 支持范围查询 | 不适用于频繁写入的场景 |
淘汰原因:写入代价太高,只适合读多写极少的情况(如历史归档表)。
选手二:二叉搜索树 / 红黑树
二叉搜索树查询也是 O(log n),红黑树还能保证树平衡。听起来不错?
问题在于树太高了。二叉树每个节点只有两个子节点,五百万行数据,树的深度大约为 22-23 层。每一层对应一次磁盘 I/O。23 次磁盘 I/O,在机械硬盘上意味着数十毫秒的延迟。
数据库操作的瓶颈不在于 CPU 计算,而在于磁盘 I/O。我们真正要优化的不是比较次数,而是 I/O 次数。
| 优点 | 缺点 |
|---|---|
| 查询 O(log n) | 树太高,I/O 次数多 |
| 红黑树保证平衡 | 每个节点仅有两个子节点 |
淘汰原因:树的深度过大,磁盘 I/O 次数过多。
选手三:哈希表
哈希表的查询是 O(1),比任何树都快。MySQL 自身也支持哈希索引(Memory 引擎)。那么 InnoDB 为何不用哈希作为主键索引?
因为哈希表不支持范围查询。
你查询 WHERE id = 500,哈希表确实很快。但你查询 WHERE id BETWEEN 100 AND 500,哈希表就无能为力了——它只能逐个计算哈希值,无法利用数据的有序性。
而范围查询在业务中极为常见。例如查询最近一周的订单、某个价格区间的商品、某段时间的日志,这些都是范围查询。
| 优点 | 缺点 |
|---|---|
| 等值查询 O(1) | 不支持范围查询 |
| 精确匹配极快 | 不支持排序 |
淘汰原因:无法处理范围查询,而这是数据库的高频操作。
选手四:B 树
B 树和 B+ 树名字只差一个符号,但差异很大。B 树的每个节点——包括非叶子节点——都存储完整的数据行。这意味着每个节点能存放的 key 数量变少,树会更高,I/O 次数也更多。
而且 B 树的叶子节点之间没有链表连接,范围查询只能在树内部做中序遍历,效率远不如 B+ 树沿着链表顺序扫描。
| 优点 | 缺点 |
|---|---|
| 查询 O(log n) | 非叶子节点存数据,树更高 |
| 支持范围查询 | 叶子节点无链表,范围查询效率低 |
淘汰原因:非叶子节点冗余存储数据,范围查询效率不及 B+ 树。
淘汰赛总结
| 数据结构 | 查询 | 写入 | 范围查询 | 树高度 | 结论 |
|---|---|---|---|---|---|
| 有序数组 | O(log n) | O(n) | 支持 | — | 写入太慢 |
| 二叉树/红黑树 | O(log n) | O(log n) | 支持 | 太高 | I/O 太多 |
| 哈希表 | O(1) | O(1) | 不支持 | — | 无法范围查询 |
| B 树 | O(log n) | O(log n) | 支持 | 较高 | 非叶子节点冗余 |
| B+ 树 | O(log n) | O(log n) | 高效 | 极低 | 全部达标 |
B+ 树是唯一一个全面过关的选手。
B+ 树长什么样
B+ 树是一种多路平衡搜索树(并非二叉,而是多叉)。每个节点可以有多个子节点,具体数量由“阶”决定。例如,一棵 3 阶 B+ 树,每个节点最多有 3 个子节点。
下面是一棵简化的 B+ 树,假设每个非叶子节点最多存放 3 个 key:
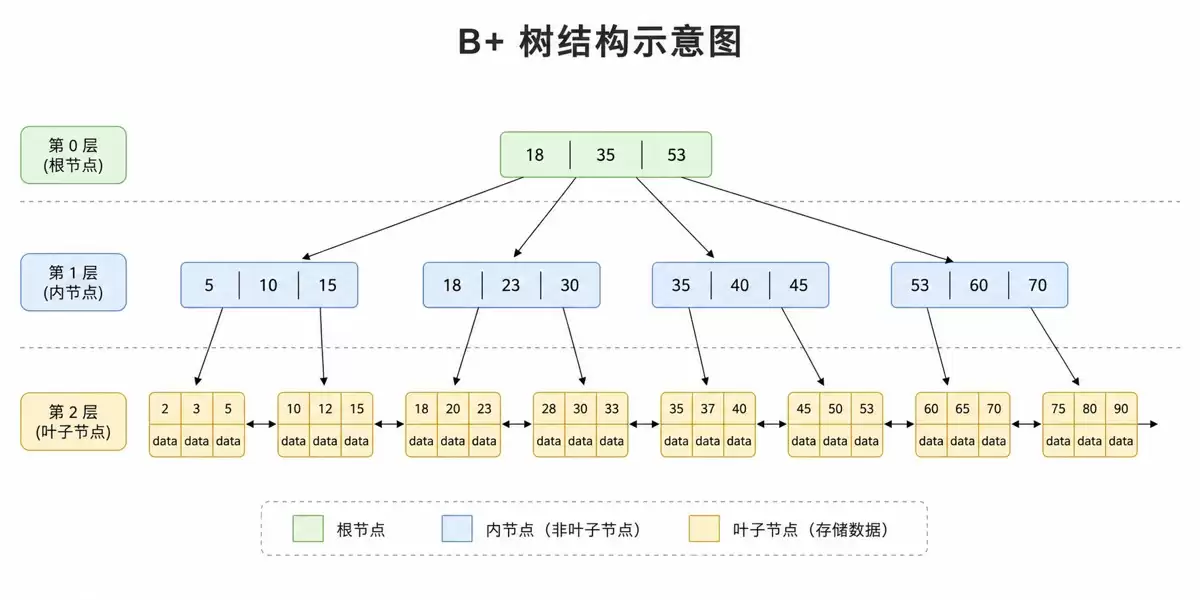
从根节点到任意叶子节点,经过的层数是固定的。这就是 B+ 树的平衡性——无论数据分布如何,查询路径长度始终一致。
B+ 树的两个关键特征
特征一:非叶子节点只存 key,不存数据
这是 B+ 树和 B 树最核心的区别。
B 树的每个节点都存储完整数据行,导致一个节点能存放的 key 数量减少。而 B+ 树的非叶子节点只存放 key 值,一个节点能容纳更多 key,扇出(fan-out)更大,树因此更矮。
