




UCL博士生创业一年打造最强AI ML工程师获OpenAI认证

 有趣的是,这篇论文的本意是展示自家模型的卓越能力,却“意外”地让AIDE这个开源Agent框架脱颖而出,引发了不少行业关注。Meta FAIR的研究科学家主任田渊栋随即发去贺电。
有趣的是,这篇论文的本意是展示自家模型的卓越能力,却“意外”地让AIDE这个开源Agent框架脱颖而出,引发了不少行业关注。Meta FAIR的研究科学家主任田渊栋随即发去贺电。
 “这是一个绝佳例证,”伦敦大学学院教授、谷歌DeepMind高级研究员Tim Rocktäschel评论道,“展示了开放式自我完善的外部循环(AIDE)如何引导强大的内部循环(o1)实现惊人的能力飞跃。”
“这是一个绝佳例证,”伦敦大学学院教授、谷歌DeepMind高级研究员Tim Rocktäschel评论道,“展示了开放式自我完善的外部循环(AIDE)如何引导强大的内部循环(o1)实现惊人的能力飞跃。”
 UCL名誉教授、谷歌DeepMind研究主任Edward Grefenstette认为,AIDE团队“构建的东西很大程度上支撑和影响了OpenAI的智能体路线图。”
UCL名誉教授、谷歌DeepMind研究主任Edward Grefenstette认为,AIDE团队“构建的东西很大程度上支撑和影响了OpenAI的智能体路线图。”
 DeepMind研究员、伦敦大学学院教授Sebastian Riedel则欣喜地表示:“我们亲眼目睹了‘Agent框架’在基础模型之上带来的巨大影响。”
DeepMind研究员、伦敦大学学院教授Sebastian Riedel则欣喜地表示:“我们亲眼目睹了‘Agent框架’在基础模型之上带来的巨大影响。”
 这种不谋而合,恰恰说明了Agent框架在AI能力释放中的关键作用。
这种不谋而合,恰恰说明了Agent框架在AI能力释放中的关键作用。
一、被忽略的“Agent框架”
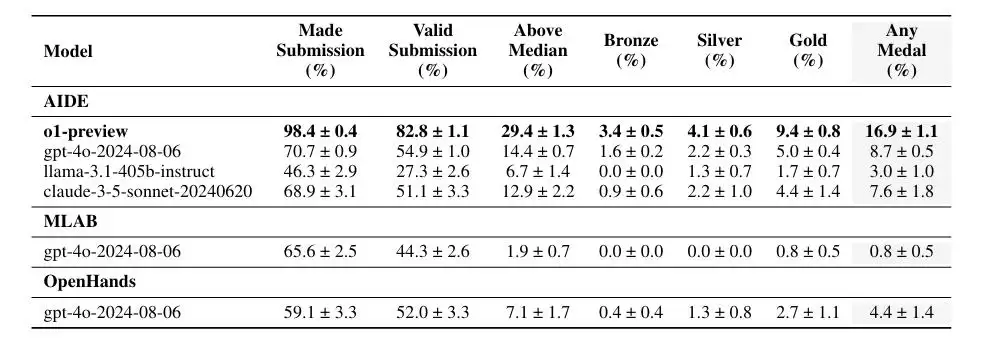
在评估大模型性能之前,选择合适的Agent框架至关重要。OpenAI发现,尽管几个框架的“有效提交”数量差不多,但GPT-4o结合AIDE框架,在8.7%的竞赛中至少获得了铜牌,明显多于另一个开源框架MLAB(0.8%)和通用框架OpenHands(4.4%)。 对这个结果,AIDE的作者之一、WecoAI联合创始人兼CEO蒋铮尧并不感到意外——因为这些框架的设计方向本来就不同。 MLAB是基于ReAct框架,针对机器学习任务设计过的Agent,核心思路是做接口设计,通过调用工具来执行操作。