




扎克伯格的豪赌初见成效?Meta新方法让LLM长上下文处理提速30倍

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。 近期,Meta Superintelligence Labs 联合提出了一个名为 REFRAG 的高效解码框架,旨在解决 LLM 在
经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。

近期,Meta Superintelligence Labs 联合提出了一个名为 REFRAG 的高效解码框架,旨在解决 LLM 在处理长上下文输入时面临的效率瓶颈,尤其是在 RAG 等应用场景下。

论文标题:REFRAG:Rethinking RAG based Decoding
论文地址:https://arxiv.org/abs/2509.01092
为什么长上下文处理如此困难?
在当前的 AI 应用中,利用 LLM 处理包含大量外部知识的长文本输入,是提升问答、对话和智能体应用能力的关键。然而,这一过程也带来了严峻的挑战:在传统 LLM 中,注意力机制的计算和内存开销会随着输入长度的平方(N²)增长。
这意味着文本长度翻一倍,速度可能会慢 4 倍,这会导致显著的系统延迟,并消耗大量内存用于存储 KV Cache,进而降低系统吞吐量。这使得开发者不得不在知识丰富度与系统效率之间做出痛苦的权衡。
Meta 的研究指出,在 RAG 应用中,LLM 处理的上下文中包含了大量从外部知识库检索拼接而成的段落,但其中只有一小部分与用户查询紧密相关。这些不相关的段落导致了计算资源的浪费。REFRAG 的核心思想正是基于这一观察,通过识别并跳过对这些非相关上下文的无效计算,来优化解码过程。
REFRAG 是如何解决问题的?
REFRAG 框架通过一个精巧的四步流程,利用注意力稀疏结构,实现了显著的性能提升。它与传统 RAG 的关键差异在于,它避免了让 LLM 直接处理冗长的原始文本。
压缩:首先,一个轻量级的编码器会读取检索到的文档,将每 16 个 token 压缩成一个浓缩了语义精华的「块向量」。 缩短:接下来,主模型不再读取原始的 token,而是直接处理这些块向量。输入序列的长度因此立刻缩短了 16 倍。 加速:由于输入变得极短,注意力机制的计算开销大幅降低,同时作为显存消耗大头的 KV cache 也变得更小。这正是其能实现惊人速度提升的根本原因。 选择:为了防止在压缩过程中丢失关键信息,框架引入了一个基于 RL 的策略充当「质检员」,它能智能地挑出信息密度最高、与任务最相关的关键片段,确保它们不被压缩,从而保留核心信息。Meta 表示,该框架的有效性已在包括 RAG、多轮对话和长文档摘要在内的多种长上下文任务中得到验证,取得了突破性的成果:
速度提升: 将首个 token 生成时间(TTFT)加速高达 30.8 倍。在 16k tokens 的场景下,相比 CEPE 等基线方法,实现了超过 16 倍的 TTFT 加速。从性能图表可以看出,文本越长,REFRAG 的优势越明显,其加速效果随上下文规模增加呈指数级提升,而基线方法仅为线性增长。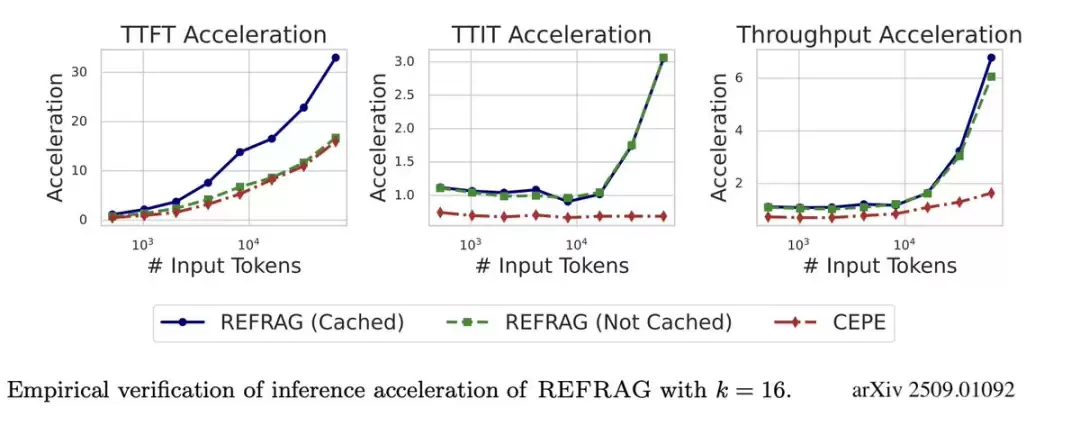
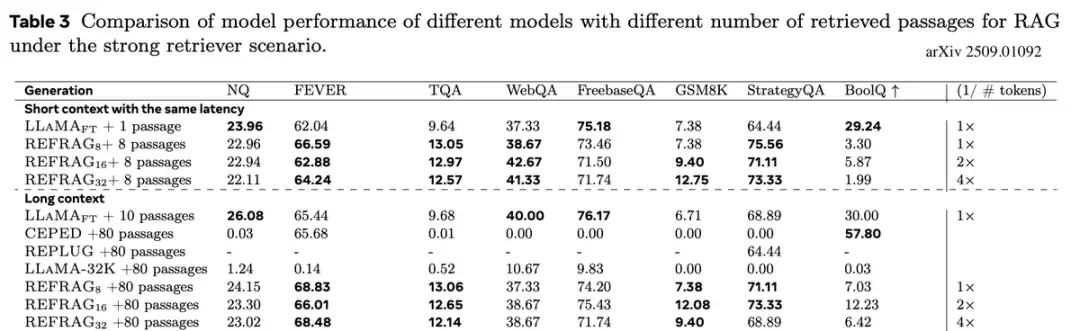
简而言之,REFRAG 让「大上下文 RAG」从理想变成了现实。
虽然其效果听起来非常不错,但评论区也表示,它最终的价值仍需要在更广泛的实际应用场景中进行检验。
还有人对该研究中的 RL 策略提出了质疑。
方法
为实现编码器与解码器的有效对齐,本研究遵循 Yen et al. (2024) 的工作,采用了一种基于「下一段落预测」任务的持续预训练方法。
在训练中,每个数据点包含总计 s+o=T 个词元(token)。通过这一预训练过程,模型能够学习如何利用块嵌入(chunk embeddings)来高效执行下游任务。
为了进一步提升模型性能,该方法还引入了通过 RL 实现的选择性压缩机制。在完成 CPT 对齐后,模型会经过监督微调 ,以适应具体的下游应用场景,例如 RAG 和多轮对话。
在 CPT 的核心任务中,模型的工作流程如下:编码器首先处理前 s 个词元
