




AI驱动Agent协作:文本终局中复制思维,Token效率飙升

机器之心报道编辑:陈陈在 Agentic AI 时代,模型不再是独来独往的学霸,而是开始学会组队、一起想问题。多智能体系统(MAS,multi-agent systems)的发展让 AI 世界从一个
机器之心报道
编辑:陈陈
在 Agentic AI 时代,模型不再是独来独往的学霸,而是开始学会组队、一起想问题。多智能体系统(MAS,multi-agent systems)的发展让 AI 世界从一个人苦想变成了多人头脑风暴。尤其是基于大语言模型的 MAS,如今已经被用在各种任务中。
不过,在这个组合里,AI 基本靠文本交流,最近有人开始思考:LLM 在大脑里(也就是潜在空间)想事情时,其实比说出来要丰富得多。
于是一些研究开始尝试让模型直接用隐藏层来表示想法,比如 (i) 用 Transformer 的隐藏表示来实现单模型的潜在链式思考推理, (ii) 使用 KV 缓存或层级嵌入在两个模型之间交换信息。
然而,一个能够同时统一潜在推理与潜在通信的全面模型协作框架仍未被探索出来。
为进一步推进这一方向,来自普林斯顿大学等机构的研究者提出:MAS 能否实现真正的纯潜在空间协作?
为回答这一问题,他们提出一种多智能体推理框架 LatentMAS,其将智能体之间的协作从传统的 token 空间转移到了模型的潜在空间。核心创新是:让所有智能体不再通过文本交流,而是在潜在空间中直接协作。
一直以来,传统 MAS 依赖自然语言沟通,各个 LLM 之间用文本交流思路。这种方法虽然可解释,但冗长、低效、信息易丢失。LatentMAS 则让智能体直接交换内部的隐藏层表示与 KV-cache 工作记忆,做到了:
高效的多步推理:在大幅减少 token 的情况下,实现更复杂的思考过程;无需训练的潜在空间对齐机制,确保生成过程稳定可靠;通用性强:可兼容任意 HuggingFace 模型,并可选择性地支持 vLLM 后端。
总体而言,LatentMAS 在多智能体系统中实现了更高的性能、更低的 token 使用量,以及显著的实际运行速度提升。
为了实证评估 LatentMAS 的有效性,本文在九个基准任务上进行了全面实验,这些任务涵盖数学与科学推理、常识理解和代码生成。
结果显示 LatentMAS 始终优于强大的单模型和基于文本的 MAS 基线:(i) 准确率最高提升 14.6%,(ii) 输出 token 使用量减少 70.8%-83.7%,(iii) 端到端推理速度加快 4×-4.3×。这些结果表明,潜在协作不仅提升了系统级推理质量,还在无需额外训练的情况下带来了显著的效率收益。