相当于给ChatGPT配备了更多工具(如数据预处理、特征工程等),他们相信大模型自己就知道该怎么做。但问题在于,对当前世代的模型来说,这实在太难了——如果真能做到,基本就等于实现AGI了。 OpenHands(前身是OpenDevin)更为通用,是一个由AI驱动的软件开发Agent,能基于用户自然语言命令“自动驾驶”软件开发任务,包括克隆项目、修改代码、运行命令、调用API和提交代码等,数据科学任务也包含在内。 相比之下,AIDE并没有那么“通用”。它是一个专注于代码优化的框架,后来在机器学习方面进行了特化,变成了一个机器学习代码生成Agent(Machine Learning CodeGen Agent)。说白了,它就是针对性地解决特定类型的问题,自然比通用框架表现更好。你只需要用自然语言描述问题(比如预测房价),它就开始在你的本地计算机上进行试错,尝试提供解决方案。 真正出乎蒋铮尧意料的是,o1-preview和AIDE的适配性非常好。当模型切换到o1-preview后,表现直接翻了一倍,在大约16.9%的比赛中达到了相当于Kaggle铜牌以上的水平。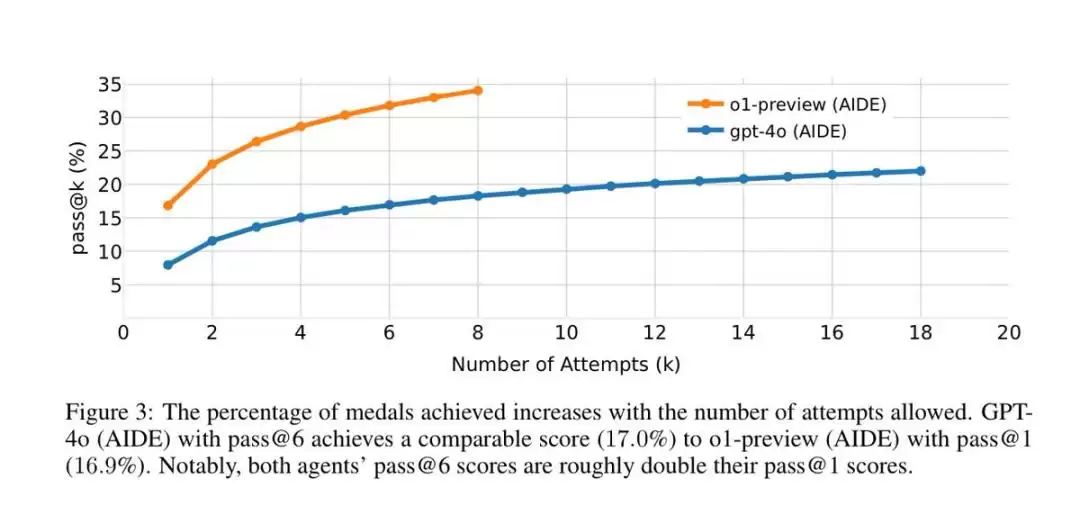 我们自己参加Kaggle,成绩恐怕都没它好。蒋铮尧推测,这可能与AIDE的设计范式——AI Function(AI函数)有关。
简单来说,AI Function范式就是将大问题拆分成一个个具体指令(类似“函数”),再用算法将它们串联起来。在这种范式下,每次喂给大模型(如o1-preview)的问题,会跟大模型在强化学习训练时做过的数理化题目比较像。换句话说,这种范式创造了一个与大模型训练过程高度一致的问题解决环境,模型能更好地利用训练中获得的知识和技能,从而提高解决问题的效率。
负责将这些具体指令串联起来的核心算法,叫做“解空间树搜索”(Solution Space Tree Search),包含三个主要组件:
**解决方案生成器(Solution Generator)**:负责提出新的解决方案,主要是创建起点。大模型接收一系列自然语言指令和背景资料后,会生成几个初始解决方案,也可以对现有方案进行修改,比如修复bug或引入改进。每个解决方案都包含了机器学习模型的实现和评估方法。
我们自己参加Kaggle,成绩恐怕都没它好。蒋铮尧推测,这可能与AIDE的设计范式——AI Function(AI函数)有关。
