




DeepSeek新功能上线:AI再进化,“王炸”能力全解析

AI领域最近又有了新突破——DeepSeek团队悄然开源了一个参数规模达300亿的小型模型,命名为DeepSeek-OCR。
别看它体量不大,设计理念却相当炸裂:他们竟打算让人工智能通过"看图"的方式去理解文本内容。
没错,这是真正的"以图识字"。
不仅如此,这不仅仅是简单的文字识别,而是将"视觉模态"作为一种文本压缩媒介,用图像来代表文字,以"视觉token"替代"文本token",实现所谓的光学压缩(Optical Compression)。
说实话,当我初次看到这篇论文时,第一反应是:难道他们想让语言模型也去上美术课?
不过静心思考后,这个思路确实有其合理之处。
大语言模型(LLM)最突出的痛点是什么?处理长文本时算力消耗巨大。
众所周知,大型模型的注意力机制复杂度呈平方级增长。输入长度翻倍,其计算量就要增加四倍;若要让它记住整篇长文档,模型立刻就会"高负荷运转"。
那么,能否换个思路解决问题?DeepSeek团队提出:既然一张图片能承载大量文字信息,不如直接将文本转化为图像,再让模型去"读图"!
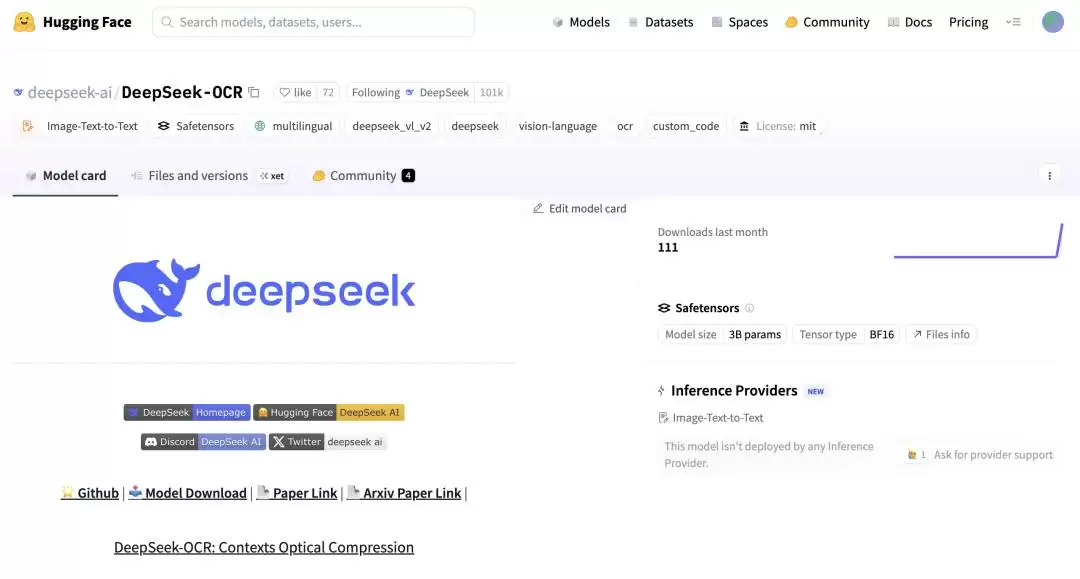
论文中展示了一个特别直观的案例:原本需要1000个token才能表达的内容,现在仅用100个视觉token就能搞定,压缩率达到10倍,同时还能保持97%的OCR准确率。
即便进行20倍极限压缩,仍能维持约60%的准确度。这意味着,模型"读图"的效率竟然比"读文字"还高。
换句话说,模型在几乎不丢失关键信息的前提下,计算负担减轻了十倍。
不少网友看到这里都感到惊讶:AI处理图像的资源消耗竟然比处理长文本还少?这完全颠覆了人类的直觉认知!
也有网友感叹道:DeepSeek这是要让模型"读文档"像刷朋友圈一样轻松。
在我看来,这套操作堪称"降维打击"。
过去我们一直在想办法让模型更懂文字、看得更远;而DeepSeek却反其道而行:让模型把文字变成画,再通过"看画识文"来理解内容。这有点像回到了人类最原始的沟通方式:象形文字。
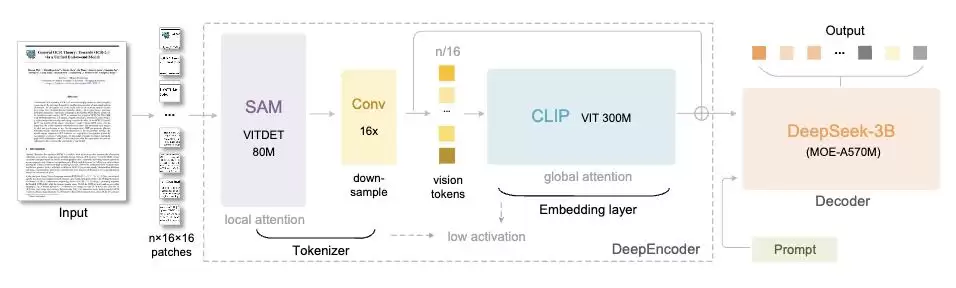
说到这里,让我们深入了解这个模型的具体构成。DeepSeek-OCR由两部分组成:DeepEncoder(图像压缩模块)+DeepSeek3B-MoE(解码还原模块)。
前者是整个系统的"压缩引擎",它巧妙地将两大视觉强者SAM-base和CLIP-large串联起来:
SAM负责捕捉细节的"局部注意力",CLIP则把握整体的"全局注意力"。中间还嵌入了一个16倍卷积压缩模块,专门用于削减token数量。
举例来说,一张1024×1024的图像,理论上需要切割成4096个区块进行处理,现在经过这个压缩模块的优化,直接缩减为几百个token。
经过这样的处理,既保留了足够的清晰度,又大幅降低了计算开销。

