




CubeAttn-X技术打破固有范式实现最高83%内存节约及45%LRR提升

在探索高效长上下文架构的过程中,一个颠覆直觉的发现正在挑战我们对注意力机制的传统认知。
先来看这张关键对比图
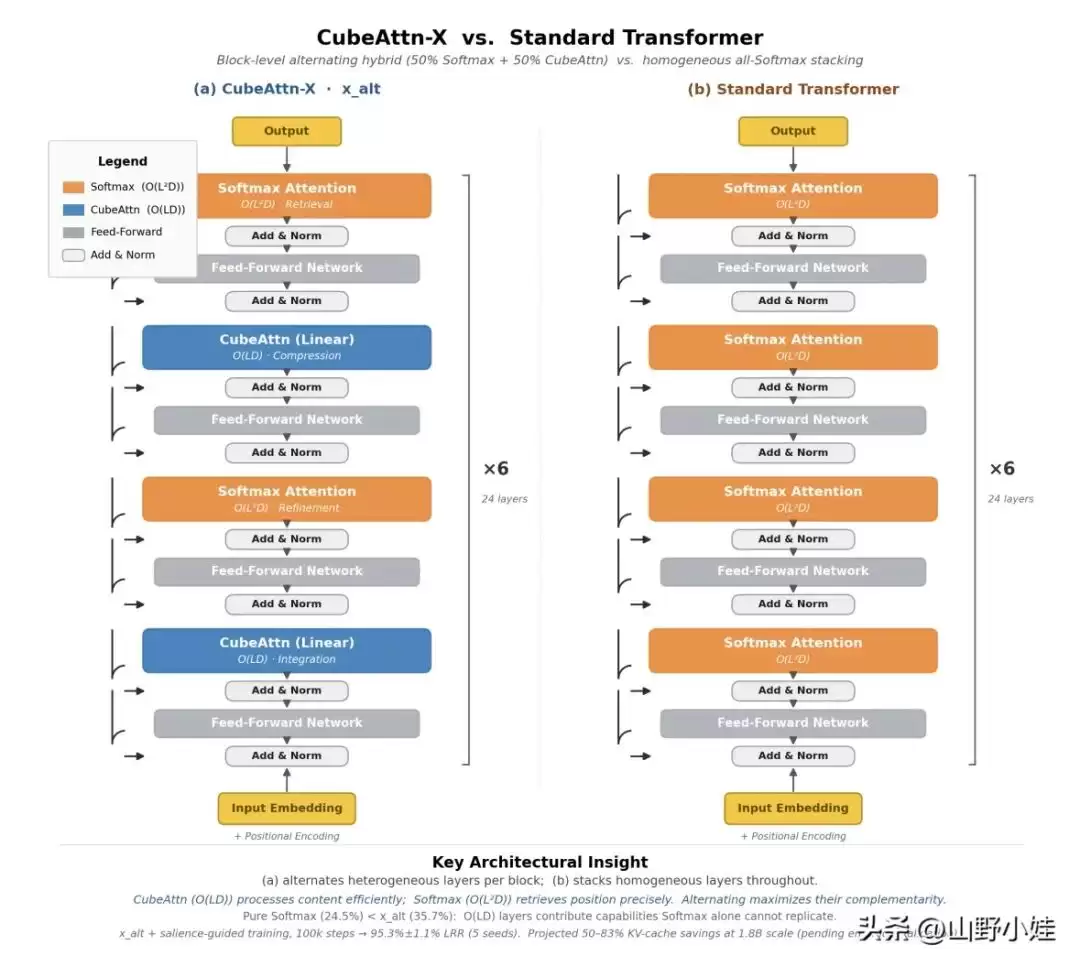
CubeAttn-X 与标准 Transformer 的架构对比
左侧为 CubeAttn-X(x_alt 变体),在 4 层结构中交替排列 CubeAttn(线性注意力,复杂度 O(LD))与标准 Softmax 注意力(复杂度 O(L²D))。右侧为标准 Transformer,4 层全部采用 Softmax 注意力。
直觉上,右侧架构使用了翻倍的 Softmax 层,理应带来更优的性能。然而,实验数据指向了截然相反的结论:
| 架构类型 | Softmax 层数 | 长程检索准确率(LRR) |
|---|---|---|
| 纯 CubeAttn | 0 / 4 | 8.7% |
| CubeAttn-X(交替排列) | 2 / 4 | 35.7% |
| 纯 Softmax(标准 Transformer) | 4 / 4 | 24.5% |
Softmax 层数增加一倍,准确率反而大幅降低 11 个百分点——这是本研究中最反直觉的核心发现。
为何如此?两种注意力机制各司其职
长程检索(Long-Range Retrieval, LRR)任务表面上是一个整体操作,实则分解为两个子任务:
- 内容匹配:识别查询 token 与序列中哪个 key token 对应同一位置
- 位置检索:定位该 key 后,提取其邻近的 value 信息
核心洞见在于:两种注意力机制恰好各有所长。
- CubeAttn(线性注意力,O(LD))擅长内容匹配。它将所有 token 压缩为一个全局状态,查询在此状态中通过“共振”找到匹配内容。效率高,但会丢失精确位置信息。
- Softmax(O(L²D))擅长位置检索。它逐位置计算点积,能够精确定位“所需信息所在的位置”。精度高,但计算成本高昂。
纯 Softmax 架构的问题在于,它必须用同一套机制同时处理这两个任务,导致梯度相互干扰——内容匹配追求压缩与不变性,而位置检索则需要精确的位置交互,两者在同一 Softmax 层内形成冲突。
混合架构则将两个子任务分配给各自擅长的机制:CubeAttn 层负责判断“是否为所需内容”,Softmax 层负责定位“该内容位于何处”。各司其职,互不干扰。
这正是图中左侧架构能够超越右侧的根本原因——并非为了节省计算而妥协,而是通过更智能的分工实现性能提升。
不仅在于“交替”,“如何交替”同样至关重要
图中 CubeAttn-X 采用了交替排列(C-S-C-S),而非将 Softmax 集中在首尾两端(S-C-C-S)。这并非随意安排——在相同比例下,两种排列方式的性能差异显著:
| 排列方式 | 结构 | 长程检索准确率(LRR) |
|---|---|---|
| 首尾式(聚类排列) | S-C-C-S | 25.7% |
| 交替式 | C-S-S-C | 35.7% |