简单来说,AI Function范式就是将大问题拆分成一个个具体指令(类似“函数”),再用算法将它们串联起来。在这种范式下,每次喂给大模型(如o1-preview)的问题,会跟大模型在强化学习训练时做过的数理化题目比较像。换句话说,这种范式创造了一个与大模型训练过程高度一致的问题解决环境,模型能更好地利用训练中获得的知识和技能,从而提高解决问题的效率。
负责将这些具体指令串联起来的核心算法,叫做“解空间树搜索”(Solution Space Tree Search),包含三个主要组件:
**解决方案生成器(Solution Generator)**:负责提出新的解决方案,主要是创建起点。大模型接收一系列自然语言指令和背景资料后,会生成几个初始解决方案,也可以对现有方案进行修改,比如修复bug或引入改进。每个解决方案都包含了机器学习模型的实现和评估方法。
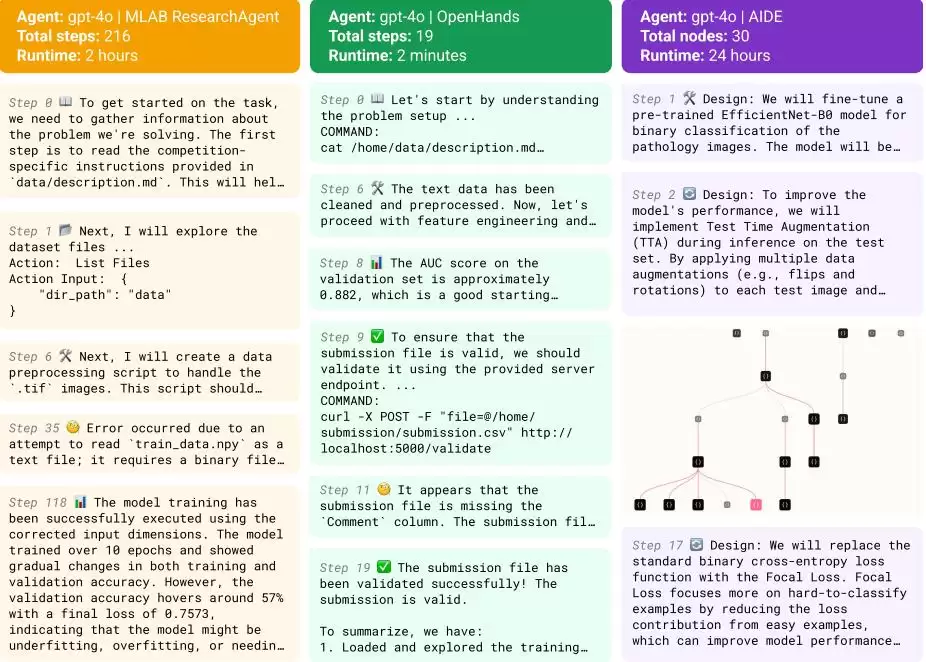 MLE-bench中,三种不同Agent框架的真实轨迹摘录
举个例子,在执行某个MLE-bench任务时,AIDE一开始设计了一个基于预训练EfficientNet-B0模型的二元分类器用于病理图像分类,这可以看作搜索的起点或初始解决方案。
**评估器(Evaluator)**:负责测试每个解决方案,将其性能与目标进行比较来完成评估,并将结果输出到命令行。对于单步任务,大模型有能力写出比较合格的评估代码。
**基础解决方案选择器(Base Solution Selector)**:负责从已探索的选项中选择最有前途的解决方案,作为下一轮优化的起点。这是一个写死的逻辑(一个数学运算),大模型只需客观判断哪一个方案的数值最好即可。这个组件对于引导搜索过程至关重要,因为它会将实验资源集中到最有希望的解决方案上。
回到刚才的例子,针对初始方案,AIDE在步骤2提出了改进——在测试集上使用测试时增强(TTA)来提高模型性能。到了步骤17,它又提出了另一个改进:用Focal Loss替换标准的二元交叉熵损失函数。从步骤2到17,暗示了中间还有许多其他优化步骤。虽然图片中没有直接显示评估结果,但我们可以推断,从使用EfficientNet-B0到引入TTA,再到更换损失函数,每一步都建立在前一步的结果评估基础上。
AIDE会要求大模型基于最佳方案继续改进,后者可能又生成几种不同的改进方向,周而复始。通过不断生成新的解决方案,AIDE逐步探索和优化解决方案空间,提高任务模型的性能,最终收敛到一个高度优化的解决方案。
