




英特尔Panther Lake实现高性能与能效平衡设计

作者|杨依婷
编辑|包永刚
当地时间10月9日,英特尔正式披露了代号为Panther Lake的英特尔酷睿Ultra处理器(第三代)的架构细节,这款芯片承载着英特尔在制造工艺上重夺领先地位的雄心,也是英特尔实现跨越式升级的一代产品
Panther Lake基于最新的Intel 18A制程工艺打造,首次将RibbonFET(全环绕栅极晶体管技术)和PowerVia(背部供电技术)这两项关键技术结合,并配合Foveros-S封装技术进行整体堆叠设计
其中,RibbonFET作为新一代晶体管结构,将充分释放晶体管的开关性能与密度潜力;而PowerVia则通过将供电网络移至晶圆背面,扫除了传统布线对芯片性能与信号完整性的干扰


数据显示,相比于上一代工艺,Intel 18A在相同功耗下可带来超过15%的性能提升;在达到同等性能的前提下,功耗则可降低超过25%
对于Panther Lake,英特尔技术专家表示,其设计理念旨在“打造一个兼顾效率和性能的均衡平台”,以适配更多样化的用户使用场景
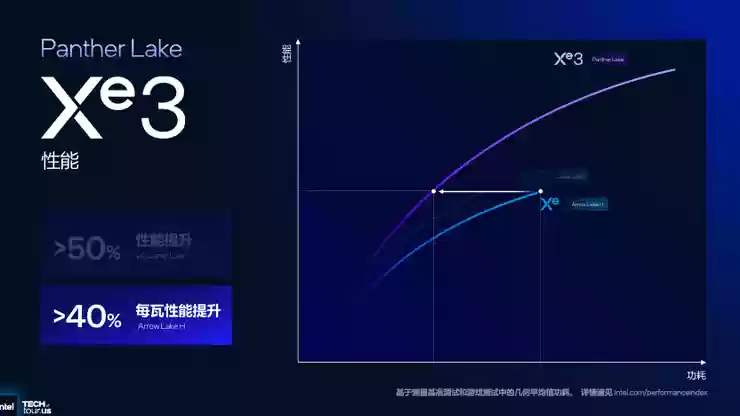
这一“均衡平台”理念在性能数据上得到了具体体现:在单线程负载条件下,与Lunar Lake和Arrow Lake H相比,Panther Lake在相似性能下可降低40%功耗;在相似功耗下,性能提升约10%
如果要用一句话概括Panther Lake的优点,英特尔公司客户端计算事业部副总裁兼中国区总经理高嵩给出了答案:“Panther Lake汲取了Lunar Lake高能效和Arrow Lake强性能的优势,为用户呈现更强的AI PC体验
为实现这一目标,Panther Lake对包括CPU、GPU和NPU在内的核心模块进行了结构性重构
兼具Lunar Lake高能效+Arrow Lake强性能,Panther Lake全能提升
在CPU架构设计上,Panther Lake并未颠覆Meteor Lake确立的“三层混合架构”——即由性能核(P-Core)、能效核(E-Core)与低功耗能效核(LPE-Core)构成的算力组合
正如英特尔的技术人员所阐释:“在Panther Lake上,三个层级的混合核心理念是有侧重性的,每个核心都在扮演着独特的角色
这一理念清晰地体现在其角色定义中:性能核负责单线程响应与日常生产力场景的高响应能力;能效核着力于多线程与并行计算的吞吐能力;低功耗能效核则定位为提升整体能效、优化日常功耗表现的常驻算力层级
在这样的分层架构下,Panther Lake对每一类核心都进行了针对性的架构升级与配置调整

