




清华智谱开源GLM-4-Voice:能用北京话念绕口令且懂情绪

先说几个核心判断:GLM-4-Voice 的发布,标志着语音AI领域迈出了重要的一步。它不是简单的“ASR+LLM+TTS”拼凑,而是真正意义上的端到端语音模型——直接在一个模型里完成语音的理解和生成,绕开了“语音转文字再转语音”的中间过程,最大限度保留了原始音频中的语气、情感和语境信息。你可能会问,这有啥特别的?答案就在它的设计思路里。
GLM-4-Voice 是如何练成的?
传统的级联方案,说白了就是让语音先变成文字,再让大模型处理文字,最后让TTS把文字念出来。这一来一回,中间的信息损失几乎不可避免——语气、停顿、语速,以及那些在语音中隐藏的微妙信息,统统被过滤掉了。而端到端模型用“音频 token”直接建模语音,相当于让模型同时听懂了语音里的话和“话外音”。
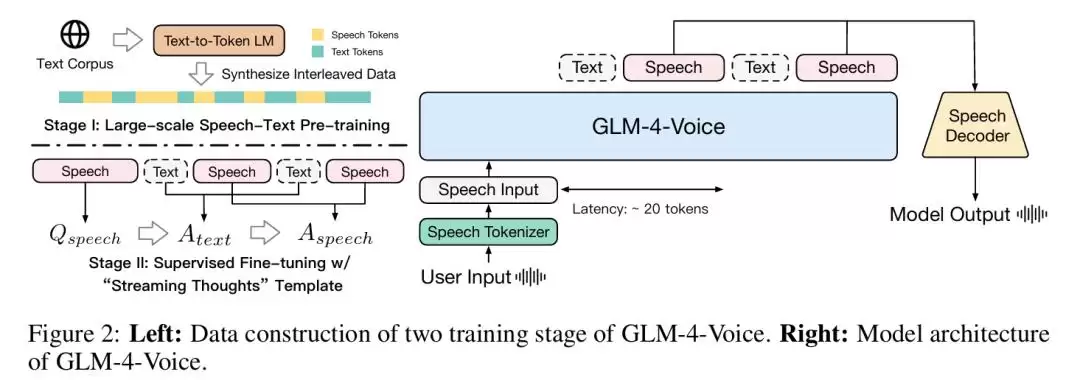
图|GLM-4-Voice 模型架构图。
GLM-4-Voice 由三个核心组件构成:
首先是 GLM-4-Voice-Tokenizer。它的思路很巧妙:在 Whisper 的 Encoder 部分加入 Vector Quantization,并通过有监督的 ASR 数据进行训练,从而将连续的语音输入转化为离散的 token。效率方面,每秒音频平均只需要 12.5 个离散 token 来表示,这个压缩比相当可观。
然后是 GLM-4-Voice-Decoder。这个解码器基于 CosyVoice 的 Flow Matching 模型结构,支持流式推理。最少只需要 10 个语音 token 就开始生成,可以显著降低端到端对话的延迟。
最后是 GLM-4-Voice-9B——这是模型的“大脑”。它基于 GLM-4-9B 进行语音模态的预训练和对齐,从而具备了理解和生成离散化语音 token 的能力。
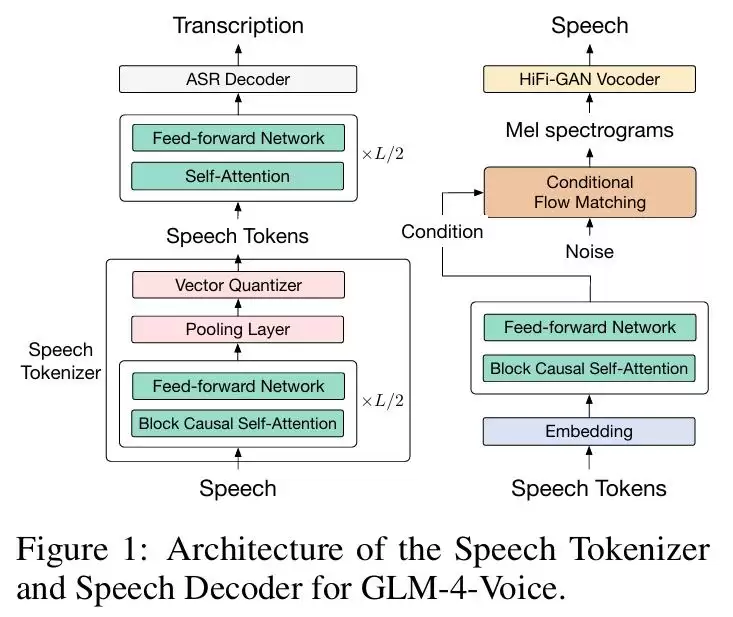
图|GLM-4-Voice-Tokenizer 和 GLM-4-Voice-Decoder 的架构。