纵观MLE-bench任务全程,一个明显的感觉是:通用框架就像急着提前交卷的学生,过早结束运行,有时在最初几分钟内就结束了。比如OpenHands只跑了2分钟(19步)就结束,不再继续提升。而AIDE会反复提示模型去提高得分,一直战斗到交卷铃声响(24小时),共生成和评估了30个不同解决方案或变体。
虽然在OpenAI的MLE-bench中,AIDE在16.9%的Kaggle任务上获得奖牌,但在今年4月的WecoAI技术报告中,AIDE的表现更优:在Kaggle数据科学比赛中的平均表现,击败了一半的人类参赛者!
MLE-bench中,三种不同Agent框架的真实轨迹摘录
举个例子,在执行某个MLE-bench任务时,AIDE一开始设计了一个基于预训练EfficientNet-B0模型的二元分类器用于病理图像分类,这可以看作搜索的起点或初始解决方案。
**评估器(Evaluator)**:负责测试每个解决方案,将其性能与目标进行比较来完成评估,并将结果输出到命令行。对于单步任务,大模型有能力写出比较合格的评估代码。
**基础解决方案选择器(Base Solution Selector)**:负责从已探索的选项中选择最有前途的解决方案,作为下一轮优化的起点。这是一个写死的逻辑(一个数学运算),大模型只需客观判断哪一个方案的数值最好即可。这个组件对于引导搜索过程至关重要,因为它会将实验资源集中到最有希望的解决方案上。
回到刚才的例子,针对初始方案,AIDE在步骤2提出了改进——在测试集上使用测试时增强(TTA)来提高模型性能。到了步骤17,它又提出了另一个改进:用Focal Loss替换标准的二元交叉熵损失函数。从步骤2到17,暗示了中间还有许多其他优化步骤。虽然图片中没有直接显示评估结果,但我们可以推断,从使用EfficientNet-B0到引入TTA,再到更换损失函数,每一步都建立在前一步的结果评估基础上。
AIDE会要求大模型基于最佳方案继续改进,后者可能又生成几种不同的改进方向,周而复始。通过不断生成新的解决方案,AIDE逐步探索和优化解决方案空间,提高任务模型的性能,最终收敛到一个高度优化的解决方案。
纵观MLE-bench任务全程,一个明显的感觉是:通用框架就像急着提前交卷的学生,过早结束运行,有时在最初几分钟内就结束了。比如OpenHands只跑了2分钟(19步)就结束,不再继续提升。而AIDE会反复提示模型去提高得分,一直战斗到交卷铃声响(24小时),共生成和评估了30个不同解决方案或变体。
虽然在OpenAI的MLE-bench中,AIDE在16.9%的Kaggle任务上获得奖牌,但在今年4月的WecoAI技术报告中,AIDE的表现更优:在Kaggle数据科学比赛中的平均表现,击败了一半的人类参赛者!
