




蚂蚁开源Ring-1T:推理编程通用智能三冠王,突破性进展解析

人工智能真的能像人类一样"动脑子"思考吗?蚂蚁开源团队最新推出的Ring-1T模型,为这道困扰学界多年的难题给出了令人信服的答案。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
与以往依赖海量数据"记忆"标准答案的语言训练路径不同,Ring-1T开创性地让AI在复杂推理任务中真正"思考"出解决方案。
通过将强化学习与多阶段推理机制深度融合,该模型能够在持续反馈中不断修正思路、优化逻辑路径,逐步形成更稳定、更接近人类思维模式的推理能力。
正是这种从"模仿"到"思考"的质变,使Ring-1T成为开源AI领域具有里程碑意义的突破。接下来,让我们深入探索这一创新研究的技术实现路径。

论文地址:https://arxiv.org/pdf/2510.18855
通用智能的曙光初现
在系统性评估中,Ring-1T模型在多个高难度推理与数理基础测试中均展现出突破性的表现。作为开源领域首款万亿参数规模的思考型模型,它在推理、数学、编程及通用智能任务上实现了全方位的卓越能力。
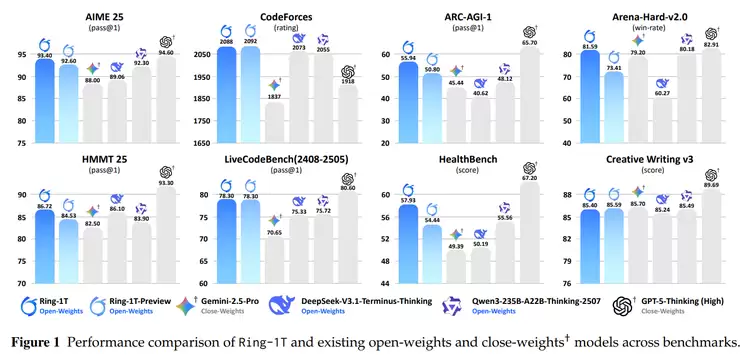
在数学推理方面,Ring-1T在AIME-2025中获得93.4分的优异成绩,接近人类顶尖选手水平;在HMMT-2025中得分86.72,彰显其跨领域数学推理与高复杂度逻辑演算的强大实力;在IMO-2025模拟评测中达到银牌水准,证明模型在需要多步推理与创造性证明的难题中能持续保持高准确率和稳定性。
在编程与算法能力上,模型在Codeforces平台测试中获得2088分,进入人类程序员的优秀水平区间。这表明Ring-1T不仅能理解算法逻辑,还能在有限时间内生成高效、可执行的代码,具备优秀的算法复杂度控制与问题分解能力。
在通用智能推理任务中,Ring-1T在ARC-AGI-v1中取得55.94分,显著超越此前开源模型的平均水平。该结果表明,模型在抽象模式识别、思维迁移与多步认知推理方面已展现出接近通用人工智能的发展潜力。
