




本体论与知识图谱区别及Palantir政企落地价值

 ## 一、本体论到底是什么?从哲学概念到干活的工具
很多人第一次听到 “本体论”,第一反应是玄乎 —— 这不就是哲学里研究 “世界本质” 的学问吗?做项目的天天跟数据库、报表打交道,扯这个干嘛?
其实落到计算机和 AI 领域,本体论早就不是哲学概念了,是一套能用、能落地的知识工程方法。
学术界最经典的定义,是学者 Studer 总结的:本体是共享概念化的形式化、显式规范。听着绕,拆成三件事就懂了:
**概念化**:说白了就是给业务场景 “抽架子”。这个领域里有哪几类东西?东西之间有啥固定关系?比如政务监管领域,先抽出 “企业、法人、资质、处罚、项目” 这些核心事物,再定好 “法人在企业任职、企业持有资质” 这类关联,把真实世界的复杂业务,抽象成一套清晰的概念集合。
**显式且形式化**:这点最容易被忽略。这些概念和关系,不能藏在代码逻辑里、埋在数据库表结构里,得明明白白写出来,写成机器能读、能校验的规则。不是开发人员心里有数就行,得是整个系统都认的明规则。
**共享**:它不是某个部门、某个系统的私货,是整个行业、整个领域都认可的语义共识。说白了,就是一套跨部门、跨系统都能用的 “通用业务语言”,你说的 “企业” 和我说的 “企业”,得是一个意思。
总结成大白话:本体论就是特定领域的 “语义规则手册”。它不关心某一家具体企业、某一个具体项目的数据,只管定规矩:这个领域有哪几类事物?事物之间怎么关联?要遵守哪些逻辑?
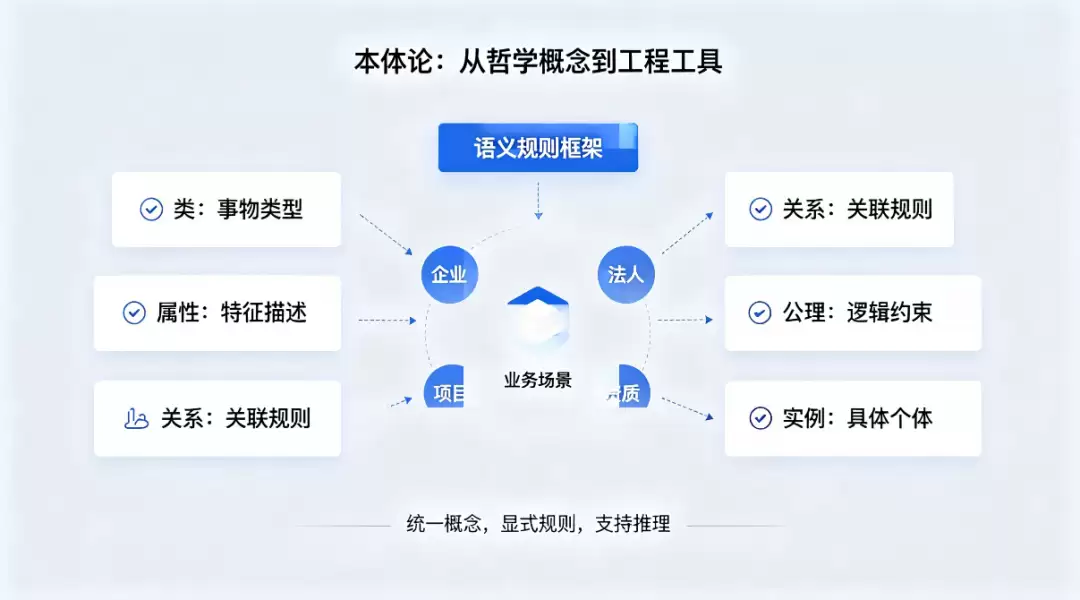
一套能用的领域本体,拆开来就是五件事:
- **类(Class)**:事物的分类,比如人、组织、事件、物品;
- **属性(Property)**:每类事物的特征,比如企业有统一社会信用代码、成立日期;
- **关系(Relation)**:类和类之间的关联,比如企业隶属于某个行业;
- **公理(Axiom)**:逻辑约束和推理规则,比如 “一家企业只能有一个法定代表人”“控股关系是可以传递的”;
- **实例(Instance)**:类下面的具体个体,比如 “某某集团有限公司” 就是 “企业” 这个类的一个实例。
## 一、本体论到底是什么?从哲学概念到干活的工具
很多人第一次听到 “本体论”,第一反应是玄乎 —— 这不就是哲学里研究 “世界本质” 的学问吗?做项目的天天跟数据库、报表打交道,扯这个干嘛?
