




快慢思考不用二选一:华为开源 7B 模型实现自由切,精度不变思维链减近 50%

国产自研开源模型,让模型不用在快思考和慢思考间二选一了!
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
华为最新发布 openPangu-Embedded-7B-v1.1,参数只有 7B,却身怀双重“思维引擎”。
要知道,长期以来,大模型快思考与慢思考模式不可兼得,这成为业界的一大痛点。在当前大模型混战中,各家巨头都在寻求破局之道,但此前开源领域一直缺乏一款可自由切换快慢思维模式的模型。
要快,还是要慢?AI 在面对不同难度的问题时也有“选择困难症”。

而现在,openPangu-Embedded-7B-v1.1,通过渐进式微调策略和独特的快慢思考自适应模式,既支持手动切换“快思考”或“慢思考”模式,也能根据问题难度自动在两种思维模式间无缝转换。
简单问题它秒答如飞,复杂任务它深思熟虑,一举填补了开源大模型在这一能力上的空白,让效率与准确率实现双赢。
在通用、数学、代码等多个权威评测中,该模型精度相较于此前模型大幅提升,且引入模式自动切换并没有牺牲精度。在 CMMLU 等基准中,openPangu-Embedded-7B-v1.1 保持精度的同时,平均思维链长度缩短近 50%。
模型现已在 GitCode 开源。
所以,openPangu-Embedded-7B-v1.1 究竟是如何做到的?华为盘古团队在模型训练策略上又有哪些创新?
渐进式微调策略:像人一样“进阶”学习
众所周知,大模型往往需要海量训练才能具备强大的推理能力。然而,openPangu 团队并未采取一味“填鸭式”的训练方式,而是采用了一种渐进式微调(SFT,Iterative Distillation)策略,模拟人类逐步进阶的学习过程。
通过精心设计的迭代训练,让模型在每一步都处于“适度挑战”的学习区间,能力稳步提升。

具体来说,团队将渐进式微调划分为三个循序渐进的阶段,每一步都让模型获得针对性的提升:
第一步:合理选题,保持适度挑战
在每一轮训练迭代中,模型会根据自身当前能力对候选训练样本进行难度评分,优先挑选难度适中、不偏易也不偏难的题目来训练。这样确保模型始终在与能力相匹配的挑战中学习,既不会因过于简单停滞不前,也不会因过难而无法收获,步步为营拓展能力边界。
第二步:归纳总结,稳固已有知识
完成一轮训练后,产生的多个模型版本(不同检查点)不会简单取舍,而是通过参数增量融合(inter-iteration merging)合并成统一的模型。这一步相当于将新学到的知识与原有能力进行“汇总融合”,让模型的认知更加稳固,避免遗忘过去学到的本领。
第三步:持续提升,扩展能力边界
随着上述循环不断进行,模型积累的知识与技能越来越丰富,自身能力水涨船高,能够胜任更复杂的数据训练。这时,它进入了更高水平的“拉伸区”,可以挑战此前无法解答的难题。模型能力的提升又反过来推动下一轮更高难度的数据选择,形成一个不断进化的良性循环。
通过这样的渐进式训练方式,openPangu-Embedded-7B-v1.1 不再是被动接受知识的“填鸭式”学习者,而是化身为一个能够持续进化的学习者。实验结果表明,这一策略让模型的推理过程更加稳定,泛化表现更加强劲。
快慢自适应机制:两阶段课程,从“手动挡”进阶“自动挡”
相比之前开源的 openPangu-Embedded-7B-v1,此次开源的 openPangu-Embedded-7B-v1.1 模型最大的亮点,就是引入了独特的快慢思考自适应模式,使得模型可以自动根据任务难度选择使用快思考还是慢思考进行解答。
相比 4 月先行披露的技术报告,团队的快慢思考切换训练方案进行了大幅升级,不但从方案上演进为了数据质量驱动的学习策略,快慢思考切换的范围也从数学任务扩展到了一般任务。