同样是 50% 的 Softmax 比例,交替排列比首尾排列高出近 10 个百分点。
原因在于:交替排列使两层形成了“压缩—检索—压缩—检索”的循环——每个 CubeAttn 层接收来自 Softmax 层精炼后的位置信息再进行压缩,每个 Softmax 层则接收 CubeAttn 层的内容表示再进行检索。而首尾排列中,中间两个连续的 CubeAttn 层缺乏 Softmax 的反馈,第二轮压缩过程中位置信息逐渐丢失,形成了信息瓶颈。
层与层之间的关系,比层的数量更为关键。这是图中未直接呈现、但同样重要的结论。
对实际部署的意义:KV-cache 节省 50% 至 83%
混合架构的真正价值在推理阶段得以兑现。以 1.8B 参数模型(24 层、32K 上下文长度)为例:
| 配置方案 | Softmax 层数 | KV-cache 内存占用 | 相比纯 Transformer 节省比例 |
|---|---|---|---|
| 纯 Transformer | 24 | 约 6.0 GB | 0% |
| CubeAttn-X(交替排列) | 12 | 约 3.0 GB | 50% |
| CubeAttn-X(效率模式) | 6 | 约 1.5 GB | 75% |
| CubeAttn-X(极致节省模式) | 4 | 约 1.0 GB | 83% |
(注:上表中 LRR 性能与内存节省为预测值,其中 4 层合成任务上 35.7% 的准确率已通过实测验证。)
线性注意力层使用 O(D) 状态,相较于 Softmax 的 O(LD) KV-cache 几乎可忽略不计。因此,每减少一层 Softmax,推理内存占用就显著降低,而检索能力则通过交替排列得以保持。
这对长上下文应用场景(如 RAG、长文档理解、Agent 多轮记忆)带来了直接优势——在相同显存条件下,可支持更长的上下文处理能力。
这张架构图传递的,实则是一个更宏大的判断
回顾开头的架构对比图,它不仅展示了我们架构的优越性,更传达了一个核心判断:
过去几年的主流叙事是“线性注意力表现不佳,必须依赖 Softmax 或回归稀疏注意力”。而这张图及其数据提供了另一条路径:不必纠结于谁取代谁,而是思考如何分工协作。一个最少仅使用 1 层 Softmax(4 层中 1 层)的混合架构,就能将长程检索准确率从 8.7% 提升至 25.5%,是纯线性注意力的近 3 倍——而节省下来的 Softmax 层则全部转化为内存红利。
混合并非妥协,而是一种范式转变。
一句话总结
采用一半 Softmax 与一半线性注意力交替排列的结构,比纯 Transformer 更精准、更省内存。这并非因为线性注意力突然变得更强,而是因为我们终于让两种机制回归各自最擅长的领域。
图中那个 C-S-C-S 的循环模式,正蕴含着下一代高效长上下文架构的潜在答案。
备注:本文基于学术研究论文创作:Training Dynamics, Kernel Failure Modes, and Seed Sensitivity in Linear Attention