其实落到计算机和 AI 领域,本体论早就不是哲学概念了,是一套能用、能落地的知识工程方法。
学术界最经典的定义,是学者 Studer 总结的:本体是共享概念化的形式化、显式规范。听着绕,拆成三件事就懂了:
**概念化**:说白了就是给业务场景 “抽架子”。这个领域里有哪几类东西?东西之间有啥固定关系?比如政务监管领域,先抽出 “企业、法人、资质、处罚、项目” 这些核心事物,再定好 “法人在企业任职、企业持有资质” 这类关联,把真实世界的复杂业务,抽象成一套清晰的概念集合。
**显式且形式化**:这点最容易被忽略。这些概念和关系,不能藏在代码逻辑里、埋在数据库表结构里,得明明白白写出来,写成机器能读、能校验的规则。不是开发人员心里有数就行,得是整个系统都认的明规则。
**共享**:它不是某个部门、某个系统的私货,是整个行业、整个领域都认可的语义共识。说白了,就是一套跨部门、跨系统都能用的 “通用业务语言”,你说的 “企业” 和我说的 “企业”,得是一个意思。
总结成大白话:本体论就是特定领域的 “语义规则手册”。它不关心某一家具体企业、某一个具体项目的数据,只管定规矩:这个领域有哪几类事物?事物之间怎么关联?要遵守哪些逻辑?
一套能用的领域本体,拆开来就是五件事:
- **类(Class)**:事物的分类,比如人、组织、事件、物品;
- **属性(Property)**:每类事物的特征,比如企业有统一社会信用代码、成立日期;
- **关系(Relation)**:类和类之间的关联,比如企业隶属于某个行业;
- **公理(Axiom)**:逻辑约束和推理规则,比如 “一家企业只能有一个法定代表人”“控股关系是可以传递的”;
- **实例(Instance)**:类下面的具体个体,比如 “某某集团有限公司” 就是 “企业” 这个类的一个实例。
 很多人做了一辈子数据模型,没摸到本体的门槛,核心差就在 “公理” 上。普通数据模型是 “你存什么,它才有什么”;本体是 “只要给规则,它能自己推出新知识”—— 比如你只存了 “甲控股乙、乙控股丙”,只要定了 “控股可传递” 这条公理,系统自动就能算出 “甲间接控股丙”,不用你提前把数据写死。这才是本体最核心的价值。
## 二、本体论 vs 知识图谱:别再混为一谈了
我见过太多项目,画几张实体关系图,存到图数据库里,就敢叫 “行业知识图谱” 了。你要问它和本体论啥区别,十有八九说不清楚。
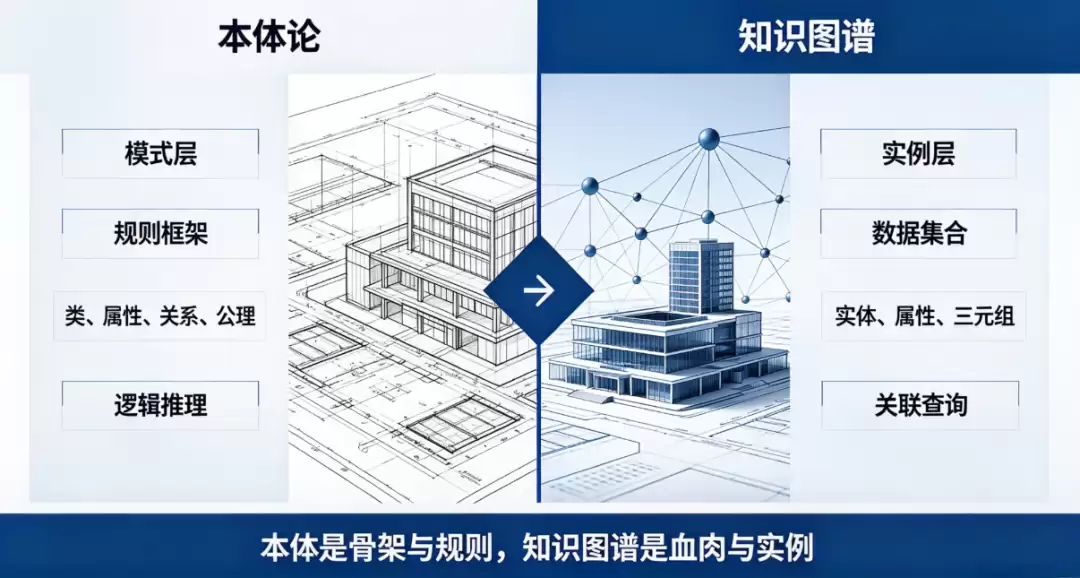
其实二者根本不是一个层面的东西,一句话讲清:**本体是知识图谱的 “骨架和规矩”,知识图谱是本体的 “血肉和实例”。**
具体差别整理成表,一目了然:
" 对比维度 | 本体论(Ontology) | 知识图谱(Knowledge Graph) |
| :--- | :--- | :--- |
| **层级定位** | 模式层(Schema 级),定规则的抽象框架 | 实例层(Data 级),装数据的具体集合 |
| **核心目标** | 统一语义,保证逻辑一致,支持推理 | 聚合实体数据,支持查询、可视化、关联分析 |
| **核心内容** | 类、属性、关系、公理、推理规则,几乎不存具体业务数据 | 海量实体、属性、关系三元组,是本体的实例化填充 |
| **核心能力** | 逻辑推理、一致性校验、语义消歧 | 关联查询、路径分析、知识检索 |
| **常用技术** | OWL、RDFS、Protégé、本体推理机 | Neo4j、NebulaGraph 等图数据库,知识抽取算法,SPARQL |
