




LongCat Flash Omni开源:开启全模态实时交互新纪元

11月3日,LongCat-Flash系列迎来重要升级,全新家族成员LongCat-Flash-Omni正式发布并开源,LongCat最新App同步上线开启公测。目前新App已支持联网搜索、语音对话等功能,视频通话功能将稍后上线;Web端则新增了图片上传、文件传输与语音对话等实用功能。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

据了解,LongCat-Flash-Omni基于LongCat-Flash系列的高效架构设计(含Shortcut-Connected MoE与零计算专家机制),创新集成了高效多模态感知模块与语音重建模块。在总参数量达5600亿(其中激活参数270亿)的庞大模型规模下,仍实现了毫秒级的实时音视频交互能力,为开发者的多模态应用场景提供了更优质的技术解决方案。
这款新模型也成为业界首个实现"全模态覆盖、端到端架构、大参数量高效推理"三位一体的开源大语言模型,首次在开源范畴内实现了对标闭源模型的全模态能力,并凭借创新的架构设计与工程优化,让大模型在多模态任务中实现毫秒级响应,有效解决行业内推理延迟的痛点问题。
具体来看,LongCat-Flash-Omni在一体化框架中整合了离线多模态理解与实时音视频交互能力,采用完全端到端的设计理念——以视觉与音频编码器作为多模态感知器,由LLM直接处理输入并生成文本与语音token,再通过轻量级音频解码器重建为自然语音波形,从而实现低延迟的实时交互。所有模块均基于高效流式推理设计,视觉编码器与音频编解码器均为轻量级组件,参数量均约为6亿,延续了LongCat-Flash系列创新型高效架构的精髓,实现了性能与推理效率间的最佳平衡。
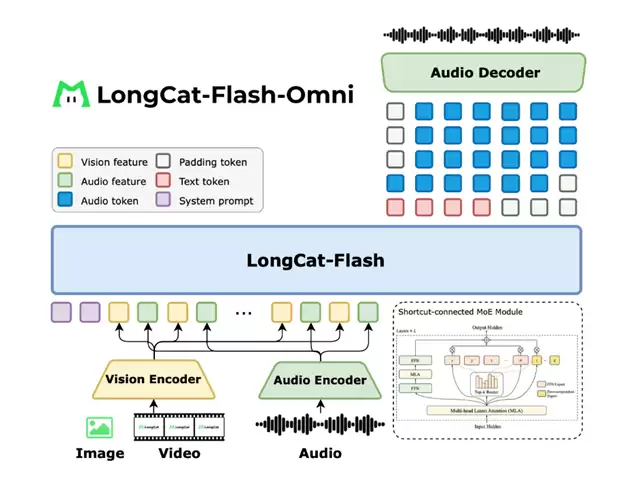
▲LongCat-Flash-Omni模型架构
与此同时,新模型突破了"大规模参数与低延迟交互难以兼顾"的技术瓶颈,在大规模架构基础上实现了高效实时音视频交互:模型总参数达5600亿(激活参数270亿),依托LongCat-Flash系列创新的ScMoE架构(含零计算专家)作为LLM骨干,结合高效多模态编解码器和"分块式音视频特征交织机制",最终实现了低延迟、高质量的音视频处理与流式语音生成。模型支持128K tokens上下文窗口及超8分钟音视频交互,在多模态长时记忆、多轮对话、时序推理等核心能力上表现优异。
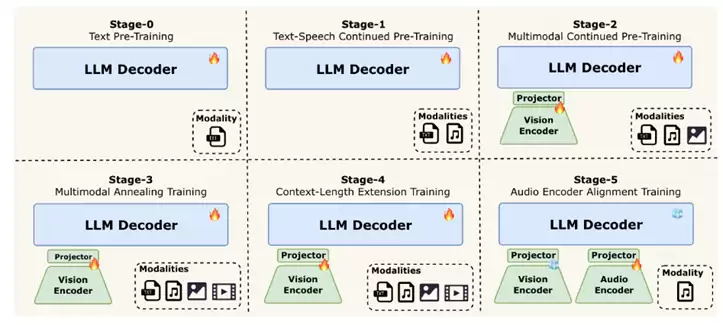
全模态模型训练的核心挑战之一是"不同模态的数据分布存在显著异质性"。LongCat-Flash-Omni采用渐进式早期多模态融合训练策略,在平衡数据策略与早期融合训练模式下,逐步融入文本、音频、视频等模态,确保全模态性能强劲且无任何单模态性能退化。
综合评估结果表明,LongCat-Flash-Omni在综合性的全模态基准测试(如Omni-Bench、WorldSense)上达到了开源最先进水平(SOTA),并在文本、图像、音频、视频等各项模态的能力位居开源模型前列,真正实现了"全模态不降智"的卓越成果:
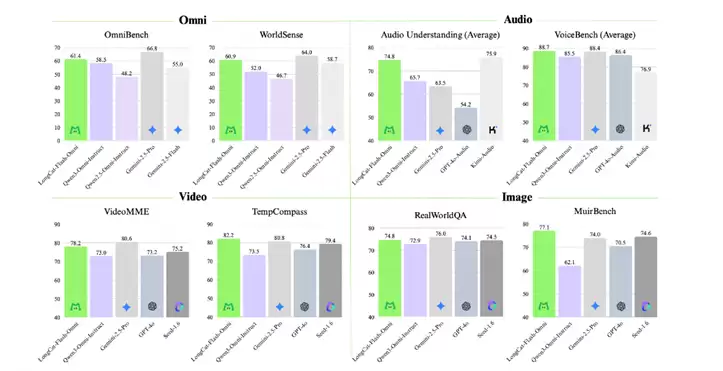
· ▲LongCat-Flash-Omni 的基准测试性能
文本能力:LongCat-Flash-Omni延续了该系列卓越的文本基础能力,且在多个领域均呈现领先优势。相较于LongCat-Flash系列早期版本,该模型不仅未出现文本能力的衰减,反而在部分领域实现了性能提升。这一结果不仅印证了团队训练策略的有效性,更凸显出全模态模型训练中不同模态间的潜在协同价值。
图像理解:LongCat-Flash-Omni在图文理解任务上的表现(RealWorldQA 74.8分)与闭源全模态模型Gemini-2.5-Pro相当,且优于开源模型Qwen3-Omni;多图像任务优势尤为显著,核心收益来源于高质量图文交织、多图像及视频数据集上的训练成果。
音频能力:从自动语音识别(ASR)、文本到语音(TTS)到语音续写维度进行全面评估,该模型在指令层面表现突出:ASR在LibriSpeech、AISHELL-1等数据集上优于Gemini-2.5-Pro;语音到文本翻译(S2TT)在CoVost2表现强劲;音频理解在TUT2017、Nonspeech7k等任务达到当前最优水平;语音对话在OpenAudioBench、VoiceBench表现优异,实时音视频交互评分接近闭源模型,在类人性指标上优于GPT-4o,实现了从基础能力到实用交互的高效转化。
视频理解:LongCat-Flash-Omni在视频到文本任务性能达到当前最优,短视频理解大幅优于现有参评模型,长视频理解比肩Gemini-2.5-Pro与Qwen3-VL,这得益于动态帧采样、分层特征聚合的视频处理策略,以及高效骨干网络对长上下文的支持。
跨模态理解:模型性能优于Gemini-2.5-Flash(非思考模式),比肩Gemini-2.5-Pro(非思考模式);尤其在真实世界音视频理解WorldSense基准测试上,相较于其他开源全模态模型展现出显著优势,印证了其高效的多模态融合能力,堪称当前综合能力领先的开源全模态模型。
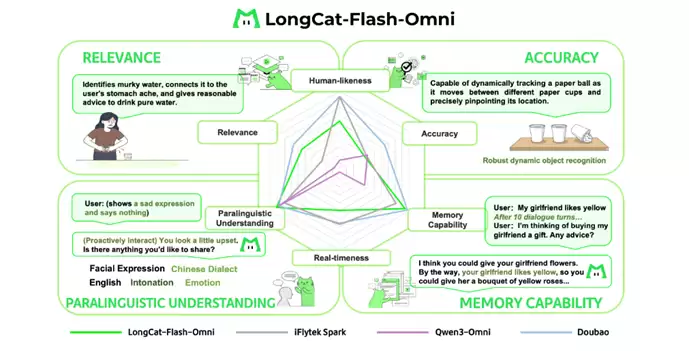
端到端交互:由于目前行业内尚未形成成熟的实时多模态交互评估体系,LongCat团队构建了一套专属的端到端评测方案。该方案由定量用户评分(250名用户评分)与定性专家分析(10名专家,200个对话样本)组成。定量结果显示:围绕端到端交互的自然度与流畅度,LongCat-Flash-Omni在开源模型中展现出显著优势——其评分比当前最优开源模型Qwen3-Omni高出0.56分;定性结果表明:LongCat-Flash-Omni在语义理解、相关性与记忆能力三个维度与顶级模型持平,但在实时性、类人性与准确性三个维度仍存在差距,也将在未来工作中持续优化。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