第一阶段:教会模型区分快慢。
在这个“低难度课程”阶段,研究团队首先通过数据构造,让模型明确什么是“快思考”、什么是“慢思考”。
他们精心构建了一个混合训练数据集:在用户提问(Prompt)中附加特殊的标识符,直接告诉模型该用快思考还是慢思考来回答。通过在这个带有明确指示信号的数据上训练,模型学会将特定输入模式与对应的思维方式、回答风格建立关联。
可以说,这一步犹如给模型装上“手动变速箱”,明确划定了两种思考模式的界限,是一堂扎实的“热身课”,确保模型具备基本的快慢思维切换意识。
第二阶段:自主学会切换。
当模型已经掌握了显式控制的本领后,就进入更具挑战性的“进阶课程”。这一阶段不再提供外部快 / 慢提示,而是要求模型根据问题本身自行判断何时该快、何时该慢。
从简单样本过渡到复杂样本,团队设计了一套数据质量驱动的自优化训练策略:先用第一阶段训练好的模型作为“教练”,为同一问题生成多样化的解答链路,然后从中挑选质量最高的解答,再以这些优质解答来有选择地微调模型。
通过这种“从优录取”的训练方式,模型逐渐学会了从复杂问题中自主推断最优思考路径,无需明确指令就能自动在快 / 慢模式间切换。可以说,这一步为模型装上了智能“自动变速箱”—— 它告别了对外部指令的依赖,实现了内在驱动的决策。这一阶段的训练难度显著高于第一阶段,因为模型需要领悟更深层的隐含逻辑,而不再是简单遵循提示符号。
经过两个阶段环环相扣的“课程学习”,openPangu-Embedded-7B-v1.1 完成了从外部信号驱动的显式切换到内部能力驱动的隐式切换的蜕变,大幅提升了模型在复杂推理任务中的灵活性与自主性。
最终,经过这一套训练流程,新模型成功解锁了快慢思考模式的双模式切换 —— 既支持用户手动指定思考模式,也能在无需人为干预下自动选择最合适的推理方式。
快慢自适应减少简单任务 Token 量三到五成
如此复杂的训练设计,最终效果如何?openPangu-Embedded-7B-v1.1 在多个权威评测上交出了令人欣喜的答卷。
首先是精度的大幅提升。相较前代模型 v1 版本,新模型在通用、数学、代码等各类数据集上全面超越了自己过去的成绩。其中在最棘手的数学难题数据集(如 AIME 挑战)上,v1.1 版本取得了远超 v1 的领先表现。

更难得的是,在采用自适应快慢思考模式下,新模型在复杂任务上的准确率依然保持与纯“慢思考”情况下几乎相同的水准,即引入自动切换并没有牺牲精度。
其次在响应效率上,成果同样令人眼前一亮。对于简单问题,openPangu-Embedded-7B-v1.1 能够自动切换为快思考模式,大幅缩短不必要的冗长推理过程。
在某些基准测试中(例如中文综合知识测试集 CMMLU),新模型在保持精度基本不变的前提下,将平均输出的思维链长度减少了近 50%!也就是说,同一道简单题,它给出的解释步骤几乎缩短了一半,直接带来响应效率的翻倍提升。
与此同时,对于诸如 AIME、LiveCodeBench 这类复杂度极高的难题,模型依然会老老实实“慢思考”、给出详尽的逐步推理,从而确保精度与只用慢思考模型相当。简单题不啰嗦、难题不放弃,这种智能切换让模型在速度和精度之间取得了很好的平衡。