预训练方面,团队攻克了两个关键难题:智商和表现力。他们的策略是把 Speech2Speech 任务解耦合为两个子任务——“根据用户音频做出文本回复”和“根据文本回复和用户语音合成回复语音”。这种拆分的好处是,可以针对性设计预训练目标,分别用文本预训练数据和无监督音频数据合成语音-文本交错数据来适配。
具体来说,预训练分为两个阶段。
第一阶段:大规模语音-文本联合预训练。这个阶段用了三种类型的语音数据:语音-文本交错数据、无监督语音数据和有监督语音-文本数据。三管齐下,实现了知识迁移(文本和语音模态间)、帮助模型学习真实世界语音特征,以及在基本任务上的性能提升。值得注意的是,GLM-4-Voice-9B 在 GLM-4-9B 基座上经历了数百万小时音频和数千亿 token 的音频文本交错数据预训练,音频理解和建模能力已经有了很好的基础。
第二阶段:监督微调。这一阶段的目标是进一步提升对话能力。研究人员使用了两种对话数据:多轮对话数据和语音风格控制对话数据。前者主要来自文本数据,经过筛选和语音合成以确保质量和多样性;后者则是高质量的对话数据,用来训练模型生成不同风格和语调的语音输出。
此外,在对齐方面,团队设计了一套“流式思考”架构:根据用户语音,模型可以流式交替输出文本和语音两个模态的内容。语音模态以文本为参照来保证内容质量,还能根据用户语音指令做出相应的声音变化——比如模仿某种语气或情绪。这种设计既保留了语言模型的智商,又具备端到端建模的能力,最低只需要输出 20 个 token 就可以开始合成语音,延迟控制得相当好。
效果怎么样?
研究团队从基础模型和聊天模型两个维度进行了评估。
在基础模型层面,他们通过三项任务来考察:语音语言建模、语音问答,以及 ASR 和 TTS。
语音语言建模方面,GLM-4-Voice 在 Topic-StoryCloze 和 StoryCloze 等数据集上的准确率显著领先。比如在“从语音到文本生成”(S→T)任务中,准确率达到了 93.6%,远高于其他模型。在“语音到语音生成”(S→S)任务中,同样在 Topic-StoryCloze 上拿到了 82.9% 的高分,与 Spirit-LM 相当。
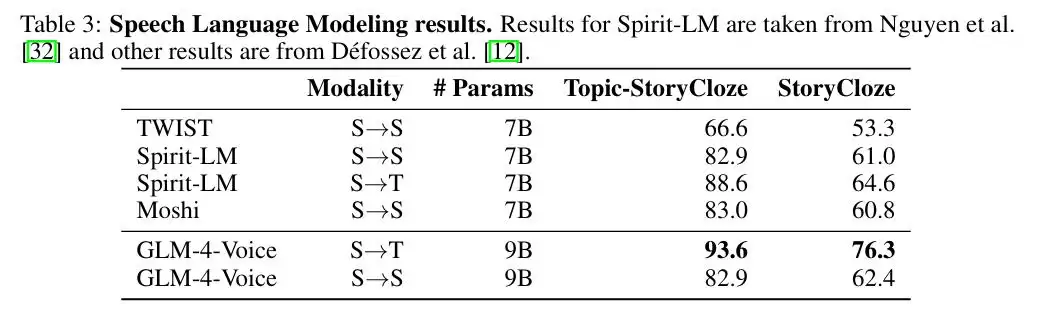
图|语音语言建模结果。