打个比方,你去图书馆找书。B 树相当于每层楼的指示牌上都堆满了书,指示牌很大,一层楼放不了几个指示牌,你需要爬很多层。B+ 树相当于每层楼的指示牌只写分类编号,很薄,一层楼能放很多指示牌,你两三层就到顶了,所有书都在最顶层。
树矮 = I/O 次数少 = 查询快。
在实际的 InnoDB 中,一个页(page)默认 16KB。假设一个 key 是 8 字节(bigint),指针 6 字节,一个非叶子节点大约能存 16384 / 14 ≈ 1170 个 key。三层 B+ 树就能存 1170 × 1170 × 16 ≈ 2190 万行数据。两千多万行数据,只需要 3 次磁盘 I/O。
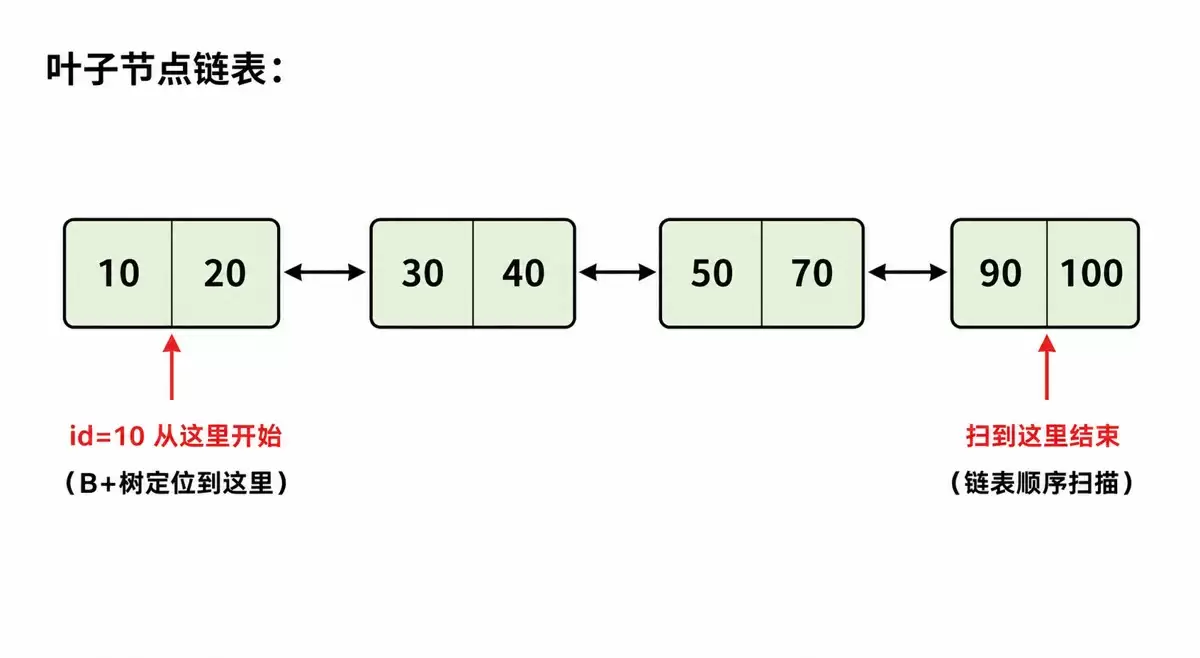
特征二:叶子节点形成有序双向链表
B+ 树的所有叶子节点通过双向链表串联起来,按 key 顺序排列。
这意味着什么?范围查询。
你要查询 WHERE id BETWEEN 100 AND 500:
- 先通过 B+ 树定位到 id = 100 的叶子节点(3 次 I/O)
- 然后沿着链表向右扫描,一直扫到 id = 500
不需要回到父节点,不需要中序遍历,沿着链表扫描即可。顺序 I/O 比随机 I/O 快得多,尤其是在机械硬盘上差距更为显著。
这也是为什么 InnoDB 建议使用自增主键——自增主键保证新数据始终插入在链表尾部,不会引发中间节点分裂和数据移动,写入性能最佳。
为什么是 B+ 树:三个维度归结
将前面的分析归结起来,B+ 树在三个维度上同时实现了最优:
1. 磁盘 I/O 次数最少
非叶子节点不存数据 → 每个节点能放更多 key → 树更矮 → I/O 更少。三层树就能覆盖两千万行数据。
2. 范围查询效率最高
叶子节点链表 → 范围查询变成顺序扫描 → 充分利用磁盘顺序 I/O 的优势。无需在树中来回跳转。
3. 查询性能稳定
平衡树 → 任何查询都经历相同层数 → 不存在“运气好两层就到,运气差要走十层”的情况。每次查询都是确定性的 O(log n)。
这三条加在一起,就是 MySQL 选择 B+ 树的全部理由。并非因为它某一方面特别突出,而是因为它在各个方面都足够优秀,没有短板。
回到开头的问题
回到最初的问题:五百万行数据,SELECT * FROM user WHERE id = 999999 为什么几毫秒就能返回?
- 表数据以聚簇索引的形式组织成一棵 B+ 树,数据行就存放在叶子节点中
- 五百万行数据的 B+ 树高度大约 3-4 层
- MySQL 从根节点出发,经过 3 次二分查找定位到叶子节点
- 叶子节点里直接就是 id = 999999 那一行的完整数据
- 不需要回表,不需要二次查找,3 次 I/O 搞定
就这么简单。不是 MySQL 有多快,而是 B+ 树的结构决定了它只需要 3 次磁盘读取就能定位到任意一行。
小结
B+ 树并非 MySQL 的独创,它是一种通用的数据结构。MySQL 选择它,是因为它在磁盘 I/O、范围查询、查询稳定性三个维度上同时做到了最优,是一个没有明显短板的方案。
B+ 树的设计哲学其实是取舍的艺术。它放弃了哈希表 O(1) 的极致点查速度,换来了范围查询的能力;它放弃了 B 树“每个节点都存数据”的直觉设计,换来了更矮的树和更少的 I/O。每一次“放弃”背后,都是对数据库真实使用场景的深刻理解——数据库不只有点查,还有范围扫描、排序、分组,B+ 树正是这些需求的最佳交集。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Redis 7.0增量AOF重写RDB前导码配置详解
先说一个几乎所有人都踩过的典型误区:很多人把 aof-use-rdb-preamble yes 当作开启“增量重写”的开关。实际上,这个配置只干了一件事——让重写后的 AOF 文件头部带上 RDB 快照。它解决的是加载速度问题,跟“增量重写”本身的概念压根不是一回事。真正的增量重写,依赖的是 Red

