




苹果AI新突破:大模型指导小模型精准执行复杂指令

8 月 26 日消息,科技媒体 9to5Mac 昨日(8 月 25 日)发布博文,报道称苹果研究人员在最新论文中提出“基于清单反馈的强化学习”(RLCF)方法,用任务清单替代传统人类点赞 点踩
8月26日,知名科技媒体9to5Mac发布最新研究报告,苹果科研团队创新性地提出"基于清单反馈的强化学习"(RLCF)训练方法。与传统依赖简单点赞/点踩的人类反馈机制不同,这项突破性技术通过详尽的任务清单对大语言模型(LLMs)进行精准指导,使其复杂指令处理能力获得质的飞跃。
注:RLCF全称Reinforcement Learning from Checklist Feedback,摒弃了传统RLHF(人类反馈强化学习)的粗放评分模式,转而针对每条指令生成包含具体评分细则的检查清单,以0-100分的精细化评估体系驱动模型迭代优化。
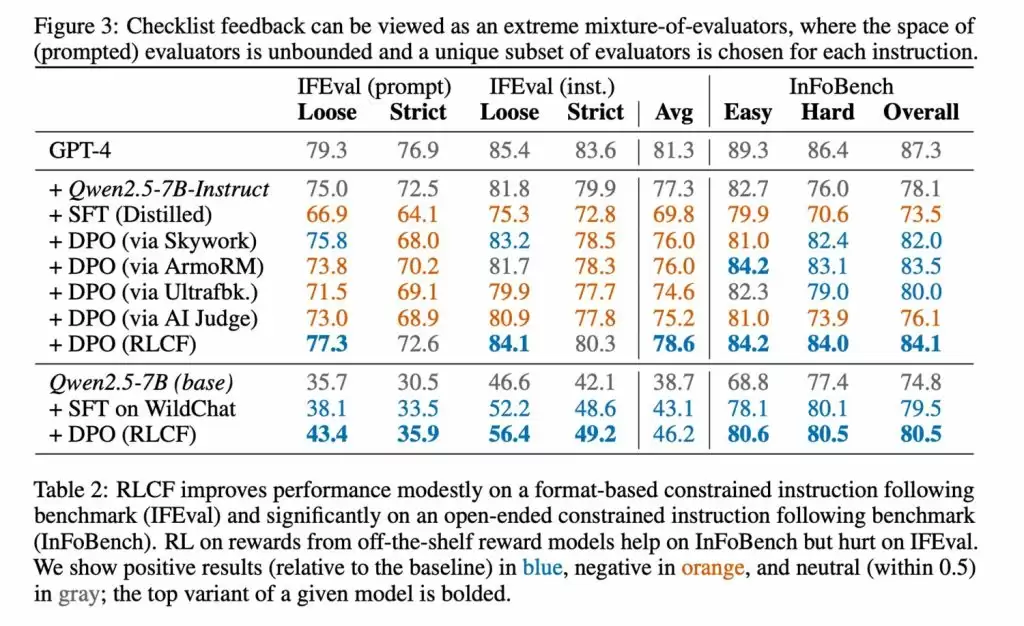
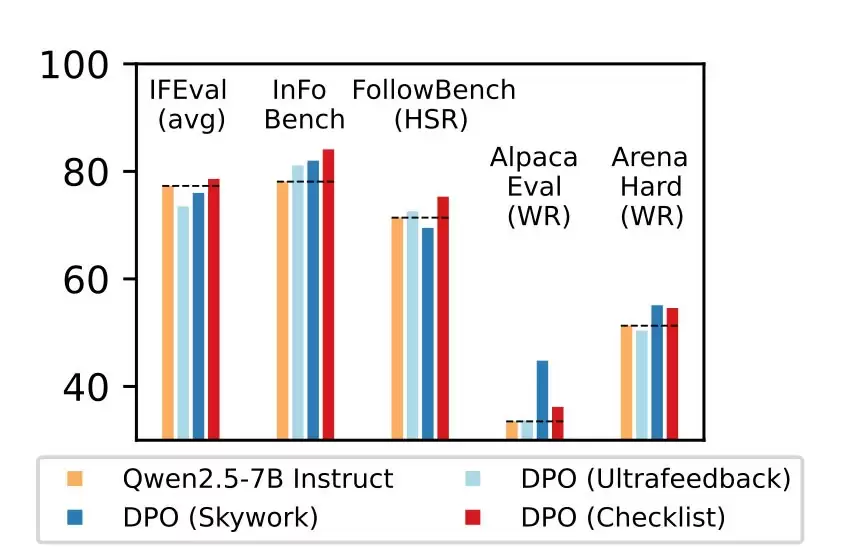
研究团队在Qwen2.5-7B-Instruct模型上进行了严谨测试,覆盖五大主流评测基准。数据显示,RLCF是唯一在所有测试环节均呈现显著效果提升的方案:
- FollowBench评估中硬性指标满意度提升4%
- InFoBench测试得分增长6个百分点
- Arena-Hard对战胜率提高3%
- 特定任务场景最大优化幅度达8.2%
这些数据充分验证了清单反馈机制在处理多步骤复杂指令时的卓越表现。
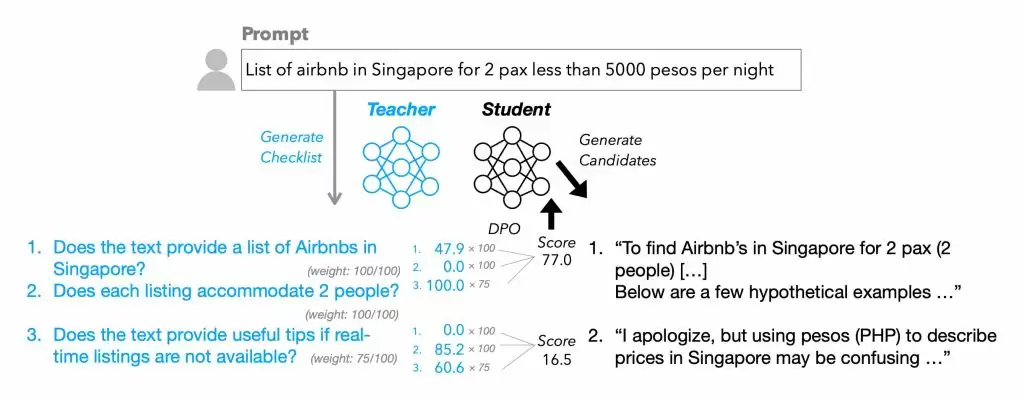
这项技术的另一大亮点是其创新的清单生成流程。研究团队借助性能更强的Qwen2.5-72B-Instruct模型,结合前沿方法论,为13万条训练指令构建了"WildChecklists"专业数据集。每份清单包含系列二元判定项(如"是否完成西班牙语翻译?"),由大模型对答复进行逐项评分并加权计算,最终转化为训练信号传递给待优化模型。
苹果研究人员也客观指出了当前方案的局限性。首先,该方法需要依赖更强大的辅助模型进行评估,在资源受限环境下可能难以实施;其次,RLCF主要聚焦指令执行能力的提升,并非为安全对齐而设计,因此不能替代专门的安全评估流程。该方法在其他任务类型中的普适性仍需后续研究验证。