实验结果显示,模型的高性能表现主要得益于论文中提出的三项关键技术:
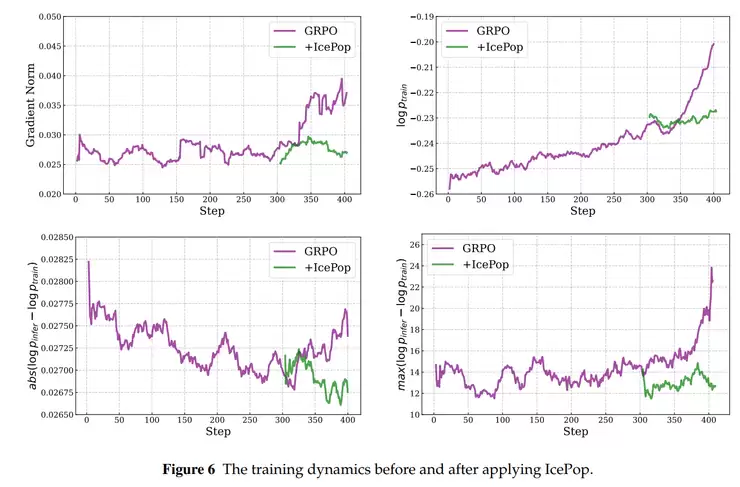
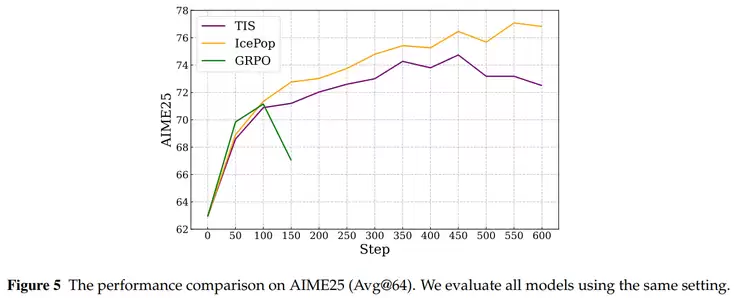
IcePop通过动态约束与梯度裁剪技术,有效控制高熵样本对训练过程的影响。系统会自适应调整温度参数,让高不确定性的输出以更可控的方式参与优化过程,从而在保持探索性的同时提升训练稳定性。
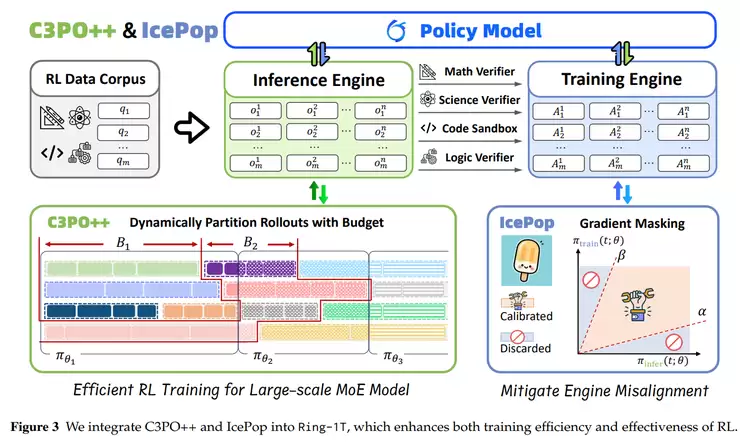
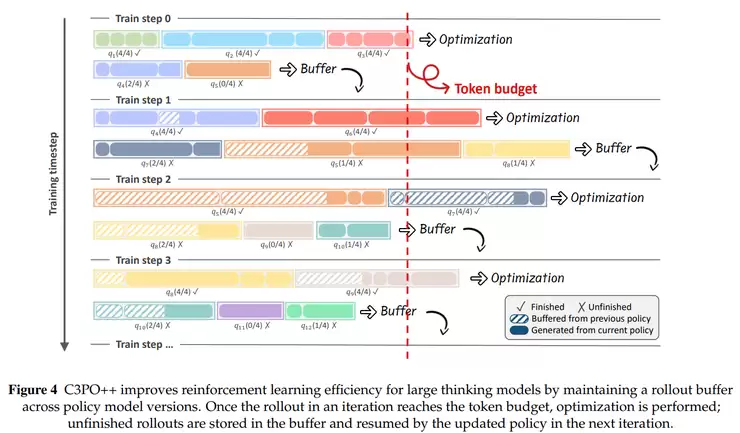
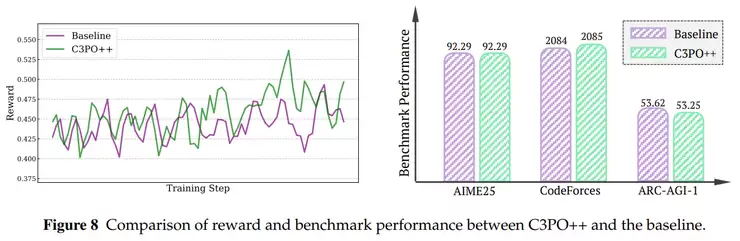
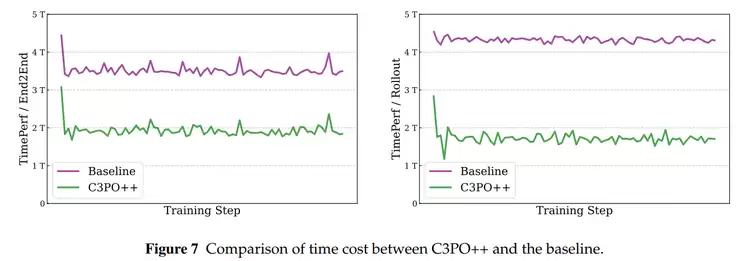
C3PO++专注于提升长序列推理和大规模模型生成效率。该方法采用动态分区和token预算机制,将推理过程划分多个小批次并行处理,并通过持久化缓存机制在多个GPU之间高效传递未完成的任务,显著提升计算资源利用效率。
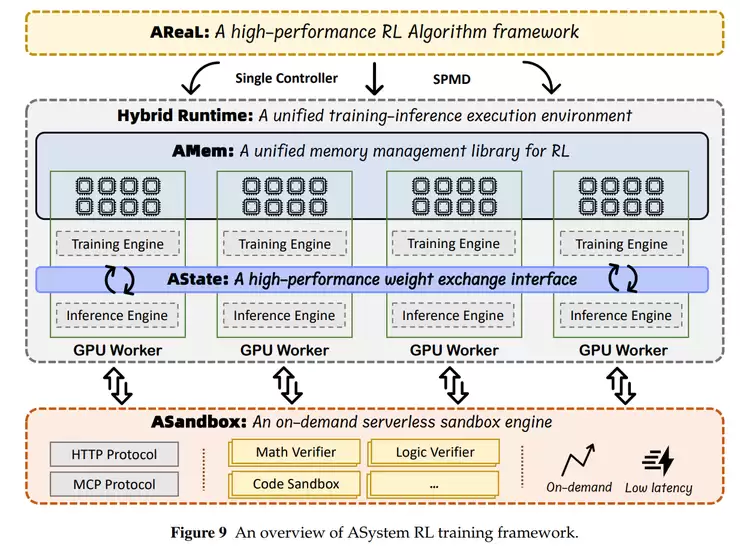
而ASystem则是支撑万亿参数强化学习的分布式架构。它整合统一的训练与推理运行时、高效的显存管理、快速的参数同步以及安全的隔离执行环境,使大规模模型训练具备更好的并行性、稳定性与容错性。
算法与系统的协同进化
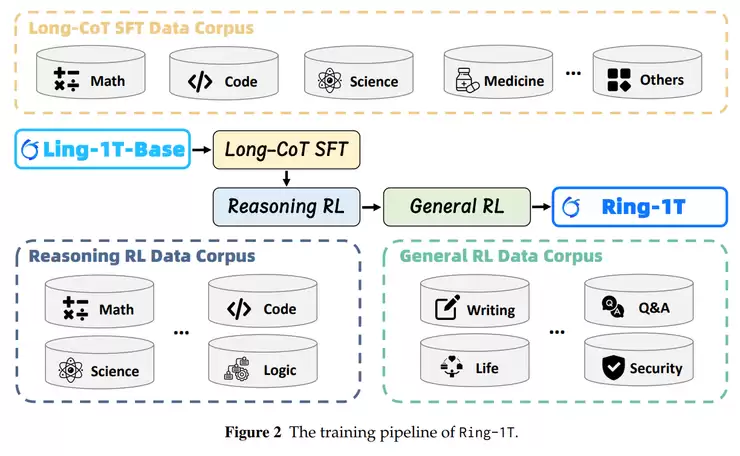
在技术实现层面,研究团队为Ring-1T思考型模型设计了分阶段的训练体系,通过监督微调、推理强化学习和通用强化学习三个阶段的递进训练,使模型的推理能力获得显著提升。
在强化学习阶段,IcePop技术通过动态样本筛选机制,有效过滤训练过程中可能引发模型震荡的异常数据,确保参数更新方向的稳定性。
具体而言,系统会在每次参数更新前,自动识别并降低那些在训练与推理阶段表现差异过大的token权重,防止模型因个别极端样本而产生训练方向偏差。