| **迭代节奏** | 稳定、低频迭代,重点在建模规范和语义校验 | 持续、高频更新,重点在数据生产和业务适配 |
打个最通俗的比方:本体论就是建筑设计蓝图,规定了房子要有几室几厅,水电管线怎么走,哪面是承重墙不能拆;知识图谱就是按这张蓝图盖好的房子,里面摆了家具家电,住了具体的人。
现在行业里一个很大的误区:很多号称 “知识图谱” 的项目,只有一张非常薄的 Schema,连形式化的公理和推理能力都没有,本质就是个 “实体关系图”,根本没摸到本体论的核心价值。
当然二者也不是对立的,是绑定在一起的:没有本体约束的知识图谱,做着做着就成了 “数据乱炖”,同一个概念在不同库里意思全变了,越做越乱;没有知识图谱填充数据的本体,就是一套空规则,也产生不了实际价值。
## 三、Palantir 到底用本体论干成了什么?
本体论不是 Palantir 发明的,学术圈研究了几十年。但 Palantir 是全世界第一个把它在最苛刻的政企场景里,真正工程化、规模化落地的公司。它的两大核心产品 Gotham(做国防政府)和 Foundry(做商业企业),底层最核心的壁垒,就是动态本体(Dynamic Ontology)。
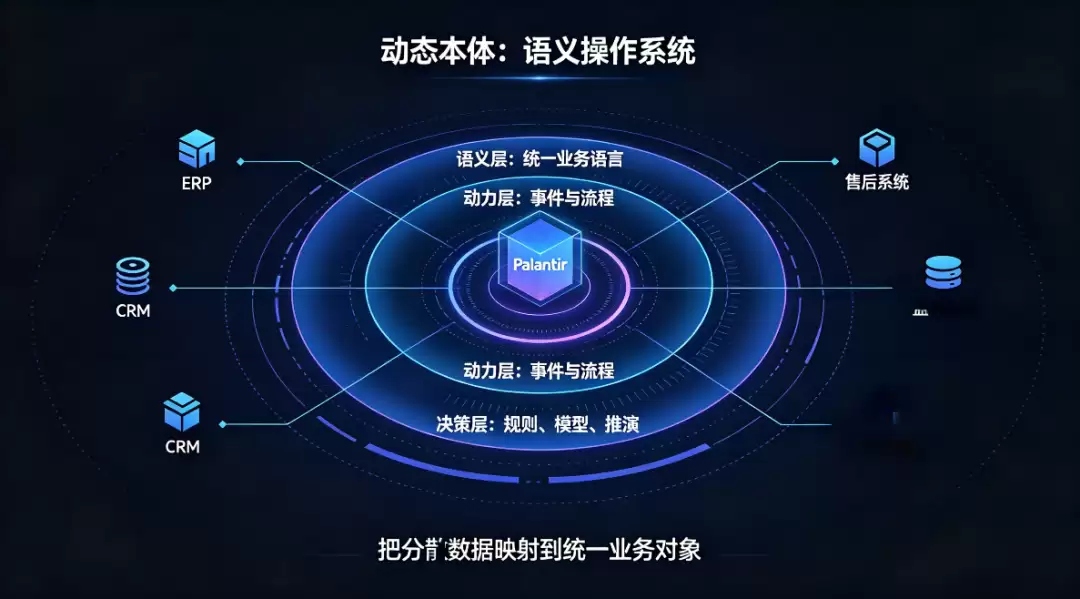
很多人讲 Palantir 的本体,讲得很玄。其实它的核心思路一点都不复杂:没有把本体做成静态的术语表,而是做成了整个系统的 “语义操作系统”,分三层往下落:
**语义层**:先把所有业务里的实体、属性、关系全定义清楚,给所有乱七八糟的异构数据源一套统一的 “业务语言”。比如 ERP 里叫 “客户 ID”,CRM 里叫 “客户编号”,售后系统里叫 “用户编码”,名字不一样没关系,全部映射到本体里的 “客户” 对象上。从根上解决数据孤岛的语义割裂问题。
**动力层**:不只是定静态分类,还要定义实体的动态行为和事件流程 —— 比如订单创建、设备故障、预算审批,这些事件怎么发生、怎么流转,全部写进本体里。这样本体就不是死的分类表,而是能跟真实世界实时同步的数字孪生骨架。
**动态决策层**:业务规则、AI 模型、模拟推演,全部基于这套统一的本体来做。因为底层语义是通的,系统可以直接基于业务对象做判断、执行动作,不用再反复做数据对齐。
说白了,Palantir 用本体论解决了一个最老、最痛的问题:企业和政府分散在几十个系统里的数据,终于能映射到同一套业务对象上了。数据不再是躺在库里的表格,而是变成了系统能理解、能推理、能用来干活的业务资产。
这套东西不是吹出来的,是在全球最严苛的场景里验证了十几年的,举几个最实在的例子:
### 国防情报与反恐:从人工拼数据到智能挖线索
这是 Palantir 的起家业务。美军和情报机构的痛点有多夸张?同一个嫌疑人,信息散在十几个系统里,人员档案、通信记录、车辆信息、监控数据,分属不同部门,格式、定义全不一样。分析师要查一个人,得登七八个系统,导出来的表都对不上,人工拼关系,等拼完线索都凉了。
Palantir 的做法,就是先定义 “人员、组织、事件、地点” 这一套核心本体,把所有异构数据全部往这一套上映射。分析师不用懂 SQL,不用跨系统导数据,直接基于业务对象就能做关联分析,系统还能通过规则推理,挖出隐藏的人员网络和关联线索。能被美军用这么多年,效率提升是实打实的。
### 能源与公用事业:在优化过的基础上再降本 20%
全球工程巨头 Jacobs 跟 Palantir 合作,在一座已经做过一轮优化的水处理厂部署系统,最后硬生生又省了 20% 的电力成本,还消掉了所有运营合规罚款,碳排放也降了。