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

高刷显示器提升FPS游戏命中率,LG Display研究证实
LGDisplay研究显示,31名玩家在60Hz至480Hz刷新率下测试第一人称射击游戏。对比60Hz,480HzOLED显示器命中率提升约38%,其中60Hz升至240Hz提升最为显著,再升至480Hz再增约10%,输入延迟减少超过10毫秒。

年确认不插入闰秒,距上次调整已10年
国际地球自转和参考系服务宣布2026年末不插入闰秒,距上次调整已隔十年。闰秒用于协调原子时与地球自转时,已调整27次均为正闰秒。因气候变化导致地球自转减速,首个负闰秒推迟至2029年,国际计量界计划2035年前废止闰秒机制。

红米Note 17 Pro首销活动送电池升级保五年免费换新
REDMINote17Pro首发提供五年电池升级保障:前四年电池健康低于80%免费换新,第五年升级为更大容量电池。内置9000mAh电池,支持67W快充与22 5W反向充电,配备康宁大猩猩Victus2玻璃及四重防水认证,防护规格对标旗舰。

三星A18渲染图曝光 机身变厚或搭载6000mAh电池
据悉,三星A18最新渲染图曝光,其机身厚度增至7 84毫米,较上一代增加0 34毫米,推测或为配备6000毫安时大容量电池。此外,外观延续水滴屏设计,后置三摄模组有微调,并且底部配备USB-C接口,还支持快速充电功能。

三星S26像素级防窥屏幕隐私保护再升级
三星GalaxyS26系列搭载像素级隐私显示技术,从硬件层面控制OLED子像素发光方向,实现物理级防窥,正面观看画质无损,侧面超60°即模糊。该功能深度集成OneUI8 5,支持智能场景触发和多档位强度调节,与Knox安全平台形成防护体系,无需贴膜,不损画质。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
热门教程
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















