




清华面壁提出颠覆现有Agent新一代主动交互范式

你有没有想过,如果AI能“眼中有活”,那会是一种什么样的体验?
目前,哪怕是ChatGPT这类最先进的AI Agent,本质上还停留在“被动式”阶段——就像图1左侧展示的那样。你需要明确告诉它“做什么”,它才会开始干活。指令不清晰?那它就只能干等着。
但最近,清华大学联合面壁智能等团队,拿出了一套完全不同的方案——主动Agent交互范式(ProActive Agent)。这几乎是AI交互领域的一次突破性创新。简单说,新范式下的Agent不再只是个“指令执行器”,它升级成了有“眼力见”的智能助手。
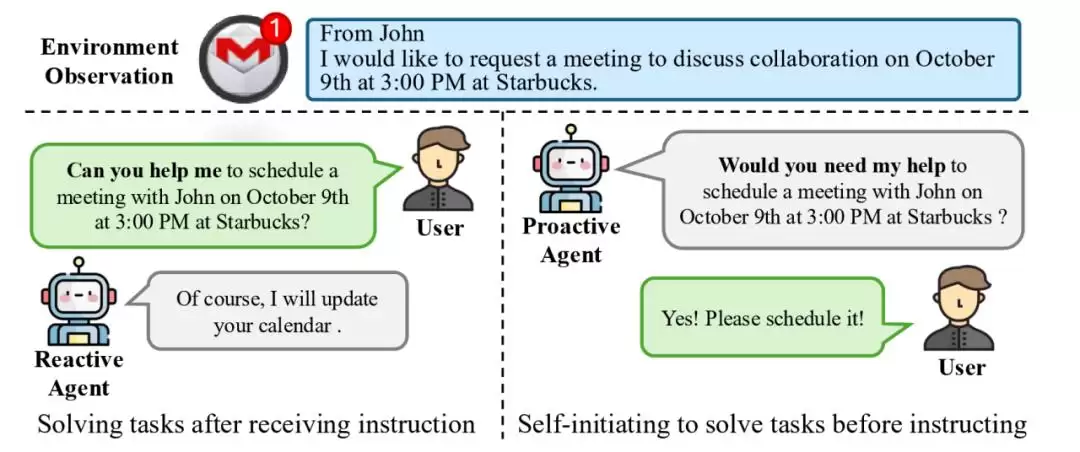
图 1:两种人类与智能体交互形式的比对。左侧的被动式 Agent 只能被动接受用户指令并生成回复,而右侧的主动式 Agent 可以通过观测环境主动推断与提出任务。
什么叫“眼力见”?就是它能主动观察环境、预判你的需求,像肚子里的蛔虫一样,就算你没开口,它也能主动帮你排忧解难。从“被命令”到“会思考”,这个质的飞跃挺有意思。
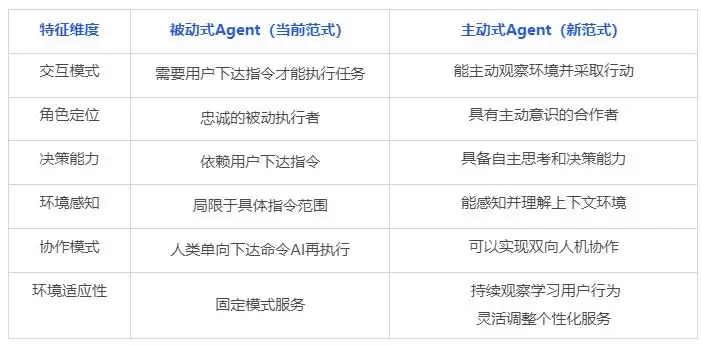
要理解这个技术突破的分量,先得看清两种范式在本质上的区别:
这种主动交互范式在日常生活中的应用潜力相当可观,来看几个近期就能实现的场景:
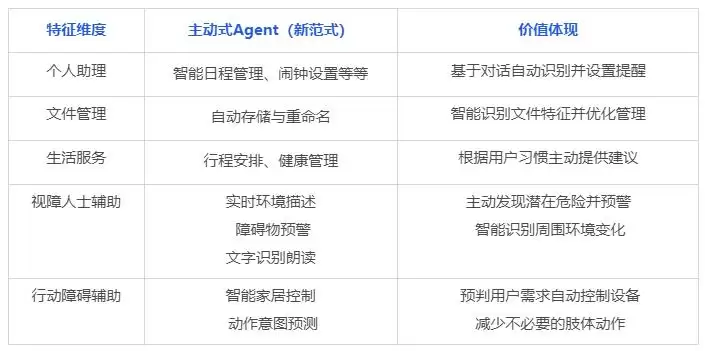
主动 Agent 交互范式应用场景 demo 演示
场景1:一对情侣聊天,男生约女生周六去环球影城,说好早上八点来接。当Agent获得用户授权后,始终保持在线“候命状态”。通过实时识别聊天上下文,它捕捉到女生的需求——在没有任何人明确下指令的情况下,Agent主动帮女生定了一个周日早上七点的闹钟,提醒她起床准备。这个举动,是不是比很多人类伴侣都贴心?