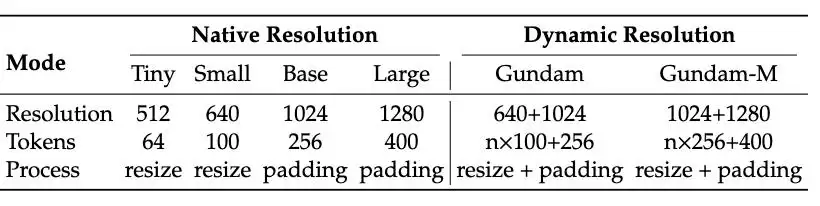
而且它还支持多分辨率模式:Tiny、Small、Base、Large,还有一个命名为"Gundam(高达)"的动态模式。
你没看错,这个模型连命名都带着点"二次元"风格。
解码器部分则是DeepSeek的拿手好戏:MoE(混合专家)架构。
64个专家中每次只激活6个,外加两个共享专家,实际算力仅动用了约5.7亿参数,但性能却媲美300亿模型。又快又省电,堪称"节能灯中的战斗机"。
它的任务也并不复杂:从那些压缩后的视觉token中,将文字信息"解码"还原。
整个过程就像是OCR的升级版——不过这次是模型自己在"看图猜字",而非人类教它识字,而且猜得相当准确。
当然,要让这套玩法真正奏效,必须准备充足的训练素材。DeepSeek这次可谓下足了本钱:整整3000万页PDF文档,涵盖100多种语言,其中中英文就占了2500万页。
他们还构建了一个"模型飞轮":先用版面分析模型进行粗标注,再用GOT-OCR之类的模型做精标,训练一遍后再反馈更多数据。如此循环往复,模型通过自我喂养不断成长。
除此之外,还有300万条Word文档,专门用于训练公式识别、HTML表格提取,甚至包括金融图表、化学结构式、几何图形等特殊图像结构,也都被纳入了训练集中。
DeepSeek还从LAION、Wukong这些开源数据集抓取了中英文各1000万张场景图,用PaddleOCR进行标注。
可以说,这一轮训练真正实现了"从理工科到艺术科全覆盖",是用海量数据喂养出来的聪明模型。
那么实际效果如何?论文中展示了几组测试结果,表现相当亮眼。
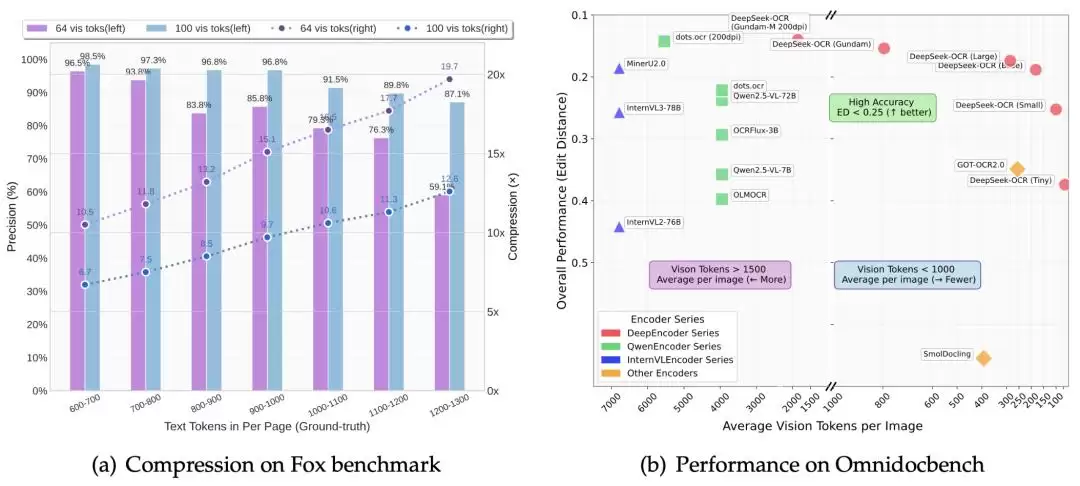
在OmniDocBench测试集上,DeepSeek-OCR仅用100个视觉token就超越了GOT-OCR2.0(每页256token)。用不到800个视觉token,又超越了MinerU2.0(每页6000+token)。
性能更强、输入更短、推理更快。