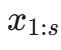
,其输出的压缩信息将辅助解码器预测接下来的 o 个词元
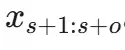
。
这项任务旨在训练模型利用上下文信息进行高效预测,为其在实际应用中的表现奠定基础。其最终目标是让任意的编码器和解码器组合都能协同工作,确保解码器基于压缩上下文生成的内容,与它在拥有完整、未压缩上下文时生成的内容高度相似。
持续预训练方案
为确保 CPT 阶段的成功,研究者提出了一个包含重建任务和课程学习方法的训练方案。消融研究表明,该方案对于实现优异的 CPT 性能至关重要。
重建任务。此任务的目标是让编码器学习如何以最小的信息损失压缩文本。具体操作是,将前 s 个词元
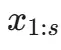
输入编码器,然后训练模型在解码器中重建出完全相同的词元
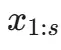
。在此过程中,解码器模型本身保持「冻结」(即参数不更新),训练重点完全集中在编码器和用于连接两者的投影层上。
该任务主要实现两个目标:
高效压缩:训练编码器将 k 个词元压缩成一个块嵌入,同时最大程度地保留原始信息。 空间映射:训练投影层有效地将编码器输出的块嵌入映射到解码器的词元空间中,使解码器能够「理解」并准确重建原始信息。设计重建任务的一个特定意图是,鼓励模型在训练时更多地依赖其上下文记忆(即从输入中获取信息),而非其固有的参数化记忆(即模型自身已经学到的知识)。一旦通过此任务初步对齐了编码器与解码器,便会解冻解码器,正式开始 CPT。
课程学习。尽管上述训练任务在概念上清晰,但在实践中却极具挑战性。其难度在于,随着块长度 k 的增加,可能的词元组合数量会以
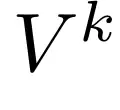
的速率呈指数级增长(其中 V 是词汇表的大小)。将如此巨大的多样性有效压缩到一个固定长度的嵌入中,是一项重大的技术挑战。此外,从 L 个块嵌入中重建出
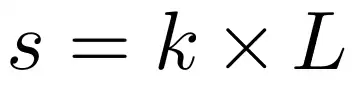
个词元,进一步加剧了任务的复杂性。
与直觉相反,直接继续预训练解码器以利用编码器输出,即使是在重建任务中,也未能降低困惑度。为解决这一优化挑战,研究者建议对这两项任务均采用课程学习。课程学习通过逐步增加任务难度,使模型能够渐进且有效地掌握复杂技能。对于重建任务,训练从重建单个块开始:编码器接收用于
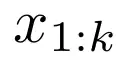
的一个块嵌入
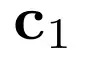
,解码器则使用投影后的块嵌入 ecnk1 来重建这 k 个词元。随后,模型从
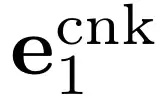
和
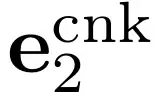
中重建
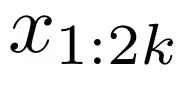
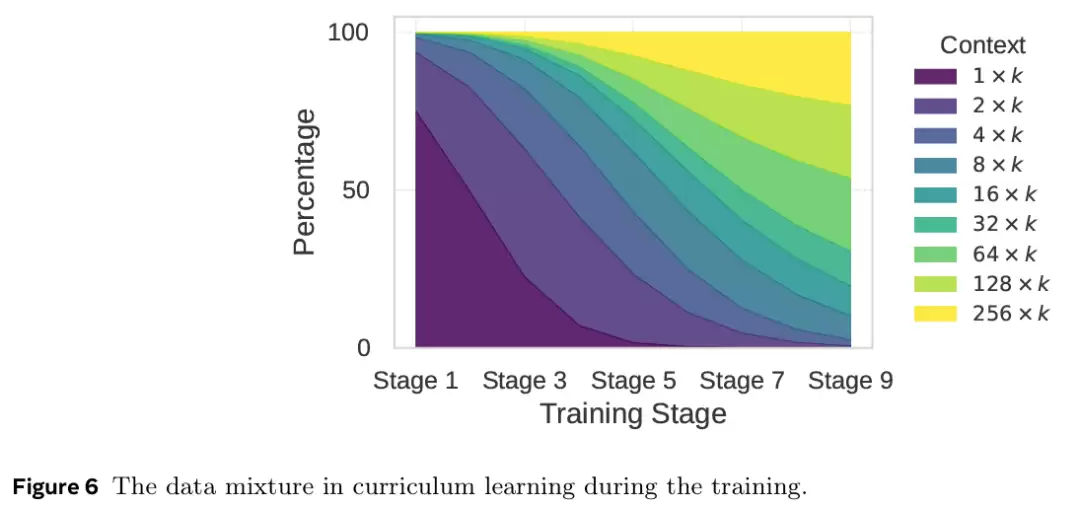
,以此类推。为了持续调整任务难度,研究者随时间改变数据混合比例,从以较简单任务(例如,单个块嵌入)为主的样本开始,逐步过渡到以更困难任务(即 L 个块嵌入)为主的样本。图 6 提供了课程学习期间数据混合的可视化展示。
选择性压缩。为了进一步提升答案预测的准确性,该方法(REFRAG)引入了选择性词元压缩机制。其核心思想是,对于上下文中特别重要的信息块,可以不进行压缩,而是以原始形式保留,从而避免关键信息丢失。
一个强化学习策略被用来决定哪些块应当被保留。该策略以下一段落预测的困惑度作为负向奖励信号进行指导(即困惑度越低,奖励越高),从而学习识别并保留关键信息。编码器和解码器都经过微调,以适应这种压缩块与未压缩块混合的输入形式。该策略网络利用块嵌入和掩码技术来优化块的扩展顺序,既保留了解码器的自回归特性,又实现了压缩位置的灵活安排。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