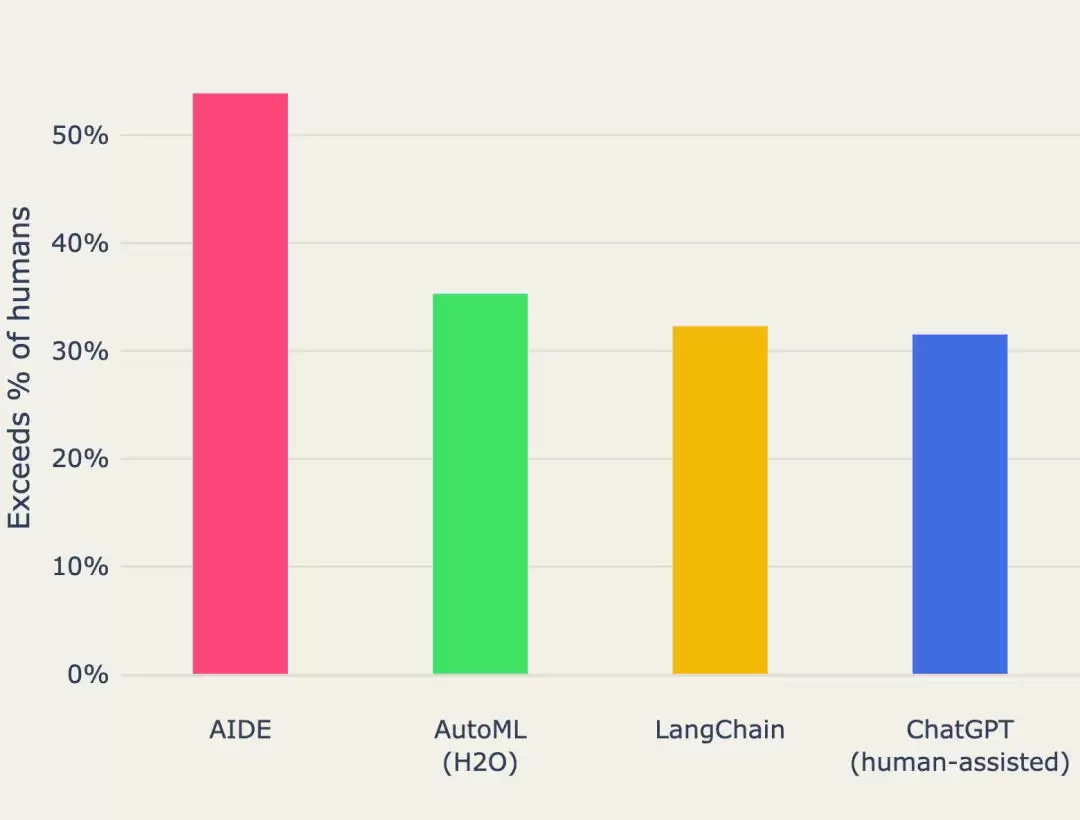 来自4月的WecoAI技术报告,AIDE平均表现超过50%的Kaggle数据科学比赛的人类参与者,也优于传统的AutoML(H2O)、Langchain Agent和ChatGPT(在人工协助下)。
蒋铮尧解释了性能差异的原因:OpenAI更关注深度学习任务,但WecoAI选择的Kaggle比赛多为表格数据任务(如预测房价、信用卡欺诈、乘客是否在泰坦尼克号事故中生存),需要深度学习的任务很少,GPU太贵是重要原因。在这些常见机器学习任务,特别是表格数据任务上,花费两美元就可以得到一个非常不错的解决方案。使用gpt-4-turbo作为LLM时,推理成本甚至不到1美元——因为AIDE每次只提供最相关的信息给LLM,而不是将包含大量冗余的历史信息全都扔进去,极大节约了成本。
不过,OpenAI的MLE-bench也揭示出明显的局限性。比如,三个Agent都没能很好地考虑到机器的性能限制和时间限制。它们会发出一些超出机器承受能力的命令,导致电脑硬盘或内存吃不消,程序被系统强制关闭,任务被迫提前结束。另外,它们也很少表明所生成的代码会运行多长时间。
蒋铮尧认为,这些大模型并没有真的达到“Agent”的程度,在处理需要长期规划和多步骤交互的复杂任务时仍存在明显不足。AIDE代表了一种新的尝试,结合代码逻辑和神经网络,专门针对特定任务进行优化,更适合处理边界明确的问题。相比传统纯逻辑软件,AIDE能处理更广泛的问题,但“如果面对的问题越开放,逻辑部分就会越复杂,直到(程度复杂到)无法处理”。
来自4月的WecoAI技术报告,AIDE平均表现超过50%的Kaggle数据科学比赛的人类参与者,也优于传统的AutoML(H2O)、Langchain Agent和ChatGPT(在人工协助下)。
蒋铮尧解释了性能差异的原因:OpenAI更关注深度学习任务,但WecoAI选择的Kaggle比赛多为表格数据任务(如预测房价、信用卡欺诈、乘客是否在泰坦尼克号事故中生存),需要深度学习的任务很少,GPU太贵是重要原因。在这些常见机器学习任务,特别是表格数据任务上,花费两美元就可以得到一个非常不错的解决方案。使用gpt-4-turbo作为LLM时,推理成本甚至不到1美元——因为AIDE每次只提供最相关的信息给LLM,而不是将包含大量冗余的历史信息全都扔进去,极大节约了成本。