场景2:用户在电脑上收到一份重要文件,比如学习课件或发片。Agent主动帮用户存到本地,还自动识别PDF文件第一页的标题,顺手把文件名给重命名了。整个过程完全静默,用户甚至可能都没注意到,但文件已经被整理得井井有条。
这项研究不光提出了主动Agent的概念,还做了一套更扎实的工作:通过采集不同场景的人类活动数据,搭建了一个环境模拟器,进而构建了数据集ProactiveBench。基于这个数据集,他们训练出与人类判断高度一致的奖励模型,并对比了不同模型的表现。
主动 Agent 技术原理
下图的整体流程揭示了主动Agent的技术内核。为了让智能体能主动提出任务,研究团队设计了三个核心组件,分别模拟环境信息、用户行为和对智能体任务提议的反馈。
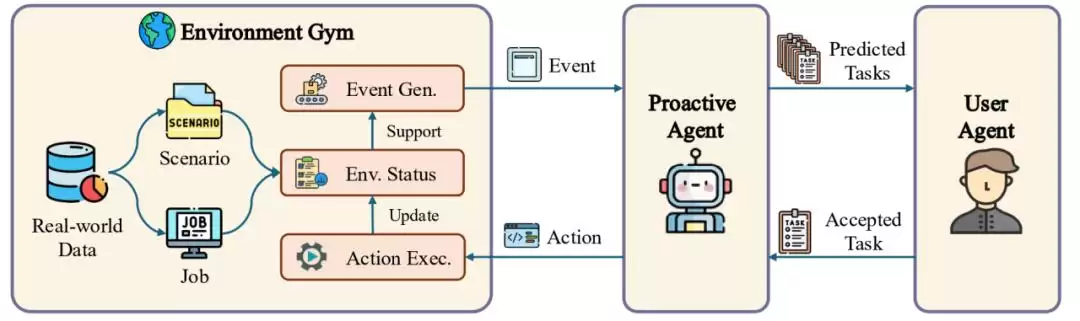
图 2 数据生成过程总览。该过程包含了初始环境与任务设置,事件生成,主动预测,用户判断和行动执行。
具体来说:
环境模拟器为智能体提供了一个沙盒环境。它基于Activity Watcher软件采集的真实人类数据,用来生成逻辑通顺的事件。模拟器的核心功能是事件生成和状态维护:借助GPT-4o从人类标注员收集的种子事件,生成需要交互的具体场景,同时创建所有相关实体供智能体执行任务。它会持续生成事件、更新实体状态、产生反馈,直到场景下没有更多事件可生成。
主动智能体则通过环境模拟器提供的信息预测用户意图,生成任务。每接收一个新事件,它先更新“记忆”,然后结合历史的用户反馈和交互信息,判断是否需要提出任务。如果察觉不到需求,它就保持静默;一旦检测到需要,就会主动提议。而被用户接受的任务,它立刻在模拟器里执行,引发后续一系列事件。
用户智能体负责模拟真实用户的行为,并对主动智能体的任务提议给出反馈。它本质上是经过提示的GPT-4o,在收到预测结果后决定是否接受任务。为了训练这个判断过程,研究团队从人类标注员那里收集了大量数据,训练出一个奖励模型。标注员在专门开发的平台上,对9个不同大语言模型在同一时间点生成的多样化预测进行判断,并通过多数投票决定用户是否有需求、倾向于接受什么任务。值得一提的是,人类标注员在测试集上达成了91.67%的一致性,说明这个测试集的可靠性非常高。
主动 Agent 实验研究
为了衡量奖励模型的可靠性,研究团队设计了一套度量标准:
- 需求遗落(MN):人类标注认为需要帮助,奖励模型却说不需要。
- 静默应答(NR):双方都认为不需要帮助。
- 正确检测(CD):双方都认为需要帮助。
