




ChatGPT付费功能免费用,Mistral把Canvas、Artifact全复制了

说回模型本身的表现,Mistral 这次对 Pixtral Large 的定位相当明确:当前视觉领域的 SOTA(State-of-the-Art)。
从他们公布的 benchmark 成绩来看,在 MMMU、MathVista、ChartQA 等六个不同任务类型的数据集上,Pixtral Large 的成绩要么超过 Gemini-1.5 Pro 和 GPT-4o,要么与之持平。和 Claude-3.5 Sonnet 相比,优势还要更明显一些。而对比开源阵营的 Llama-3.2 90B,那更是直接甩开了一个身位。
更有意思的是,Mistral 团队还搞了一个“自测”——用自家开源的 MM-MT-Bench 基准,让 GPT-4o 来做评委。结果你猜怎么着?Pixtral Large 居然排在了第一位,甚至超过了那位“既当裁判又当运动员”的 GPT-4o 本身。
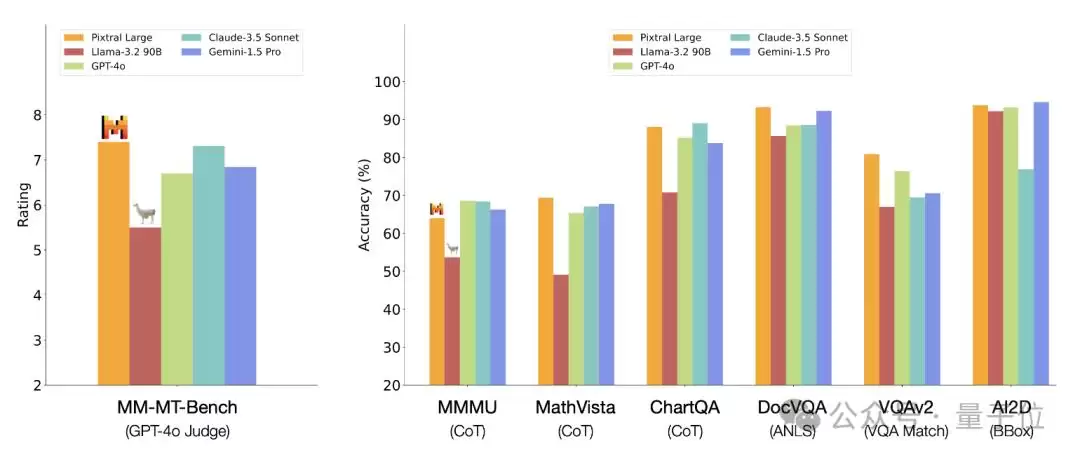
有网友看了这个成绩单后调侃说,看来 benchmark 又该更新换代了。