核心就是本体打通了设备、能耗、工艺、水质这些本来各管一摊的数据,通过推理找到了人工根本发现不了的优化空间。西班牙的光伏企业 Sonnedix 也用这套方案做电站运营,设备停机时间大幅下降。
### 高端制造与赛事:把效率拉到极致
IndyCar 的 Andretti 车队用 Palantir 做了一套 Race OS 赛事操作系统,核心就是赛车领域的本体模型。赛车参数、胎压、赛道数据、天气、车手状态,几十种来源完全不同的数据,全部映射到统一本体上。
带来的结果是:团队 24 小时就能开发出一套新的分析工具,接入一个新数据源只需要 5 天。在分秒必争的赛场上,这种效率就是实打实的优势。空客、BP 这些制造和能源巨头,也都用这套方案打通供应链、生产、运维的数据,做预测性维护和供应链风险管理。
商业上的成功更直接:Palantir 的政府客户留存率接近 100%,用了就离不开。这两年 AI 爆发,本体 + 大模型的组合更是把它的价值放大了 —— 大模型容易胡说八道,本体刚好给它套上业务规矩,从根源上约束幻觉,这刚好戳中了政企 AI 落地的最大痛点。
很多人做了一辈子数据模型,没摸到本体的门槛,核心差就在 “公理” 上。普通数据模型是 “你存什么,它才有什么”;本体是 “只要给规则,它能自己推出新知识”—— 比如你只存了 “甲控股乙、乙控股丙”,只要定了 “控股可传递” 这条公理,系统自动就能算出 “甲间接控股丙”,不用你提前把数据写死。这才是本体最核心的价值。
## 二、本体论 vs 知识图谱:别再混为一谈了
我见过太多项目,画几张实体关系图,存到图数据库里,就敢叫 “行业知识图谱” 了。你要问它和本体论啥区别,十有八九说不清楚。
其实二者根本不是一个层面的东西,一句话讲清:**本体是知识图谱的 “骨架和规矩”,知识图谱是本体的 “血肉和实例”。**
具体差别整理成表,一目了然:
" 对比维度 | 本体论(Ontology) | 知识图谱(Knowledge Graph) |
| :--- | :--- | :--- |
| **层级定位** | 模式层(Schema 级),定规则的抽象框架 | 实例层(Data 级),装数据的具体集合 |
| **核心目标** | 统一语义,保证逻辑一致,支持推理 | 聚合实体数据,支持查询、可视化、关联分析 |
| **核心内容** | 类、属性、关系、公理、推理规则,几乎不存具体业务数据 | 海量实体、属性、关系三元组,是本体的实例化填充 |
| **核心能力** | 逻辑推理、一致性校验、语义消歧 | 关联查询、路径分析、知识检索 |
| **常用技术** | OWL、RDFS、Protégé、本体推理机 | Neo4j、NebulaGraph 等图数据库,知识抽取算法,SPARQL |
| **迭代节奏** | 稳定、低频迭代,重点在建模规范和语义校验 | 持续、高频更新,重点在数据生产和业务适配 |
打个最通俗的比方:本体论就是建筑设计蓝图,规定了房子要有几室几厅,水电管线怎么走,哪面是承重墙不能拆;知识图谱就是按这张蓝图盖好的房子,里面摆了家具家电,住了具体的人。
现在行业里一个很大的误区:很多号称 “知识图谱” 的项目,只有一张非常薄的 Schema,连形式化的公理和推理能力都没有,本质就是个 “实体关系图”,根本没摸到本体论的核心价值。
当然二者也不是对立的,是绑定在一起的:没有本体约束的知识图谱,做着做着就成了 “数据乱炖”,同一个概念在不同库里意思全变了,越做越乱;没有知识图谱填充数据的本体,就是一套空规则,也产生不了实际价值。