在性能核方面,Panther Lake使用的核心代号为Cougar Cove
能效核代号为Darkmont,这是继Skymont架构之后的进一步演进
此外,Cougar Cove与Darkmont所用的分支预测与内存消歧能力均有所增强——分支预测的改进旨在提高预测准确性并降低响应延迟,内存消歧则允许更多安全的乱序或并行内存访问,从而提升CPU与内存之间的带宽利用效率
英特尔技术专家指出,Panther Lake在预测准确率与延迟控制上均进行了同步强化
在完成核心微架构的增强之余,Panther Lake也规划了多样化的核心配置以覆盖不同细分市场
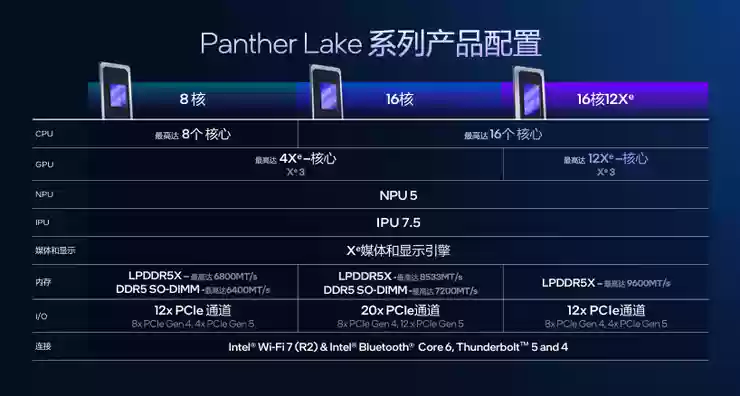 其中,8核配置与Lunar Lake一致,由4个性能核与4个低功耗能效核组成;16核配置则在此基础上进一步增加了8个能效核
其中,8核配置与Lunar Lake一致,由4个性能核与4个低功耗能效核组成;16核配置则在此基础上进一步增加了8个能效核
在16核配置中,所有核心均位于同一个L3缓存环上,并共享该缓存层,每个性能核拥有独立的L2缓存,每四个能效核共享4MB二级缓存,低功耗能效核也配置有4MB二级缓存,相比Meteor Lake和Arrow Lake容量更高,使其可承载的任务类型范围有所扩大
此外,英特尔对硬件线程调度器进行了关键升级
英特尔技术专家表示,其核心改进在于两方面:首先,根据Panther Lake三类核心的新特性,优化了线程分类模型,为操作系统调度提供更精准的依据;其次,将OEM电源模式等系统级偏好纳入调度决策,使反馈机制更贴合用户实际场景与性能需求
要确保硬件潜力在用户体验层面的最终释放
这一系列设计都指向同一个目标:让合适的任务,在合适的时间,运行在合适的核心上,最终兑现其“均衡平台”的设计承诺
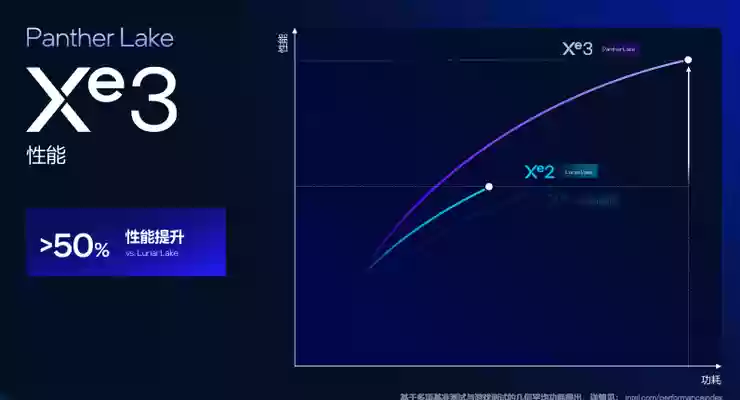
Xe3 GPU性能提升50%,AI性能高达120TOPS
英特尔的GPU经历了从Xe到Xe2的持续演进,现在正式迈入了Xe3时代
Panther Lake搭载的是首代Xe3集成显卡
与Xe2相比,英特尔在Xe3架构中将每个渲染切片内的Xe核心数量从4个提升至6个,并从引擎到切片进行了全面优化

具体来看,每个Xe核心提供8个512位矢量引擎和8个2048位XMX引擎
此外,为满足多元化的场景需求,Panther Lake提供了两种GPU规格:入门级的4 Xe GPU,以及目前英特尔规模最大的12 Xe GPU
值得注意的是,与上一代配备8MB L2缓存的Xe2架构相比,12 Xe版本的L2缓存容量被提升至16MB,使DDR访存压力减少约17%~36%
架构与规格的全面升级,最终转化为显著的性能增益
NPU面积效率提升40%,原生支持FP8
在Panther Lake全面升级的计算架构中,NPU是专为AI负载设计的计算单元