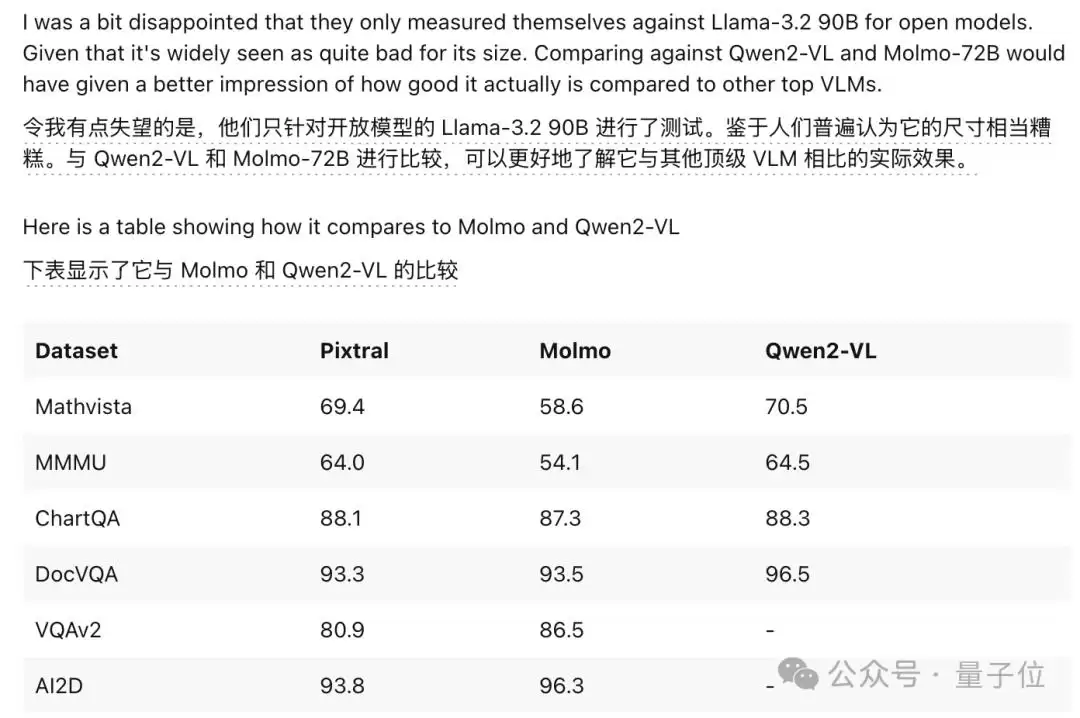
不过,Reddit 上很快就有人提出了不同意见。质疑的点在于:Mistral 官方选择对比的模型数量实在太少了。开源模型只拉了 Llama-3.2 90B 来比,但实际在多个数据集上,Qwen2-VL(72B 的最大版本)的表现其实比 Pixtral 要强。此外,在部分数据集中,Pixtral 的成绩也不如 Molmo——这是由西雅图一家非营利研究机构 Ai2 开发的开源模型。
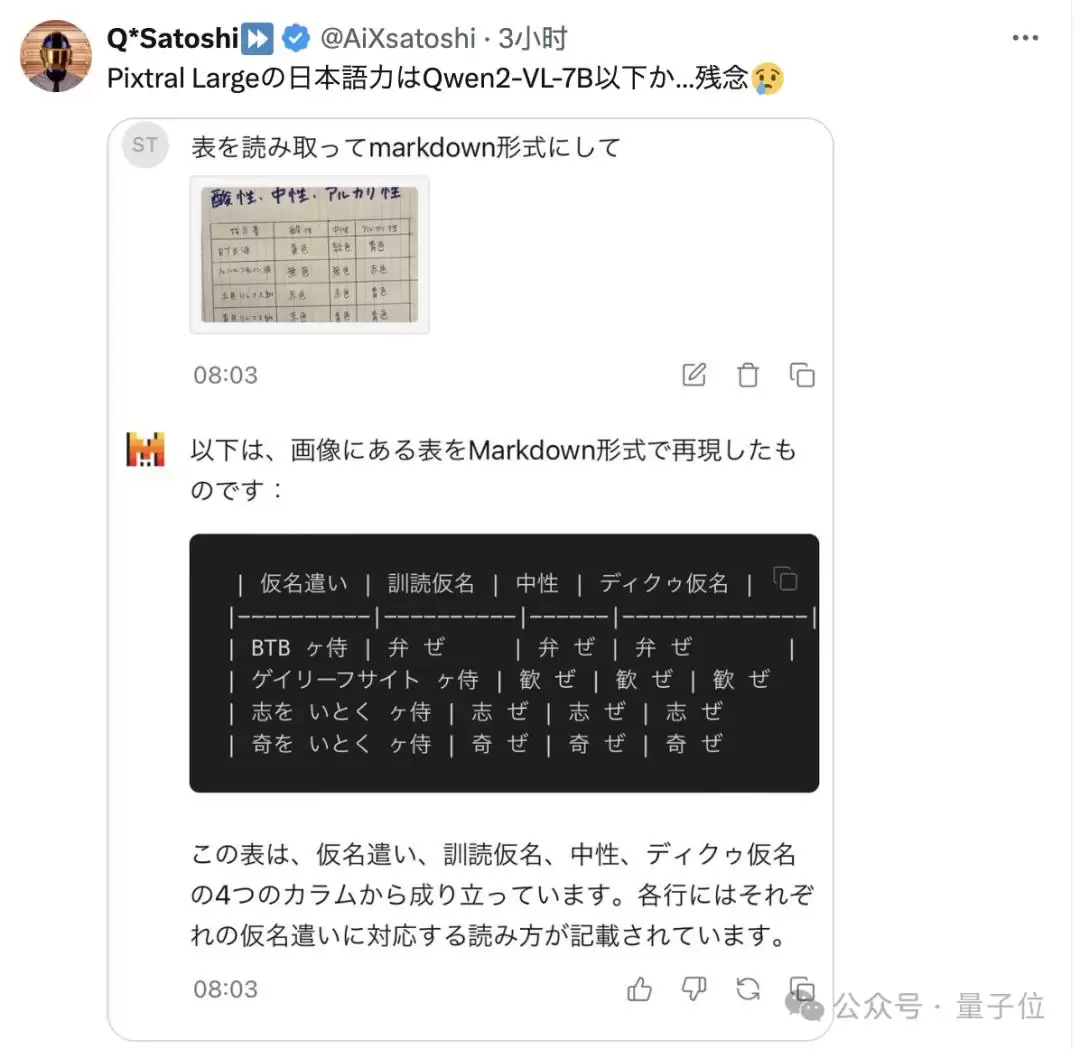
更扎心的是,有网友实测后发现,在包含日文的图片识别任务里,Pixtral Large 的表现甚至还不如 Qwen 的 7B 版本。
所以,Mistral 这次端出来的新产品,到底能不能打?不妨留个言说说你的看法。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