语音问答任务上,GLM-4-Voice 在 Web Questions、Llama Questions 和 TriviaQA 等数据集上全面领先。S→T 模态下,TriviaQA 数据集准确率达到 39.1%,相比 Moshi 提升了 16.3 个百分点。S→S 模态下,在 Llama Questions 中的表现甚至达到了 50.7%,大幅领先其他模型。
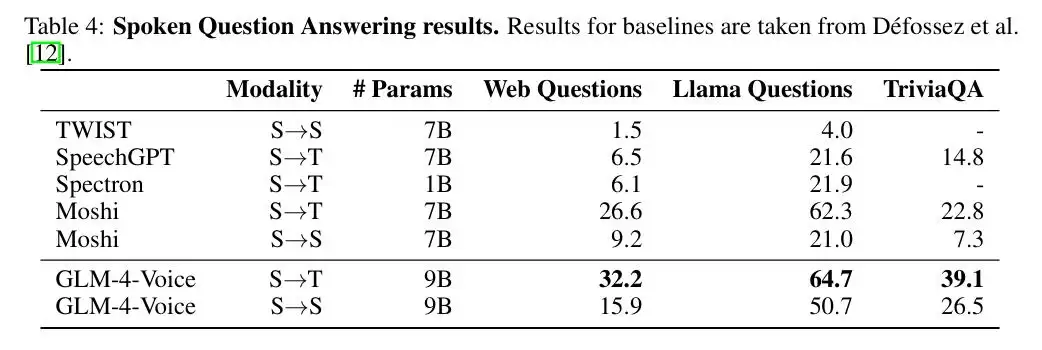
图|语音问答结果。
在ASR 和 TTS 任务中,GLM-4-Voice 的性能接近甚至超越了专门设计的语音处理模型,这说明端到端方案在通用性和专业性之间找到了一个不错的平衡点。
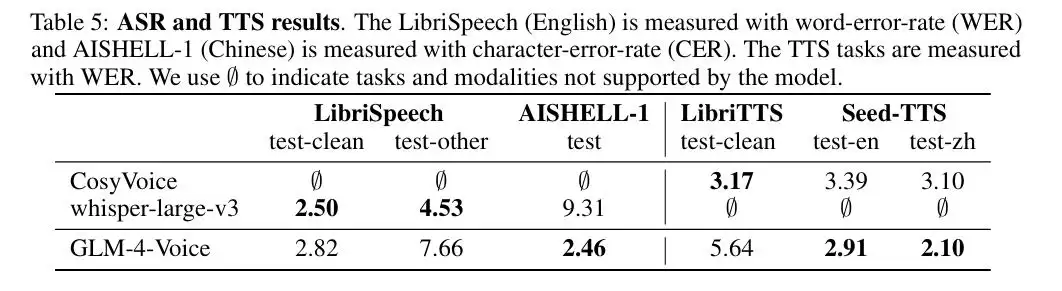
图|ASR 和 TTS 结果。
再看聊天模型的评估结果。研究团队引入了 ChatGPT 作为自动评分工具,对回答进行多维度评价。GLM-4-Voice 在通用问答(General QA)和知识问答(Knowledge QA)两类任务中得分遥遥领先:General QA 得分 5.40,相比 Llama-Omni(3.50)和 Moshi(2.42)提升显著。Knowledge QA 的表现同样超越其他模型。
语音生成质量方面同样亮眼。模型主观评价指标(MOS)达到 4.45,超过现有基线模型,说明生成的语音更加自然流畅。在文本与语音对齐性测试中,语音转文本误差率(ASR-WER)降至 5.74%,显示出一流的文本-语音一致性。这种能力在多模态交互场景中价值显著。
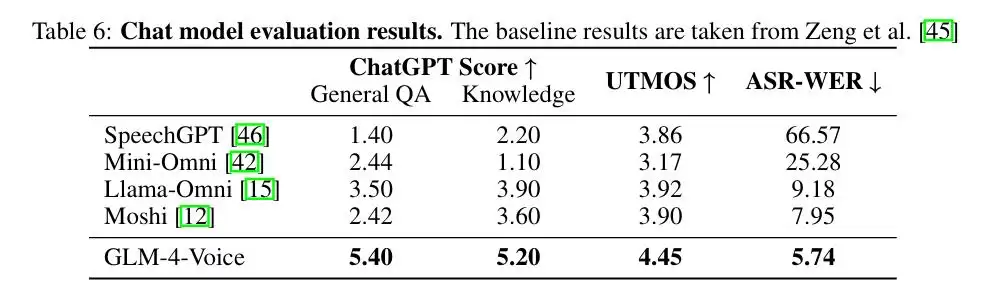
图|聊天模型评估结果。
从数据来看,GLM-4-Voice 确实交出了一份相当亮眼的成绩单:在语音语言建模、语音问答等任务上表现卓越,同时大幅降低了延迟,显著提升了语音质量和对话能力,整体性能全面超越现有基线模型。这种端到端路线为构建高性能语音交互系统提供了全新路径,也让语音AI向真正实用化和易用化迈出了一大步。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