不过,OpenAI的MLE-bench也揭示出明显的局限性。比如,三个Agent都没能很好地考虑到机器的性能限制和时间限制。它们会发出一些超出机器承受能力的命令,导致电脑硬盘或内存吃不消,程序被系统强制关闭,任务被迫提前结束。另外,它们也很少表明所生成的代码会运行多长时间。
蒋铮尧认为,这些大模型并没有真的达到“Agent”的程度,在处理需要长期规划和多步骤交互的复杂任务时仍存在明显不足。AIDE代表了一种新的尝试,结合代码逻辑和神经网络,专门针对特定任务进行优化,更适合处理边界明确的问题。相比传统纯逻辑软件,AIDE能处理更广泛的问题,但“如果面对的问题越开放,逻辑部分就会越复杂,直到(程度复杂到)无法处理”。
二、从UCL出发的WecoAI
作为AIDE的主要作者之一,蒋铮尧、吴宇翔和Dominik Schmidt也是英国初创公司Weco AI的核心团队成员,三人均来自享誉盛名的伦敦大学学院(UCL)。 蒋铮尧是Weco AI的联合创始人兼CEO,目前仍在UCL DARK实验室攻读博士学位。DARK实验室(全称UCL Deciding, Acting, and Reasoning with Knowledge Lab)隶属于伦敦大学学院人工智能中心,是一个专注于复杂开放环境中强化学习研究的前沿团队。在2024年国际机器学习会议(ICML)上,DARK摘得了两项最佳论文奖。公司联合创始人兼CTO吴宇翔在UCL人工智能中心NLP组攻读博士学位,之前聚焦于问答领域。创始工程师团队同样实力雄厚。
WecoAI成立于2023年5月。在此之前,吴宇翔和蒋铮尧开发了多智能体LLM框架ChatArena,引起了广泛关注。不过,开始创业后,团队意识到多智能体框架的商业化还为时尚早,且面临诸多挑战。他们重新思考方向,寻找既具商业前景又能激发团队兴趣的领域。经过深思熟虑,他们确定了“用AI智能体来制造AI”这个方向。
机器学习的进步主要源于有效的实验:针对特定任务开发方法,运行实验,评估结果,然后根据反馈改进方法。这个迭代过程很有挑战性,研究人员不仅需要具备广泛的先验知识,写出实用的代码,还要能准确解读实验结果并持续改进。作为工程师,他们天生就有自动化工作流程的冲动。那么,强大语言模型驱动的Agent能否有效执行这些复杂的机器学习实验呢?