## 三、Palantir 到底用本体论干成了什么?
本体论不是 Palantir 发明的,学术圈研究了几十年。但 Palantir 是全世界第一个把它在最苛刻的政企场景里,真正工程化、规模化落地的公司。它的两大核心产品 Gotham(做国防政府)和 Foundry(做商业企业),底层最核心的壁垒,就是动态本体(Dynamic Ontology)。
很多人讲 Palantir 的本体,讲得很玄。其实它的核心思路一点都不复杂:没有把本体做成静态的术语表,而是做成了整个系统的 “语义操作系统”,分三层往下落:
**语义层**:先把所有业务里的实体、属性、关系全定义清楚,给所有乱七八糟的异构数据源一套统一的 “业务语言”。比如 ERP 里叫 “客户 ID”,CRM 里叫 “客户编号”,售后系统里叫 “用户编码”,名字不一样没关系,全部映射到本体里的 “客户” 对象上。从根上解决数据孤岛的语义割裂问题。
**动力层**:不只是定静态分类,还要定义实体的动态行为和事件流程 —— 比如订单创建、设备故障、预算审批,这些事件怎么发生、怎么流转,全部写进本体里。这样本体就不是死的分类表,而是能跟真实世界实时同步的数字孪生骨架。
**动态决策层**:业务规则、AI 模型、模拟推演,全部基于这套统一的本体来做。因为底层语义是通的,系统可以直接基于业务对象做判断、执行动作,不用再反复做数据对齐。
说白了,Palantir 用本体论解决了一个最老、最痛的问题:企业和政府分散在几十个系统里的数据,终于能映射到同一套业务对象上了。数据不再是躺在库里的表格,而是变成了系统能理解、能推理、能用来干活的业务资产。
这套东西不是吹出来的,是在全球最严苛的场景里验证了十几年的,举几个最实在的例子:
### 国防情报与反恐:从人工拼数据到智能挖线索
这是 Palantir 的起家业务。美军和情报机构的痛点有多夸张?同一个嫌疑人,信息散在十几个系统里,人员档案、通信记录、车辆信息、监控数据,分属不同部门,格式、定义全不一样。分析师要查一个人,得登七八个系统,导出来的表都对不上,人工拼关系,等拼完线索都凉了。
Palantir 的做法,就是先定义 “人员、组织、事件、地点” 这一套核心本体,把所有异构数据全部往这一套上映射。分析师不用懂 SQL,不用跨系统导数据,直接基于业务对象就能做关联分析,系统还能通过规则推理,挖出隐藏的人员网络和关联线索。能被美军用这么多年,效率提升是实打实的。
### 能源与公用事业:在优化过的基础上再降本 20%
全球工程巨头 Jacobs 跟 Palantir 合作,在一座已经做过一轮优化的水处理厂部署系统,最后硬生生又省了 20% 的电力成本,还消掉了所有运营合规罚款,碳排放也降了。
核心就是本体打通了设备、能耗、工艺、水质这些本来各管一摊的数据,通过推理找到了人工根本发现不了的优化空间。西班牙的光伏企业 Sonnedix 也用这套方案做电站运营,设备停机时间大幅下降。
### 高端制造与赛事:把效率拉到极致
IndyCar 的 Andretti 车队用 Palantir 做了一套 Race OS 赛事操作系统,核心就是赛车领域的本体模型。赛车参数、胎压、赛道数据、天气、车手状态,几十种来源完全不同的数据,全部映射到统一本体上。
带来的结果是:团队 24 小时就能开发出一套新的分析工具,接入一个新数据源只需要 5 天。在分秒必争的赛场上,这种效率就是实打实的优势。空客、BP 这些制造和能源巨头,也都用这套方案打通供应链、生产、运维的数据,做预测性维护和供应链风险管理。
商业上的成功更直接:Palantir 的政府客户留存率接近 100%,用了就离不开。这两年 AI 爆发,本体 + 大模型的组合更是把它的价值放大了 —— 大模型容易胡说八道,本体刚好给它套上业务规矩,从根源上约束幻觉,这刚好戳中了政企 AI 落地的最大痛点。