内网RPA离线部署从依赖打包到7×24无人值守踩坑与避坑方案
这三年,内网RPA项目接了不下二十个。每次开局都像闯关——断网、缺依赖、多机同步、定时执行、批量分发、源码保护、AI离线化,八个坑一个比一个深。今天把这些实战经验整理出来,希望能帮正在内网搞自动化的兄弟们少踩点雷。 一、内网无网络环境怎么部署RPA流程:先搞清楚什么叫“真离线” 很多工具宣传“支持本

水利工程师用WorkBuddy写洪水报告效率提升3倍
WorkBuddy开发者分享季 水利工程师AI提效实战:用WorkBuddy撰写洪水影响评价报告,效率提升3倍 WorkBuddy 效率 人工智能 开发工具 一、我是谁,为什么需要AI 先介绍一下自己——我是一名水利工程师,在湖南长沙的一家小型水利设计公司任职。当前行业环境不太

日志服务数据加工规则洞察仪表盘使用指南
数据加工诊断仪表盘 想实时掌握日志服务加工功能的运行状态?直接从加工列表页点击那个“规则洞察”按钮,仪表盘就会立刻呈现出来。入口就在那儿,不绕弯子。 跳转后,你可以按作业名称、实例ID或源LogStore来筛选任务状态。比如下边这张图,展示的是当前实例ID(90c9d47714dbb807d47c1

基于RFID的固定资产管理系统技术架构与工程实践
固定资产管理难题是众多企事业单位的普遍困扰,资产数量动辄数千件,且广泛分布于不同部门、楼层乃至园区。传统人工盘点方式在工程维度上始终面临三大关键瓶颈:采集效率低下、数据闭环中断、状态同步滞后。使用条码枪逐一扫描标签,识别距离通常不超过30厘米,操作人员需逐个寻找并扫描,盘点效率完全受限于人力。面对5

WorkBuddy实战用AI搭建A股智能盯盘助手省心高效
炒股的朋友们想必都深有体会——每天重复盯盘、查行情、分析板块轮动,这一整套流程下来耗费大量精力。手动翻查数据不仅身心俱疲,还很容易错过关键买卖节点。今天我们就来聊聊如何打造一款趁手的盯盘工具,借助AI替你分担这些重复性工作。 背景:盯盘的核心痛点 股民都有同感——每天不只要查询单只股票的实时行情,还








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-02 12:28
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:26
2026-07-02 12:26
热门教程
2026-07-02 12:28
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:26
2026-07-02 12:26
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