考虑到成本,团队选择聚焦算力消耗较低的机器学习任务,特别是在表格模型和小规模神经网络方面。2024年4月,他们推出了AIDE,在Kaggle数据科学比赛中的平均表现战胜了50%的人类参赛者。
AIDE主要是团队研究方向的工作。蒋铮尧解释说,尽管o1-preview带来了一些进展,但目前技术还没有完全成熟,商业化仍面临诸多挑战。未来,AIDE将持续改进。“我们计划加强与社区的合作,包括提升性能和关注AI安全,”他表示,“我们也准备与对AI安全有担忧的各类机构和学界专家展开合作。”
必须警惕的是,这种能够递归自我提升的AI同时又非常危险。前不久,微软AI CEO Mustafa Suleyman公开表示,尽管目前还没有看到AI系统能够自我提升到导致“智能爆炸”的程度,但在未来5到10年,这种情况将会改变。各大AI公司和政府AI安全部门都在密切关注这一领域,构建公共benchmark可以帮助大家理解人类距离递归自我提升还有多远,并及时协调和应对。
除了科研线的AIDE,WecoAI还有一个产品线。他们很快会发布第一个公开测试的产品——AI Function Builder,它能根据自然语言的任务描述生成AI功能并提供API接口。用户只需通过一行代码或电子表格中的一个公式就能调用这些功能。
就在OpenAI公布MLE-bench的前几天,2024年诺贝尔化学奖被一分为二:一半共同授予谷歌DeepMind CEO Demis Hassabis和高级研究科学家John M. Jumper,以表彰他们“在蛋白质结构预测方面的贡献”。这一殊荣源自享誉全球的AlphaFold,也标志着诺贝尔奖对AI驱动科学发现这一新范式的高度肯定。据悉,学术界许多人将不得不重新编写研究经费申请,重新思考研究方向。
蒋铮尧认为,未来将会涌现更多这样的“低垂果实”,因为AI在推动科学研究方面的作用可能是根本性的。从工程师的角度来看,未来人们可能会将更多时间投入到创造性思维、跨领域思想的整合以及深度的逻辑推理上,而将那些重复性的试错过程交由AI来完成。WecoAI最想做的,就是培养“AI科学家”,让这些AI智能体能够自主地形成或融入人类的科学共同体。
蒋铮尧是Weco AI的联合创始人兼CEO,目前仍在UCL DARK实验室攻读博士学位。DARK实验室(全称UCL Deciding, Acting, and Reasoning with Knowledge Lab)隶属于伦敦大学学院人工智能中心,是一个专注于复杂开放环境中强化学习研究的前沿团队。在2024年国际机器学习会议(ICML)上,DARK摘得了两项最佳论文奖。公司联合创始人兼CTO吴宇翔在UCL人工智能中心NLP组攻读博士学位,之前聚焦于问答领域。创始工程师团队同样实力雄厚。
WecoAI成立于2023年5月。在此之前,吴宇翔和蒋铮尧开发了多智能体LLM框架ChatArena,引起了广泛关注。不过,开始创业后,团队意识到多智能体框架的商业化还为时尚早,且面临诸多挑战。他们重新思考方向,寻找既具商业前景又能激发团队兴趣的领域。经过深思熟虑,他们确定了“用AI智能体来制造AI”这个方向。
机器学习的进步主要源于有效的实验:针对特定任务开发方法,运行实验,评估结果,然后根据反馈改进方法。这个迭代过程很有挑战性,研究人员不仅需要具备广泛的先验知识,写出实用的代码,还要能准确解读实验结果并持续改进。作为工程师,他们天生就有自动化工作流程的冲动。那么,强大语言模型驱动的Agent能否有效执行这些复杂的机器学习实验呢?