- 错误检测(FD):人类认为不需要,奖励模型却认为需要。
基于这四个指标,计算召回率、精确度、准确度和F1分数。结果很有意思:现有模型在“正确检测”上一片飘红,但其他指标表现就差强人意了——它们倾向于一股脑接受智能体的任务,哪怕这个任务毫无帮助。相比之下,这个研究团队训练的模型综合性能最优,最终被选为ProactiveBench的奖励模型。
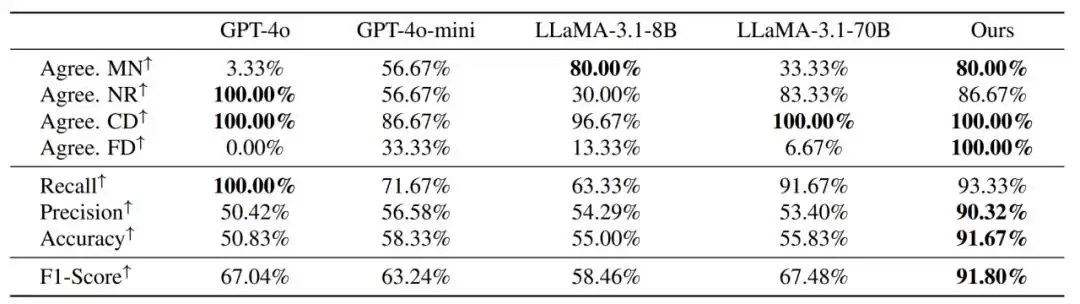
图表 3 不同模型作为奖励模型的评测结果。研究展示了模型与人工标注员多数投票结果之间的一致性。在 LLaMA-3.1-instruct-8B 微调的模型取得了最好结果。
有了奖励模型,就可以进一步衡量主动智能体本身的性能。研究在多个模型上进行了评估,并将预测结果交由奖励模型打分。从结果来看:闭源模型过于“热情”,倾向于主动提出任务,但用户其实并不需要帮助,而且它们给出的任务往往太抽象或不实用,导致误报率偏高。开源模型这边,经过ProactiveBench数据集训练的模型明显更优,验证了数据合成流水线的有效性。训练后的模型误报率显著下降,虽然偶尔仍会提供一些不必要的帮助。
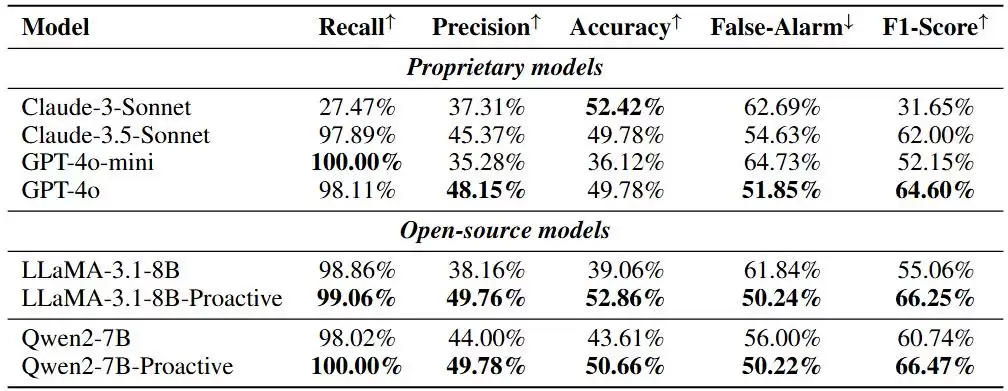
图表 4 不同模型在 ProactiveBench 数据上的评测结果。GPT-4o 在闭源模型中脱颖而出,对于开源模型,基于 Qwen2-7B 微调的结果取得最好成果。
研究还做了消融实验,考察“提出任务的数量”和“用户反馈”对智能体性能的影响。当模型被允许一次提出多个可能任务并逐一判断时,所有模型的指标都明显上升。而引入奖励模型的反馈后,所有模型的误报率下降,准确度提升,但召回率有所回落。综合来看,结合奖励模型的主动智能体,能更精准地检测用户真实需求,同时降低误报率。
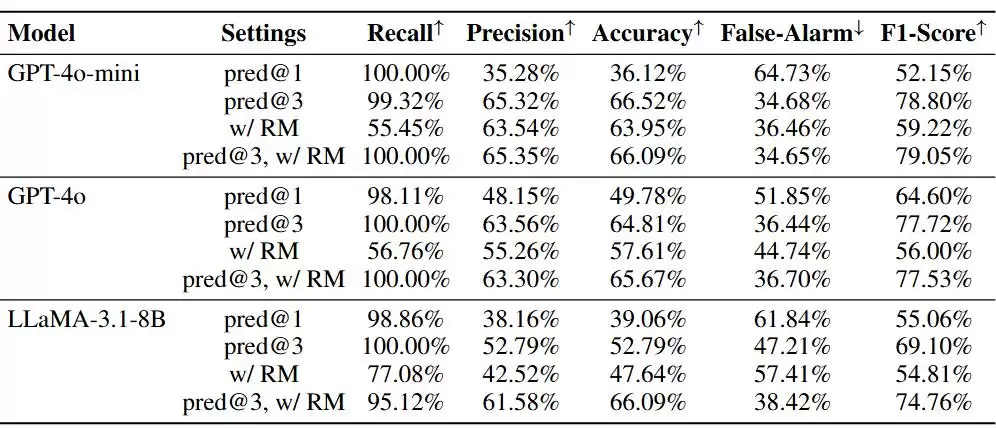
图表 5 基准线,多任务预测,获取反馈之间的比较。结果表明所有的模型都有所提升。模型的误报率由于接受预测的可能性更高或被奖励模型改进而显著下降。
结 语
这项研究提出的主动Agent(ProActive Agent)范式,从根子上改变了人机交互的逻辑——不再把AI当作随时等待指令的工具,而是升级为具备洞察力和主动精神的智能协作者。这背后开启的,是一扇全新的人机交互大门。