论文标题:Latent Collaboration in Multi-Agent Systems论文地址:https://arxiv.org/pdf/2511.20639GitHub 地址:https://github.com/Gen-Verse/LatentMAS
这篇文章也得到了很多人转发评论,可供大家参考。比如这位网友的观点很好的概括论文:
「在传统的多智能体系统中,我们通常让智能体 A 生成文本,再由智能体 B 读取并处理。这种文本瓶颈既浪费算力,又严重稀释语义信息。LatentMAS 带来了一种近乎心灵感应式的替代方案:智能体通过交换潜在思维来协作。
智能体 A 不再把推理结果解码成文本,而是将它的工作记忆,也就是注意力层中的 KV 缓存直接传给智能体 B。于是智能体 B 在启动时,仿佛已经加载了 A 的全部推理过程。
通过将第一个智能体生成的 KV 对直接注入第二个智能体的注意力机制中,第二个智能体会把前者的内部状态当作自己的提示,从而完全绕过离散的 token 化层。这种方法比基于文本的协作快 4.3 倍,并减少 80% 以上的 token 使用量。更重要的是,它无需昂贵的训练,只用简单的线性对齐就能让嵌入空间兼容。
智能体 A 的潜在思维被直接复制进智能体 B 的记忆之中。」
还有人认为这会终结基于文本的 AI:
方法介绍
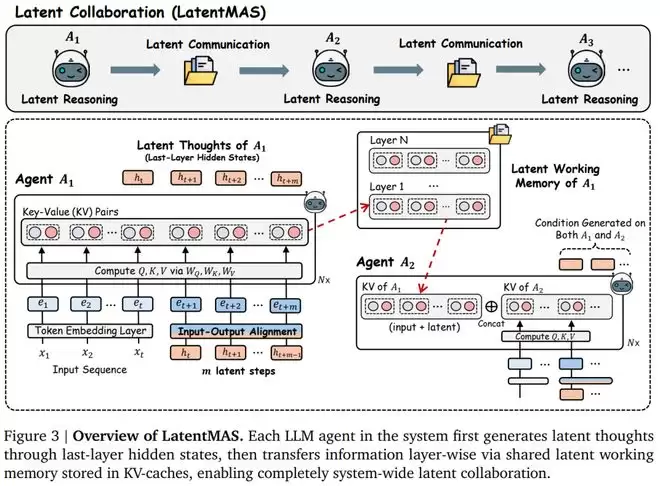
LatentMAS 是一个端到端的潜在协作框架:当给定一个输入问题时,所有智能体的推理与交流都完全在潜在空间中进行,只有最终答案才会被解码为文本输出。其核心设计结合了智能体的内部潜在思维生成与跨智能体潜在工作记忆传递。
在每个智能体内部,推理通过自回归地生成最后一层隐藏表示来展开,从而无需显式解码即可捕捉模型持续进行的内部思考;在智能体之间,信息通过存储在各层 KV 缓存中的共享潜在工作记忆进行交换,其中包含输入上下文以及新生成的潜在思维内容。
基于这些设计,LatentMAS 建立在三个基本原则之上,这些原则也通过全面的理论与实验分析得到了验证:
推理表达能力:隐藏表示天然地编码模型的连续思维,使得每一步潜在推理都能传递远比离散 token 更丰富的信息。通信保真度:潜在工作记忆完整保留了每个模型的输入表示与潜在思维,从而实现跨智能体的无损信息传递。协作复杂度:与 TextMAS 相比,LatentMAS 在协作表达能力更强的同时,其推理复杂度却显著更低。
前两个原则共同强调了 LatentMAS 的核心优势:它能够支持更丰富的潜在推理,并实现无损的潜在交流。第三个原则则从整体复杂度角度进一步说明:LatentMAS 在保持高表达能力的前提下,其计算复杂度远低于基于文本的 MAS。
该方法使系统中的 LLM 智能体能够:
(i)在潜在空间中生成具有超强表达能力的潜在思维;
(ii)在智能体交互过程中,以无损的方式保留并传递各自的潜在工作记忆;
(iii)在保持与传统 TextMAS 相同表达能力的同时,实现显著更低的计算复杂度。
实验
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:AI驱动Agent协作:文本终局中复制思维,Token效率飙升要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点小米MiMo开放平台宣布,MiMo-V2系列的四款模型将于2026年6月30日正式下线,平台已推动开发者向V2 5系列迁移。具体涉及mimo-v2-pro、mimo-v2-omni、mimo-v2-flash和mimo-v2-tts模型。平台设置了系统替换时间作为缓冲:pro和omni模型于2026
2026重庆车展上,2026款长安猎手K50正式上市,共推出10款车型,售价14 19万至17 89万元。新车主要针对续航、电池和动力进行升级,搭载2 0T增程系统与双电机,纯电续航超180公里,快充仅需16分钟。全系标配30kW外放电功能,储备电量达239kWh,并新增山地与涉水模式,提升通过性。
上海期货交易所与上海市普陀区人民政府于6月12日签署战略合作协议,旨在建立长期共赢的合作机制,共同服务上海国际金融中心与国际贸易中心的联动发展。双方高层领导均出席签约仪式,彰显了对此次合作的高度重视。协议聚焦于发挥期货市场专业资源与区域发展综合优势,深化务实合作,探索金融创新与实体经济深度融合,以期
6月12日,世纪华通发生一笔大宗交易,以每股14 37元的价格成交757 24万股,成交总额为1 09亿元。值得注意的是,该成交价与当日市场收盘价持平,属于平价交易。此次交易额占该股当日总成交额的1 51%。市场分析认为,平价成交反映了买卖双方对当前股价水平的共识,交易行为相对平稳,未对市场预期造成
- 日榜
- 周榜
- 月榜
热点快看