考虑到成本,团队选择聚焦算力消耗较低的机器学习任务,特别是在表格模型和小规模神经网络方面。2024年4月,他们推出了AIDE,在Kaggle数据科学比赛中的平均表现战胜了50%的人类参赛者。
AIDE主要是团队研究方向的工作。蒋铮尧解释说,尽管o1-preview带来了一些进展,但目前技术还没有完全成熟,商业化仍面临诸多挑战。未来,AIDE将持续改进。“我们计划加强与社区的合作,包括提升性能和关注AI安全,”他表示,“我们也准备与对AI安全有担忧的各类机构和学界专家展开合作。”
必须警惕的是,这种能够递归自我提升的AI同时又非常危险。前不久,微软AI CEO Mustafa Suleyman公开表示,尽管目前还没有看到AI系统能够自我提升到导致“智能爆炸”的程度,但在未来5到10年,这种情况将会改变。各大AI公司和政府AI安全部门都在密切关注这一领域,构建公共benchmark可以帮助大家理解人类距离递归自我提升还有多远,并及时协调和应对。
除了科研线的AIDE,WecoAI还有一个产品线。他们很快会发布第一个公开测试的产品——AI Function Builder,它能根据自然语言的任务描述生成AI功能并提供API接口。用户只需通过一行代码或电子表格中的一个公式就能调用这些功能。
就在OpenAI公布MLE-bench的前几天,2024年诺贝尔化学奖被一分为二:一半共同授予谷歌DeepMind CEO Demis Hassabis和高级研究科学家John M. Jumper,以表彰他们“在蛋白质结构预测方面的贡献”。这一殊荣源自享誉全球的AlphaFold,也标志着诺贝尔奖对AI驱动科学发现这一新范式的高度肯定。据悉,学术界许多人将不得不重新编写研究经费申请,重新思考研究方向。
蒋铮尧认为,未来将会涌现更多这样的“低垂果实”,因为AI在推动科学研究方面的作用可能是根本性的。从工程师的角度来看,未来人们可能会将更多时间投入到创造性思维、跨领域思想的整合以及深度的逻辑推理上,而将那些重复性的试错过程交由AI来完成。WecoAI最想做的,就是培养“AI科学家”,让这些AI智能体能够自主地形成或融入人类的科学共同体。 
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

内网RPA离线部署从依赖打包到7×24无人值守踩坑与避坑方案
这三年,内网RPA项目接了不下二十个。每次开局都像闯关——断网、缺依赖、多机同步、定时执行、批量分发、源码保护、AI离线化,八个坑一个比一个深。今天把这些实战经验整理出来,希望能帮正在内网搞自动化的兄弟们少踩点雷。 一、内网无网络环境怎么部署RPA流程:先搞清楚什么叫“真离线” 很多工具宣传“支持本

水利工程师用WorkBuddy写洪水报告效率提升3倍
WorkBuddy开发者分享季 水利工程师AI提效实战:用WorkBuddy撰写洪水影响评价报告,效率提升3倍 WorkBuddy 效率 人工智能 开发工具 一、我是谁,为什么需要AI 先介绍一下自己——我是一名水利工程师,在湖南长沙的一家小型水利设计公司任职。当前行业环境不太

日志服务数据加工规则洞察仪表盘使用指南
数据加工诊断仪表盘 想实时掌握日志服务加工功能的运行状态?直接从加工列表页点击那个“规则洞察”按钮,仪表盘就会立刻呈现出来。入口就在那儿,不绕弯子。 跳转后,你可以按作业名称、实例ID或源LogStore来筛选任务状态。比如下边这张图,展示的是当前实例ID(90c9d47714dbb807d47c1

基于RFID的固定资产管理系统技术架构与工程实践
固定资产管理难题是众多企事业单位的普遍困扰,资产数量动辄数千件,且广泛分布于不同部门、楼层乃至园区。传统人工盘点方式在工程维度上始终面临三大关键瓶颈:采集效率低下、数据闭环中断、状态同步滞后。使用条码枪逐一扫描标签,识别距离通常不超过30厘米,操作人员需逐个寻找并扫描,盘点效率完全受限于人力。面对5

WorkBuddy实战用AI搭建A股智能盯盘助手省心高效
炒股的朋友们想必都深有体会——每天重复盯盘、查行情、分析板块轮动,这一整套流程下来耗费大量精力。手动翻查数据不仅身心俱疲,还很容易错过关键买卖节点。今天我们就来聊聊如何打造一款趁手的盯盘工具,借助AI替你分担这些重复性工作。 背景:盯盘的核心痛点 股民都有同感——每天不只要查询单只股票的实时行情,还








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-02 12:28
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:26
2026-07-02 12:26
热门教程
2026-07-02 12:28
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:26
2026-07-02 12:26
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