RAG四标融合企业知识资产体系四库协同GEO优化实践
生成式AI正在彻底改写信息检索的底层逻辑。传统SEO依赖关键词堆砌和外链建设的策略,在大模型的内容采信规则下已经基本失效。取而代之的,是生成式引擎优化(GEO)。它不再关注外链数量,而是重点衡量你的知识是否结构化、证据链是否坚实、信源是否可靠——这些维度才是RAG(检索增强生成)架构真正看重的核心指

一个普通上班人分享WorkBuddy使用心得与真实体验
前言 最近我开始使用WorkBuddy——这是腾讯推出的一款AI办公工作台。差不多用了一周时间,趁印象还新鲜,把真实的使用感受记录下来,给还在犹豫的朋友做个参考。不吹不黑,只说实际体验。 初印象:不只是聊天机器人 之前用过不少AI工具,大多数就是个对话框,你问它答,答完就结束了。WorkBuddy不

AI幻觉变真功能实战教程:App Inventor 2视频录制拓展一周开发实录
先讲一个颇具戏剧性的开端。 这件事的开端颇显荒诞——有用户前来咨询,称AI Pro版的介绍中提到我们有一款“视频录制拓展”。团队全体成员都感到困惑,翻遍产品列表,发现根本不存在该组件。AI那种“一本正经胡说八道”的能力,这次确实让我们陷入尴尬。 按常理,此事到此便可结束——一句“抱歉,暂时没有这个拓

别再混淆OLAP和SQL-on-Hadoop两者查询本质不同
OLAP和SQL-on-Hadoop虽都使用SQL查询数据,但本质不同。SQL-on-Hadoop负责海量数据批量计算与ETL,查询速度秒级至分钟级;OLAP通过预聚合实现毫秒级多维分析,适合BI报表。两者在数据平台分工协作,前者是后厨加工,后者是前台快速服务。

GEO优化深度解析:AI偏好FAQ还是长文内容?
在GEO优化中,AI对内容形式无统一偏好:FAQ在简单查询中引用率41%,长文在复杂查询中达58%。内容应基于用户意图选择形式,FAQ适配简单事实类问题,长文建立主题权威,两者互补而非替代。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-01 17:42
2026-07-01 17:42
2026-07-01 17:41
2026-07-01 17:41
2026-07-01 17:41
2026-07-01 17:41
2026-07-01 17:41
2026-07-01 17:41
热门教程
2026-07-01 17:42
2026-07-01 17:42
2026-07-01 17:41
2026-07-01 17:41
2026-07-01 17:41
2026-07-01 17:41
2026-07-01 17:41
2026-07-01 17:41
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