技术革新从来不只是技术本身的事。它改变的将是我们与AI的日常相处方式:更自然的协作、更智能的适应能力、更深度的个性化服务。可以预见,随着这个方向的持续推进,一个更包容、更便利的智能化生活环境,正在一点点成为现实。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Continue Windows 本地安装配置教程 2026 最新版 下载地址与环境要求
Continue是面向VSCode与JetBrains的AI编程插件,可连接云端或本地模型。Windows安装需准备编辑器、运行环境与模型服务,配置时应重点处理接口、索引、隐私与性能问题。

Tabnine新手从下载到首次运行保姆级安装教程
Tabnine是面向开发者的AI编程工具,适合在常见代码编辑器中辅助补全代码。安装前需确认环境、账号与编辑器版本,首次运行应完成登录、项目索引、补全测试和隐私设置。

Tabnine安装失败常见报错、日志排查与升级回滚方案
Tabnine安装异常通常与编辑器版本、网络连接、权限、缓存或插件冲突有关。可按环境检查、日志定位、重装清理、版本切换和回滚流程逐步处理,并注意代码隐私与插件来源安全。

Tabnine插件安装配置全流程:浏览器编辑器扩展市场
Tabnine适合在主流编辑器中提供代码补全与生成辅助。安装前需确认官方来源、账号策略和编辑器版本,按扩展市场或离线包方式完成配置,并注意隐私、授权与兼容问题。

Tabnine本地模型运行全攻略:下载配置与性能优化
Tabnine可在本地运行代码补全模型,适合重视代码隐私、网络环境不稳定或企业内网开发场景。配置重点包括版本确认、模型下载、路径设置、资源分配、IDE检查与性能调优。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-02 06:42
2026-07-02 06:41
2026-07-02 06:41
2026-07-02 06:41
2026-07-02 06:41
2026-07-02 06:41
2026-07-02 06:40
2026-07-02 06:40
热门教程
2026-07-02 06:42
2026-07-02 06:41
2026-07-02 06:41
2026-07-02 06:41
2026-07-02 06:41
2026-07-02 06:41
2026-07-02 06:40
2026-07-02 06:40
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