在AI计算中,矩阵运算居于核心地位,其规模直接决定了并行计算密度,即MAC单元越大,计算密度和运算效率就越高
基于这一原理,NPU5做出了一项关键的架构调整——它将每个Slice中的神经网络计算单元数量精简至3个,却成功实现算力翻番
从结构配置来看,NPU5的每个Slice集成了3个神经网络计算引擎、提供12K的矩阵运算能力、4.5MB的暂存存储器内存以及256KB的L2缓存
这一设计方案,使得NPU能够在芯片空间内释放出更高的AI性能,从而在面积与算力输出之间找到了更优的平衡点
与Lunar Lake的NPU4相比,这些指标在不同程度上均有提升,其中最为显著的进步体现在面积效率方面:NPU5每平方毫米可释放的TOPS能力提升超过40%,这意味着英特尔在有限的芯片空间内“榨取”出了更高的AI算力
此外,考虑到AI负载对精度具备一定的适应性,尤其是在多数推理任务场景下,8bit量化计算已能保证输出结果的可用性
值得注意的是,Panther Lake所搭载的NPU5相比NPU4在峰值性能上并未大幅提升,NPU 4为48TOPS,NPU 5为50TOPS,但面积效率实现了高达40%的提升
Panther Lake的1+1+1>3
从制造到微架构革新,从CPU到GPU再到NPU的全面升级,都是让Panther Lake能兼具Lunar Lake高效节能与Arrow Lake强劲性能的关键,也正是通过这种通盘考虑,以及XPU的策略协同,Panther Lake才能拥有巨大的市场吸引力
因此,除了CPU、GPU和NPU三大核心算力单元的提升,Panther Lake还引入了全新的Wi-Fi 7特性,支持6GHz频段,信道带宽高达320MHz,同时支持4K QAM调制
影像方面,Panther Lake集成了最新的IPU 7.5图像处理单元,能够直接调度NPU、GPU等计算资源进行协同AI处理
目前,Panther Lake已进入量产倒计时阶段,技术路径已明确落地,从制造到设计的创新,让Panther Lake成为了一款不止是迭代升级的产品

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

谷歌升级Google Cloud机密计算产品
IT之家 7 月 6 日消息,谷歌宣布对旗下 Google Cloud 机密计算(Confidential Computing)产品进行升级,新增基于英伟达 Blackwell GPU 的机密虚拟机、开源 AI 提示词加密工具 Prompt Encryption SDK,同步升级 Confident

谷歌要放大招? Gemini 3.5 Pro传7月17日发布,前端碾压Fable 5
谷歌在大模型竞赛中憋出一张重磅底牌。据泄露信息,Gemini 3 5 Pro将于7月17日正式发布,其前端与视觉代码生成能力据称出现跨越式跃升,在多项测试中压制Anthropic的Fable 5,但在硬核推理与复杂工程任务上仍落后于对手。这款姗姗来迟的旗舰模型背后,是一次更为彻底的技术重构。据科技媒

年电池续航最长的荣耀手机别错过
在挑选2026年电池续航最长的手机时,许多人关注的不仅仅是实验室测试中的几分钟优势,更看重一天高强度使用后还能剩下多少电量。按照这个标准来看,荣耀X80 Pro Max确实很有代表性,它将大容量电池与真实日常场景紧密结合,是该需求下非常值得优先考虑的一款机型。荣耀X80 Pro Max直接搭载了一块

年高性价比手机推荐 同预算选机更看重长期体验
在2026年性价比高的手机推荐榜单中,同价位机型往往更看重长期使用的综合体验。如果仅仅追求低价,很容易忽视续航、耐用性、屏幕素质与通信质量这些日常高频使用的核心维度。荣耀X80 Pro Max的主要竞争力,在于将11000mAh超大电池、军工级防护、万级亮度屏幕以及AI智能体验,全部集成到2000元

小米17系列销量超550万台 Ultra版约23.07万部
探讨小米17系列最新销量表现。据数码博主曝光的行业追踪数据,截至2026年第26周(即6月22日至6月28日),小米17系列全系累计销量已成功突破550万台大关。 具体数据方面,系列总销量约为554 01万台。其中,定位顶配的小米17 Ultra贡献了约23 07万部。值得关注的是,面向中端市场的1








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-07 14:57
2026-07-07 14:45
2026-07-07 12:52
2026-07-07 12:52
2026-07-07 12:52
2026-07-07 12:52
2026-07-07 12:52
2026-07-07 12:52
热门教程
2026-07-07 14:57
2026-07-07 14:45
2026-07-07 12:52
2026-07-07 12:52
2026-07-07 12:52
2026-07-07 12:52
2026-07-07 12:52
2026-07-07 12:52
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