这样的处理速度,简直如同"AI印刷机"。
不过,最让我拍案叫绝的,是论文最后那个脑洞:光学压缩还能模拟人类遗忘?
人脑的记忆会随时间衰退,旧事逐渐模糊,新事清晰如昨。DeepSeek团队于是琢磨:AI能不能也学会"选择性记忆"?
如果AI也能像人一样"选择性记忆",是不是就能在超长对话中运转得更轻松?
他们设计了一个实验构想:超过k轮的历史对话内容就直接渲染成图像;先压缩一遍,减少10倍token;再把图像尺寸缩小一些;图像越小,信息越模糊,最终就"遗忘"了。

有网友看完直接感叹:这不就是在模拟人脑的记忆机制嘛!
当然,也有人泼冷水:DeepSeek的想象力已经够惊人了,要是再让它学会"遗忘",恐怕忘得比人还快。
我看完这部分内容,确实觉得颇具哲学意味。AI的记忆,究竟该无限扩展,还是该学会适时遗忘?
DeepSeek给出的答案是后者——它通过视觉方式,让模型在"压缩"的同时,也"过滤"掉冗余信息。就像人脑那样:只保留有用的内容。
这背后的意义,其实比OCR技术本身更为深远。
它重新定义了"上下文"的概念:不是记得越多越好,而是记得越精越妙。

说到底,DeepSeek-OCR看似是个OCR模型,实则是在探索一种新范式:能否用视觉模态来高效承载语言信息?
在所有人都追求"更大、更长、更贵"的方向时,DeepSeek却反手做了个"更小、更快、更巧"的模型。
这件事本身就很有DeepSeek的风格。
最后我想说的是:AI的进化路径,未必总是做加法,有时候做减法反而更显智慧。
DeepSeek-OCR就是一个鲜活的例子:一个30亿参数的小模型,却玩出了长文本压缩的新思路,甚至触碰到了"记忆与遗忘"的边界。
如果说去年的关键词是"谁能记住更多",那么今年,或许是"谁能忘得更聪明"。
而DeepSeek,这一次又走在了前列。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

最新消息称国行苹果iPhone 18 Pro Max电池容量达到了5391mAh增幅11.78%
国行iPhone18ProMax电池容量达5391mAh,较前代增幅11 78%,增量近568mAh;Pro机型仅小幅提升68mAh。爆料称最终数据待验证,若属实则续航将显著增强。

HMD发布四款诺基亚功能手机 配备AI按键与可拆卸电池
HMDGlobal推出4款诺基亚功能手机,均配1450mAh可拆卸电池及独立AI按键,支持语音控制,免费180天后付费。部分机型带摄像头,支持microSD卡扩展至32GB,具双SIM卡、3 5mm接口及蓝牙5 0。

云南以旧换新补贴扩围 新增智能影音与无人机
云南省自2026年7月起扩大消费品以旧换新补贴范围,新增智能门锁、智能影音、无人机、数码相机等数码智能产品及吸油烟机、燃气灶、洗碗机、净水器等家电。按最终售价15%补贴,每类每件最高1500元,商户报名无限制。

小米Redmi 7英寸高性能手机传闻即将发布
最近圈内又有新动静了。据博主 @数码闲聊站 今天爆料,某家厂商的子系列下一代打算推出两款屏幕尺寸差异明显的机型:一块是 6 59 英寸的中屏 Pro,另一块则是 7 英寸的巨屏性能机。从该博主以往的爆料习惯来看,基本可以锁定是小米 REDMI 品牌的产品线布局。 有意思的是,早在今年 2 月,这位博

深光影像AF35mmF2.2CE全画幅镜头E/L卡口739元起售
深光影像AF35mmF2 2CE全画幅镜头开售,提供E卡口和L卡口,标准版七百三十九元,套装版七百八十九元。全金属机身,重约一百七十五克,高三十六毫米,滤镜口径五十二毫米,光学结构五组七片,九片光圈叶片,最近对焦零点三五米,支持自动对焦。








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-05 13:32
2026-07-05 13:32
2026-07-05 13:31
2026-07-05 13:31
2026-07-05 13:30
2026-07-05 13:30
2026-07-05 13:30
2026-07-05 13:30
热门教程
2026-07-05 13:32
2026-07-05 13:32
2026-07-05 13:31
2026-07-05 13:31
2026-07-05 13:30
2026-07-05 13:30
2026-07-05 13:30
2026-07-05 13:30
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