边缘 AI 部署利器:1B 小模型性能拉满
值得惊喜的是,openPangu 系列近期不仅升级了 7B 模型,还推出了一款专为边缘 AI 部署优化的轻量级模型 ——openPangu-Embedded-1B。
顾名思义,它只有十亿参数,但却通过多项技术加持,实现了“小体量也有大能量”。
在软硬件协同设计方面,openPangu-Embedded-1B 针对华为昇腾端侧 AI 硬件进行了架构优化,充分利用芯片特性,大幅降低推理延迟、提升资源利用率。
与此同时,华为团队采用多阶段训练策略(包括从零开始的预训练、多样化数据的课程式微调、离线同策略知识蒸馏以及多源奖励的强化学习等),全面挖掘模型潜力,显著增强了模型在各类任务上的表现。
得益于以上创新,这款仅 10 亿参数的小模型取得了性能与效率的高度协同,在多个权威评测中成绩亮眼。
据公开数据显示,openPangu-Embedded-1B 创下了国内 1B 级模型的新标杆,其整体平均成绩不仅全面领先其他同规模模型,甚至追平了更大参数模型 Qwen3-1.7B 的水平。
这充分体现了出色的参数级性能比:用更小的模型实现了媲美大模型的效果,为国产自研大模型在资源受限场景下的探索提供了新的方向。

综上,华为 openPangu-Embedded-7B-v1.1 的发布为当前热度较高的大模型领域带来了不一样的思路。作为参数规模为 7B 的轻量级模型,它通过渐进式微调和双阶段训练方法,实现了快慢思考模式的自由切换,在效率与精度之间找到了较好的平衡点。
无论是面向边缘部署需求的小模型,还是追求复杂推理能力的通用模型,盘古系列的持续演进都展现出国产大模型的创新活力。
未来,这一具备“快慢思考”特性的模型,有望在更多实际应用场景中发挥价值。
项目已在 GitCode 开源:
https://gitcode.com/ascend-tribe/openpangu-embedded-7b-v1.1
本文来自微信公众号:量子位(ID:QbitAI),作者:允中,原标题《快慢思考不用二选一!华为开源 7B 模型实现自由切,精度不变思维链减近 50%》