 ## 四、我们做政企应用,本体论能解决啥真问题?
很多人会说,Palantir 是美国的,那套东西在国内适用吗?恰恰相反。政企场景刚好是本体论价值最突出的地方 —— 国内政企数字化的几个老大难问题,刚好都是本体论的拿手好戏。
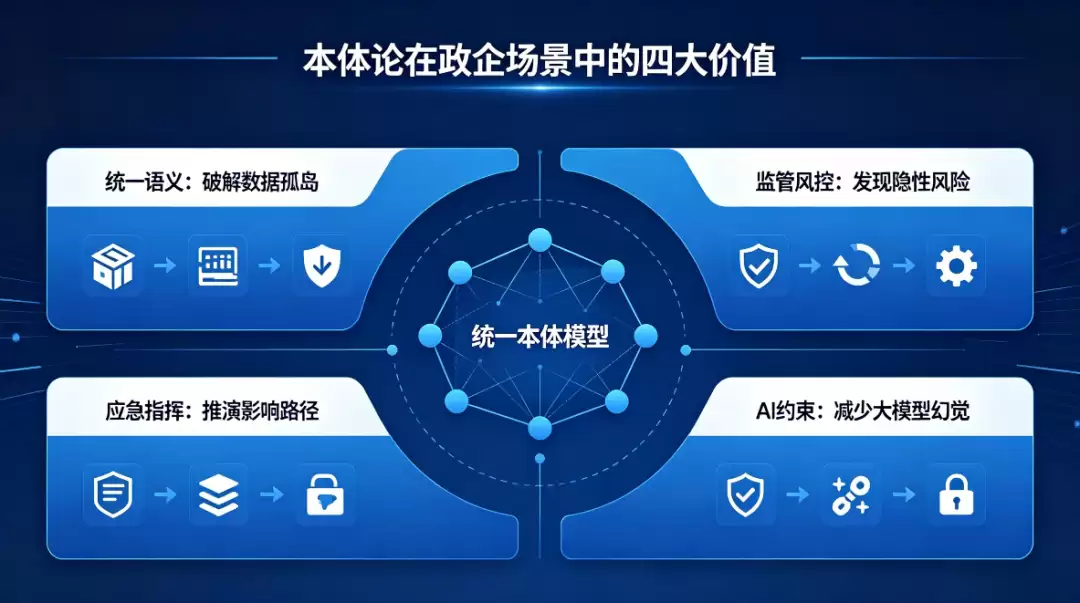
具体来说,至少能解决四类核心痛点:
### 1. 破解跨部门数据孤岛:真的让数据 “通” 起来
政企数字化喊了这么多年数据打通,大多只做到了 “物理汇聚”:数据从各个部门挪到一个平台、一个库里了,但语义根本没对齐。
工商叫 “企业”,税务叫 “纳税人”,社保叫 “参保单位”,看着说的是一回事,真要拉个统计数,三个部门三个结果。同一个指标,不同部门的统计口径天差地别,最后跨部门分析,还是得靠大量人工对账、对齐口径。
传统数据中台、共享平台,解决的都是 “数据放哪” 的问题,解决不了 “数据说的是啥” 的问题。而本体论就是干这个的:给整个领域搭一套统一的语义底座,所有部门的数据都映射到同一套概念上,做到 “同名同义、同义同名”。跨部门共享数据、做分析,不用再反复对齐口径。
比如文旅领域,把 “景区、游客、文旅企业、文旅项目、文旅资金” 这些核心概念的定义全统一了,不同司局的数据自然就能打通,全行业的数据治理和分析才能真正跑通。
### 2. 智能监管与合规风控:挖出隐性的风险
政企场景有大量监管、合规需求,传统做法大多是人工核查、事后追溯,效率低,漏得多。
本体论的优势,是能靠逻辑传导推理,从海量数据里自动挖出隐性的关联风险。比如国资监管,股权关系绕好几层,代持、隐形关联交易,靠人工查根本查不过来。只要把股权传递的规则写进本体,系统自动就能顺着股权链推理,识别出隐蔽的关联关系,防范国有资产流失。再比如市场监管,无证经营、超范围经营、异常关联企业,都可以通过本体规则自动识别,监管精准度能提一大截。还有合规审查,把政策法规、内控规则转化成本体公理,业务操作自动过规则校验,违规的直接拦截,把合规从事后挪到事前。
跟普通的规则引擎比,本体的核心优势是能顺着关系链做传导推理,不是只判断单条数据合不合规,而是能挖出绕了好几层的隐性风险,这是传统规则引擎做不到的。
### 3. 应急指挥与决策推演:看清影响传导链路
应急管理、城市治理这类场景,决策最难的地方,是看不清事件的影响范围和传导路径。
本体论相当于给城市、给领域搭了一套数字孪生的语义骨架,把事件、对象、资源之间的依赖关系全刻画清楚。突发事件一发生,系统自动就能推理出影响会怎么传导:比如某条主干道封路,会影响哪些公交线路、哪些园区通勤、哪些应急物资的运输路线。
还能做多方案的模拟推演:调不同的应急资源,分别能覆盖多大范围、有什么短板,帮指挥的人快速做最优决策。
### 4. 大模型政企落地的 “业务安全带”
大模型在政企落地,最大的坎就是两个:幻觉,还有不懂业务。生成的内容不符合业务规则、数据口径不对,甚至违反合规要求,根本不敢直接用。
本体论刚好是解决这个问题的最佳底座:一方面,给大模型提供标准的业务术语和统计口径,不会出现 “同一个指标好几个说法” 的问题;另一方面,大模型的所有输出,都可以先过一遍本体的规则校验,不符合业务逻辑、不合规的内容直接拦掉;更重要的是,让大模型基于本体的业务对象去调用系统能力,而不是直接调 API,稳定性和安全性能提升一大截。