追觅宣布进军天文领域 构建“空天地一体化”生态
“我们的代码,终将写入繁星”:追觅科技成立天文BU,构建从地面到太空的生态闭环 “我们的代码,终将写入繁星。”这句来自追觅科技的宣言,不只是一句诗意的口号,更是一份清晰的战略升级路线图。就在9月10日,这家中国科技企业正式宣告成立天文业务单元(BU),由此完成了一次至关重要的战略跃迁。这标志着其“全

人类发现已知最大黑洞,质量达到太阳363亿倍!
天文学新纪录:观测到质量达太阳363亿倍的“极限”黑洞 最近的天文学界传来一个重磅消息。在距离我们大约50亿光年之外,一个代号为SDSS J1148+1930的星系中心,科学家们确认了一个庞然大物的存在——一个质量约为太阳363亿倍的超级黑洞。这个数字,直接刷新了人类已知黑洞的质量观测纪录。 你可能

下调降至150万颗!HBM4验证延迟拖累英伟达Rubin GPU量产
英伟达Rubin GPU量产进度调整,HBM4验证成关键变量 最近供应链传来消息,英伟达备受瞩目的下一代Rubin GPU,量产节奏可能要比预期慢上半拍。根据最新信息,其生产目标已从原先的200万颗下调至150万颗左右。这背后,下一代高带宽内存HBM4的验证进度,成了眼下最主要的制约因素。 产能布局

天问二号传回首幅地月合影 59万千米外定格为地球月球拍照
天问二号传回地月同框影像,深空探测新阶段迈出坚实一步 7月1日,国家航天局发布了一组颇具深意的影像——天问二号探测器在深邃的太空背景中捕捉到的地月同框画面。这组图像并非普通照片,而是由探测器上高精度的窄视场导航敏感器所拍摄,拍摄时机选在了探测器与地球、与月球距离均约59万千米的特殊位置上。经过科研团

外媒:近4000名NASA员工提交离职申请
近4000名NASA员工提交离职申请,占比高达两成 最近科技圈有个消息挺轰动,据外媒报道,美国国家航空航天局内部正经历一场不小的人事地震:有近4000名员工提交了离职申请。算下来,这差不多占了NASA员工总数的五分之一。 关于具体的裁员规模,美国宇航局发言人谢丽尔·华纳在官方声明里给出了更详细的数字








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