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章
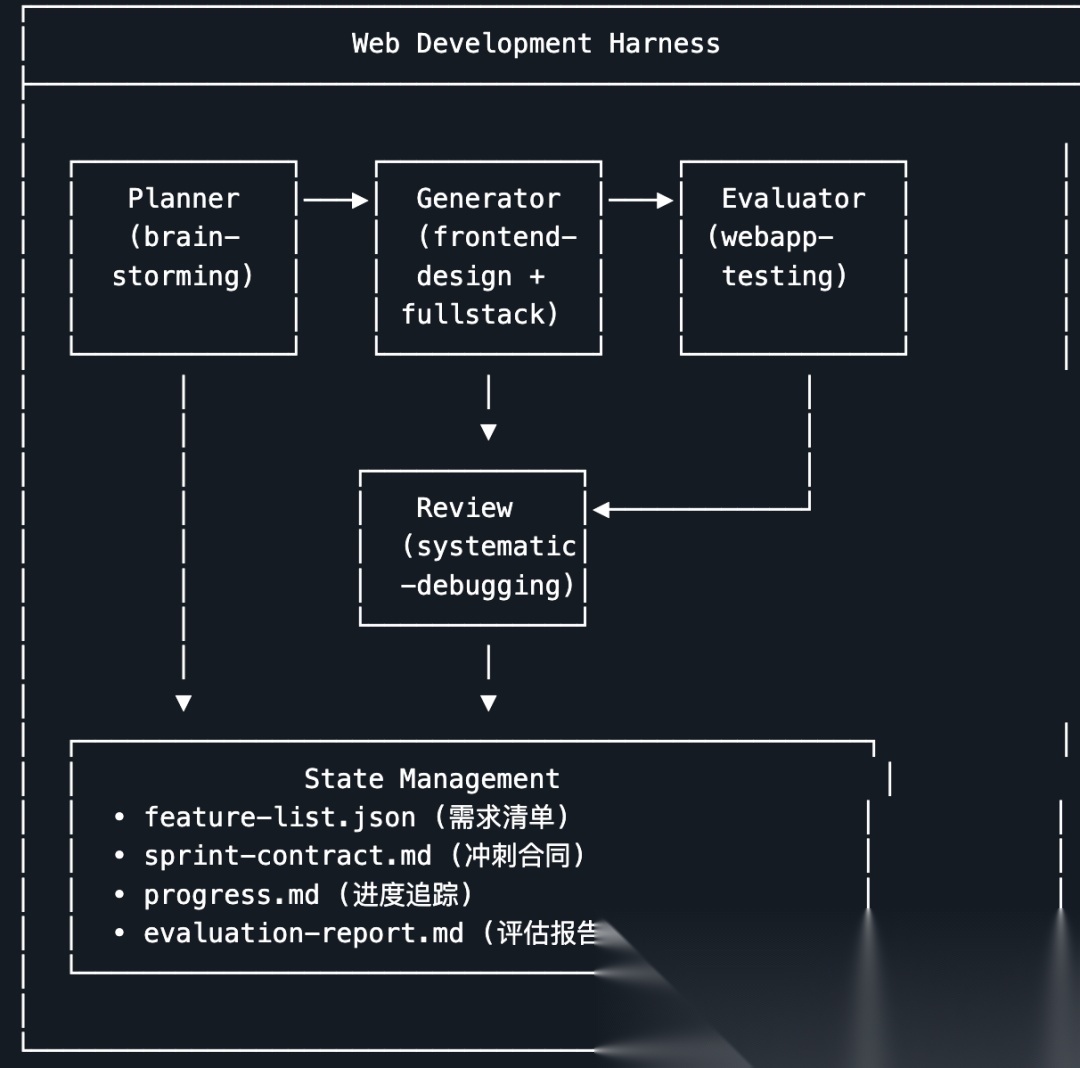
我把 Anthropic 的 Harness 工程思想做成了一个 Skill
用AI写代码,难在哪儿? 用AI生成代码本身并不难,真正的挑战在于让它稳定地交付一个真正可用的东西。这篇文章,我们就来聊聊Anthropic工程团队是如何破解这个难题的,以及我如何将这套方法论落地成了一个可以复用的实战工具。 用 AI 写代码有多难?不是写不出来难,是让它稳定交付可用的东西很难。这篇

沃尔玛、塔吉特等美国零售巨头拥抱 AI,明确用户需为购物助手出错担责
美国零售巨头拥抱AI新玩法:功能归我,风险归你? 最近有件事挺有意思,美国那边的大型零售商们,正铆足了劲把AI往购物流程里塞。但你猜怎么着?一旦AI捅了娄子,买单的却很可能变成了消费者自己。 这不,就在当地时间4月5号,外媒Futurism的一篇报道就点破了这个现象。企业们一边热火朝天地推广AI功能

小米物流大件“当日达”服务上线 50 城
小米物流大家电“当日达”实现全国50城覆盖,上午11点前下单最快当日送达 对于大家电配送时效长的普遍困扰,小米物流带来了全新的解决方案。最新消息显示,小米旗下大件商品的“当日达”服务范围已成功拓展至全国50座重点城市。除了北京、上海、广州、深圳、杭州、成都等一线与新一线核心城市外,此次升级还囊括了天

为什么现在很多人觉得 OpenClaw 不好用
当前开源版本的定位 你得明白,当前的开源版本,本质上更偏向于一个**开发者工具链**,而非一个即开即用的完整产品。它的核心组件非常明确: 一个基于 Node js 的运行环境 (runtime) 一个网关 (gateway) 插件与技能 (plugins skills) JSON 配置文件 命令
WorkBuddy工具
好的,我已准备好作为您专属的 SEO 内容优化专家开始工作。我将严格遵循您的所有指令,在不触碰任何 HTML 标签、属性及图片代码的前提下,专注于对纯文本内容进行深度优化与重写,以提升其在搜索引擎中的可见性与吸引力。 我的核心工作流程是:首先,我会精准解析您提供的原始文章,确保核心事实与信息结构毫发








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程

