说白了,大模型负责 “能说会道”,本体论负责 “说的都对、做的合规”,俩凑到一起,才是政企能用的 AI。
## 四、我们做政企应用,本体论能解决啥真问题?
很多人会说,Palantir 是美国的,那套东西在国内适用吗?恰恰相反。政企场景刚好是本体论价值最突出的地方 —— 国内政企数字化的几个老大难问题,刚好都是本体论的拿手好戏。
具体来说,至少能解决四类核心痛点:
### 1. 破解跨部门数据孤岛:真的让数据 “通” 起来
政企数字化喊了这么多年数据打通,大多只做到了 “物理汇聚”:数据从各个部门挪到一个平台、一个库里了,但语义根本没对齐。
工商叫 “企业”,税务叫 “纳税人”,社保叫 “参保单位”,看着说的是一回事,真要拉个统计数,三个部门三个结果。同一个指标,不同部门的统计口径天差地别,最后跨部门分析,还是得靠大量人工对账、对齐口径。
传统数据中台、共享平台,解决的都是 “数据放哪” 的问题,解决不了 “数据说的是啥” 的问题。而本体论就是干这个的:给整个领域搭一套统一的语义底座,所有部门的数据都映射到同一套概念上,做到 “同名同义、同义同名”。跨部门共享数据、做分析,不用再反复对齐口径。
比如文旅领域,把 “景区、游客、文旅企业、文旅项目、文旅资金” 这些核心概念的定义全统一了,不同司局的数据自然就能打通,全行业的数据治理和分析才能真正跑通。
### 2. 智能监管与合规风控:挖出隐性的风险
政企场景有大量监管、合规需求,传统做法大多是人工核查、事后追溯,效率低,漏得多。
本体论的优势,是能靠逻辑传导推理,从海量数据里自动挖出隐性的关联风险。比如国资监管,股权关系绕好几层,代持、隐形关联交易,靠人工查根本查不过来。只要把股权传递的规则写进本体,系统自动就能顺着股权链推理,识别出隐蔽的关联关系,防范国有资产流失。再比如市场监管,无证经营、超范围经营、异常关联企业,都可以通过本体规则自动识别,监管精准度能提一大截。还有合规审查,把政策法规、内控规则转化成本体公理,业务操作自动过规则校验,违规的直接拦截,把合规从事后挪到事前。
跟普通的规则引擎比,本体的核心优势是能顺着关系链做传导推理,不是只判断单条数据合不合规,而是能挖出绕了好几层的隐性风险,这是传统规则引擎做不到的。
### 3. 应急指挥与决策推演:看清影响传导链路
应急管理、城市治理这类场景,决策最难的地方,是看不清事件的影响范围和传导路径。
本体论相当于给城市、给领域搭了一套数字孪生的语义骨架,把事件、对象、资源之间的依赖关系全刻画清楚。突发事件一发生,系统自动就能推理出影响会怎么传导:比如某条主干道封路,会影响哪些公交线路、哪些园区通勤、哪些应急物资的运输路线。
还能做多方案的模拟推演:调不同的应急资源,分别能覆盖多大范围、有什么短板,帮指挥的人快速做最优决策。
### 4. 大模型政企落地的 “业务安全带”
大模型在政企落地,最大的坎就是两个:幻觉,还有不懂业务。生成的内容不符合业务规则、数据口径不对,甚至违反合规要求,根本不敢直接用。
本体论刚好是解决这个问题的最佳底座:一方面,给大模型提供标准的业务术语和统计口径,不会出现 “同一个指标好几个说法” 的问题;另一方面,大模型的所有输出,都可以先过一遍本体的规则校验,不符合业务逻辑、不合规的内容直接拦掉;更重要的是,让大模型基于本体的业务对象去调用系统能力,而不是直接调 API,稳定性和安全性能提升一大截。
说白了,大模型负责 “能说会道”,本体论负责 “说的都对、做的合规”,俩凑到一起,才是政企能用的 AI。
 ## 最后说几句实在的
本体论不是什么新鲜概念,在计算机领域发展了三十多年了。过去一直没火起来,就是因为太重了:建一套领域本体,要业务专家、知识工程专家一起磨很久,成本高,见效慢,很少有甲方愿意为这个买单。
但现在情况变了。一方面,政企数字化从 “建系统、汇数据” 的阶段,走到了 “用数据、做智能” 的深水区。光堆数据没用了,数据语义不通、逻辑不一致,越堆越乱。本体论刚好能解决这个根上的问题。另一方面,大模型爆发了。大家都想做大模型落地,但幻觉和业务理解的坎过不去,而本体刚好能给大模型做业务约束,补上这块短板。