在Python Tornado异步框架中安全执行SQL命令的方法与最佳实践
直接在Tornado里用SQLAlchemy同步执行SQL,结果就是阻塞IOLoop,所谓“异步框架里写同步数据库代码”,等于白搭。安全执行的关键不是“怎么写SQL”,而是“怎么不卡住事件循环”。 为什么不能在RequestHandler里直接调用session execute() 因为sessio

利用SQL触发器实现在INSERT数据时自动同步到审计表
先说结论:可以用触发器把 INSERT 数据同步到审计表,但必须用 AFTER INSERT,并且审计表的字段顺序、类型、字符集得和源表严格一致。否则,轻则写入错位、数据截断,重则直接报错、丢数据。下面把这些坑一个一个掰开说。 能,但必须用 AFTER INSERT,且审计表字段顺序、类型、字符集要

如何用SQL编写按不同工作日统计员工出勤率
在实际业务中,统计不同工作日的出勤率是HR系统里的高频需求。如果直接按日期函数分组,很容易掉进语言环境、索引失效或分母口径的坑里。下面就来拆解具体的实现要点。 必须用 CASE WHEN 将日期映射为固定 weekday 标签(如 Mon )再分组,避免语言环境导致的分组断裂;需过滤 DOW IN

Spring Boot 3动态拼接SQL为何引发严重安全漏洞
SQL注入漏洞的核心成因,本质上是因为用户输入直接参与了SQL语句的字符串拼接,而未采用参数化绑定机制。在MyBatis中使用${}、QueryWrapper中调用apply()与last()、JPA的@Query注解进行拼接等操作,都会绕过PreparedStatement的安全防护。动态字段必须








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-02 09:05
2026-07-02 09:04
2026-07-02 09:04
2026-07-02 09:03
2026-07-02 09:03
2026-07-02 09:03
2026-07-02 09:03
2026-07-02 09:03
热门教程
2026-07-02 09:05
2026-07-02 09:04
2026-07-02 09:04
2026-07-02 09:03
2026-07-02 09:03
2026-07-02 09:03
2026-07-02 09:03
2026-07-02 09:03
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