而C3PO++则负责优化模型生成过程中的并行效率。传统方法在处理超长序列时往往拖慢整体训练进度,而C3PO++通过"分段训练"和"并行续传"的方案,让长序列推理不再成为训练瓶颈。该方法为每个样本设置保留期,超时未完成的样本会被清理。那些尚未生成完成的样本则会在下一轮继续生成,这样推理和训练就可以同时推进。
为了确保系统资源的高效利用,C3PO++还采用token预算机制,当生成的token数达到预设上限时,就会触发参数更新。整个系统分为推理池和训练池两个部分:推理池持续生成新样本,训练池则收集已完成样本进行模型更新。
总体而言,IcePop让训练更平稳,C3PO++让训练更快速,两者结合使Ring-1T能在万亿参数规模下保持出色的强化学习表现。
为实现大规模模型的高效训练,研究团队专门设计了分布式强化学习系统ASystem。该架构采用统一控制与并行执行的运行模式,让训练、推理和参数更新能够协同推进。
该系统由四大核心模块构成:混合运行时负责统一管理训练与推理任务,高效显存管理模块支持多GPU间的数据共享与传输,快速参数同步模块确保万亿级参数在10秒内完成同步,安全沙箱环境则为代码生成与数学计算等任务提供隔离的执行空间。
在系统设计上,ASystem实现了控制逻辑与数据流的分离,使训练、推理和奖励计算都能独立运作。系统还具备"快速失败与自动恢复"机制:当某个节点出现异常时,系统能自动检测并恢复运行,不影响整体训练进度。
开源智能的下一站
过去的大模型主要依赖训练数据中的标准答案,但在遇到需要复杂逻辑推理的问题时往往表现不佳。Ring-1T通过强化学习让模型在反馈中自主形成更稳定、更清晰的推理模式。
这项研究的另一重要意义在于证明了超大规模强化学习的可行性。以往这种训练往往面临稳定性差、成本高的挑战,而这项研究通过创新的系统设计,为后续更复杂、更自主的模型研究提供了宝贵经验。
从长远发展来看,这项工作让开源模型在高层智能能力上具备了与闭源系统竞争的实力。它或许不仅是一次技术升级,更是让人工智能研究变得更开放、更具延续性的关键一步。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