高刷显示器提升FPS游戏命中率,LG Display研究证实
LGDisplay研究显示,31名玩家在60Hz至480Hz刷新率下测试第一人称射击游戏。对比60Hz,480HzOLED显示器命中率提升约38%,其中60Hz升至240Hz提升最为显著,再升至480Hz再增约10%,输入延迟减少超过10毫秒。

年确认不插入闰秒,距上次调整已10年
国际地球自转和参考系服务宣布2026年末不插入闰秒,距上次调整已隔十年。闰秒用于协调原子时与地球自转时,已调整27次均为正闰秒。因气候变化导致地球自转减速,首个负闰秒推迟至2029年,国际计量界计划2035年前废止闰秒机制。

红米Note 17 Pro首销活动送电池升级保五年免费换新
REDMINote17Pro首发提供五年电池升级保障:前四年电池健康低于80%免费换新,第五年升级为更大容量电池。内置9000mAh电池,支持67W快充与22 5W反向充电,配备康宁大猩猩Victus2玻璃及四重防水认证,防护规格对标旗舰。

三星A18渲染图曝光 机身变厚或搭载6000mAh电池
据悉,三星A18最新渲染图曝光,其机身厚度增至7 84毫米,较上一代增加0 34毫米,推测或为配备6000毫安时大容量电池。此外,外观延续水滴屏设计,后置三摄模组有微调,并且底部配备USB-C接口,还支持快速充电功能。

三星S26像素级防窥屏幕隐私保护再升级
三星GalaxyS26系列搭载像素级隐私显示技术,从硬件层面控制OLED子像素发光方向,实现物理级防窥,正面观看画质无损,侧面超60°即模糊。该功能深度集成OneUI8 5,支持智能场景触发和多档位强度调节,与Knox安全平台形成防护体系,无需贴膜,不损画质。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
热门教程
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