但也不用把本体论神化,它不是银弹。做政企项目,千万别上来就想搞全领域、大而全的本体,大概率会做成烂尾工程。最务实的路径,是从一个核心业务场景切入,比如先做国资监管、或者跨部门数据共享这一个点,把本体做深做透,真的解决一个问题,再慢慢往外扩。
毕竟,技术概念炒得再热,最后都得落到解决实实在在的业务问题上。
## 最后说几句实在的
本体论不是什么新鲜概念,在计算机领域发展了三十多年了。过去一直没火起来,就是因为太重了:建一套领域本体,要业务专家、知识工程专家一起磨很久,成本高,见效慢,很少有甲方愿意为这个买单。
但现在情况变了。一方面,政企数字化从 “建系统、汇数据” 的阶段,走到了 “用数据、做智能” 的深水区。光堆数据没用了,数据语义不通、逻辑不一致,越堆越乱。本体论刚好能解决这个根上的问题。另一方面,大模型爆发了。大家都想做大模型落地,但幻觉和业务理解的坎过不去,而本体刚好能给大模型做业务约束,补上这块短板。
但也不用把本体论神化,它不是银弹。做政企项目,千万别上来就想搞全领域、大而全的本体,大概率会做成烂尾工程。最务实的路径,是从一个核心业务场景切入,比如先做国资监管、或者跨部门数据共享这一个点,把本体做深做透,真的解决一个问题,再慢慢往外扩。
毕竟,技术概念炒得再热,最后都得落到解决实实在在的业务问题上。 
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

内网RPA离线部署从依赖打包到7×24无人值守踩坑与避坑方案
这三年,内网RPA项目接了不下二十个。每次开局都像闯关——断网、缺依赖、多机同步、定时执行、批量分发、源码保护、AI离线化,八个坑一个比一个深。今天把这些实战经验整理出来,希望能帮正在内网搞自动化的兄弟们少踩点雷。 一、内网无网络环境怎么部署RPA流程:先搞清楚什么叫“真离线” 很多工具宣传“支持本

水利工程师用WorkBuddy写洪水报告效率提升3倍
WorkBuddy开发者分享季 水利工程师AI提效实战:用WorkBuddy撰写洪水影响评价报告,效率提升3倍 WorkBuddy 效率 人工智能 开发工具 一、我是谁,为什么需要AI 先介绍一下自己——我是一名水利工程师,在湖南长沙的一家小型水利设计公司任职。当前行业环境不太

日志服务数据加工规则洞察仪表盘使用指南
数据加工诊断仪表盘 想实时掌握日志服务加工功能的运行状态?直接从加工列表页点击那个“规则洞察”按钮,仪表盘就会立刻呈现出来。入口就在那儿,不绕弯子。 跳转后,你可以按作业名称、实例ID或源LogStore来筛选任务状态。比如下边这张图,展示的是当前实例ID(90c9d47714dbb807d47c1

基于RFID的固定资产管理系统技术架构与工程实践
固定资产管理难题是众多企事业单位的普遍困扰,资产数量动辄数千件,且广泛分布于不同部门、楼层乃至园区。传统人工盘点方式在工程维度上始终面临三大关键瓶颈:采集效率低下、数据闭环中断、状态同步滞后。使用条码枪逐一扫描标签,识别距离通常不超过30厘米,操作人员需逐个寻找并扫描,盘点效率完全受限于人力。面对5

WorkBuddy实战用AI搭建A股智能盯盘助手省心高效
炒股的朋友们想必都深有体会——每天重复盯盘、查行情、分析板块轮动,这一整套流程下来耗费大量精力。手动翻查数据不仅身心俱疲,还很容易错过关键买卖节点。今天我们就来聊聊如何打造一款趁手的盯盘工具,借助AI替你分担这些重复性工作。 背景:盯盘的核心痛点 股民都有同感——每天不只要查询单只股票的实时行情,还








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-02 12:28
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:26
2026-07-02 12:26
热门教程
2026-07-02 12:28
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:27
2026-07-02 12:26
2026-07-02 12:26
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