索尼英纵Buds“游戏豆”冰透紫耳机发售,首发价1079元
索尼INZONE Buds“冰透紫”配色明日开售:首发价1079元 索尼INZONE英纵Buds“游戏豆”耳机的新成员——“冰透紫”配色,终于要来了。这款新品定于4月25日0点正式开启首销,官方定价为1199元,首发期间可享1079元的优惠价。 这款“冰透紫”配色在设计上颇有巧思,其机械结构呈现出一

消息称北京地区大疆门店将全面下架无人机产品,DJI Care 邮寄新机需市外收货地址
消息称北京地区大疆门店将全面下架无人机产品 一则来自“财闻”的报道,在无人机圈子里激起了不小的波澜。报道指出,受北京市近期出台的无人机管理新规影响,北京地区的大疆授权门店,近期将全面下架所有无人机产品。从多位门店店员处获得的消息更为具体:这项下架行动,预计会在5月1日前全部完成。 这意味着什么?简单

中科天塔发布新一代星载激光通信终端
中科天塔发布新一代星载激光通信终端,“太空智驾”愿景浮出水面 4月24日,在成都“2026中国航天日”主会场的一场商业航天产业高质量发展论坛上,西安中科天塔科技股份有限公司(简称“中科天塔”)带来了一项引人注目的发布。该公司首次公开亮相了其新一代星载激光通信终端,并进行了现场展示。 根据公司介绍,这

从技术追赶到局部领先 化合物半导体产业化进入生态重构深水区
从技术追赶到局部领先 4月24日,一份备受行业瞩目的报告——《第三代半导体产业发展报告(2025)》在2026九峰山论坛开幕式上正式亮相。这份由第三代半导体产业技术创新战略联盟编写的报告,为我们勾勒出了一幅产业蓬勃发展的生动图景。 正如第三代半导体技术产业创新战略联盟理事长吴玲所言,当前AI浪潮正以

东风二号甲导弹变成了秒针!一块“上海定制”腕表镌刻“独家记忆”
东风二号甲导弹变成了秒针!一块“上海定制”腕表镌刻“独家记忆” 第十一个“中国航天日”当天,上海交通大学钱学森图书馆里,景象颇有意味:巨大的“东风二号甲”导弹展品旁,一块小小的、略显陈旧的上海牌手表,正静静躺在展柜中,却吸引了众多观众驻足凝视。 钱学森曾佩戴的上海牌手表,现由上海交通大学钱学森图书馆








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