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

内网RPA离线部署从依赖打包到7×24无人值守踩坑与避坑方案
这三年,内网RPA项目接了不下二十个。每次开局都像闯关——断网、缺依赖、多机同步、定时执行、批量分发、源码保护、AI离线化,八个坑一个比一个深。今天把这些实战经验整理出来,希望能帮正在内网搞自动化的兄弟们少踩点雷。 一、内网无网络环境怎么部署RPA流程:先搞清楚什么叫“真离线” 很多工具宣传“支持本

水利工程师用WorkBuddy写洪水报告效率提升3倍
WorkBuddy开发者分享季 水利工程师AI提效实战:用WorkBuddy撰写洪水影响评价报告,效率提升3倍 WorkBuddy 效率 人工智能 开发工具 一、我是谁,为什么需要AI 先介绍一下自己——我是一名水利工程师,在湖南长沙的一家小型水利设计公司任职。当前行业环境不太

日志服务数据加工规则洞察仪表盘使用指南
数据加工诊断仪表盘 想实时掌握日志服务加工功能的运行状态?直接从加工列表页点击那个“规则洞察”按钮,仪表盘就会立刻呈现出来。入口就在那儿,不绕弯子。 跳转后,你可以按作业名称、实例ID或源LogStore来筛选任务状态。比如下边这张图,展示的是当前实例ID(90c9d47714dbb807d47c1

基于RFID的固定资产管理系统技术架构与工程实践
固定资产管理难题是众多企事业单位的普遍困扰,资产数量动辄数千件,且广泛分布于不同部门、楼层乃至园区。传统人工盘点方式在工程维度上始终面临三大关键瓶颈:采集效率低下、数据闭环中断、状态同步滞后。使用条码枪逐一扫描标签,识别距离通常不超过30厘米,操作人员需逐个寻找并扫描,盘点效率完全受限于人力。面对5

WorkBuddy实战用AI搭建A股智能盯盘助手省心高效
炒股的朋友们想必都深有体会——每天重复盯盘、查行情、分析板块轮动,这一整套流程下来耗费大量精力。手动翻查数据不仅身心俱疲,还很容易错过关键买卖节点。今天我们就来聊聊如何打造一款趁手的盯盘工具,借助AI替你分担这些重复性工作。 背景:盯盘的核心痛点 股民都有同感——每天不只要查询单只股票的实时行情,还








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-02 12:13
2026-07-02 12:12
2026-07-02 12:12
2026-07-02 12:12
2026-07-02 12:12
2026-07-02 12:12
2026-07-02 12:11
2026-07-02 12:11
热门教程
2026-07-02 12:13
2026-07-02 12:12
2026-07-02 12:12
2026-07-02 12:12
2026-07-02 12:12
2026-07-02 12:12
2026-07-02 12:11
2026-07-02 12:11
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
