




通义千问Qwen3-TTS两款AI语音模型发布:支持定制与声音复刻

12 月 24 日消息,阿里通义今日官宣,Qwen3-TTS 家族新推出两款模型,音色创造模型 Qwen3-TTS-VD-Flash 和音色克隆模型 Qwen3-TTS-VC-Flash。附模型主
12月24日消息,阿里通义今日正式发布Qwen3-TTS家族的两款全新模型:音色创造模型Qwen3-TTS-VD-Flash与音色克隆模型Qwen3-TTS-VC-Flash。两款模型的主要特性如下:
音色创造:Qwen3-TTS-VD-Flash支持用户通过复杂、自然的语言指令输入,实现对音色、韵律、情感乃至人设的精细化调控。它让用户能够全面掌控从“说什么”到“如何说”的整个过程,自由定义心中想要的语音特质。这彻底改变了以往只能克隆现有音色,或是在有限预设音色库中进行选择的局面。
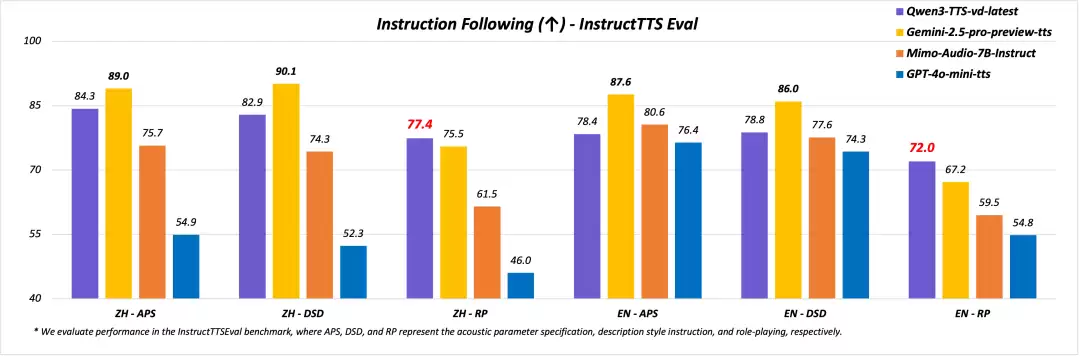
在InstructTTS-Eval评测中,其综合表现显著优于GPT-4o-mini-tts和Mimo-audio-7b-instruct;在角色扮演测试中也超越了Gemini-2.5-pro-preview-tts。
音色克隆:Qwen3-TTS-VC-Flash支持仅需3秒音频即可完成音色克隆,并能基于克隆出的音色,生成涵盖中文、英文、德语、意大利语、葡萄牙语、西班牙语、日语、韩语、法语、俄语等10大主流语言的语音。
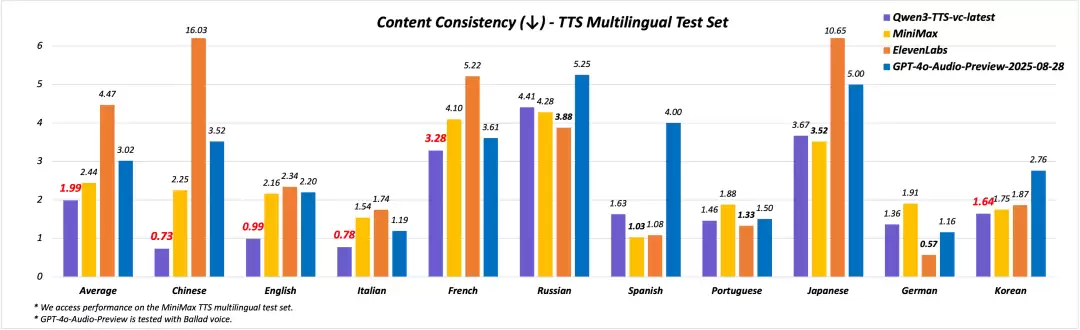
在MiniMax TTS Multilingual Test Set上,其平均词错误率(WER)全面低于MiniMax、ElevenLabs及GPT-4o-Audio-Preview。
高表现力:无论是Qwen3-TTS-VD-Flash还是Qwen3-TTS-VC-Flash,都具备高度拟人化的自然音色。它们能够稳定、可靠地输出与文本内容高度契合的语音,并依据文本语义自动调节语气节奏,呈现出自然生动的表达效果。
鲁棒的文本能力:两款模型均拥有强大的文本解析能力,可自动处理复杂文本结构,精准提取关键信息。对于多样化、非规范化的文本格式,都展现出较强的鲁棒性(注:鲁棒性指系统在面临内部结构或外部环境的变化时,维持功能稳定运行的能力)。
Qwen3-TTS-VD-Flash
该模型支持用户通过自然语言描述来生成定制化的音色形象。您只需随意输入有关声学属性、人设描述、背景信息等自由描述,即可轻松创造出自己期望的语音形象。
可控的生成质量:在InstructTTS-Eval评测中,Qwen3-TTS的综合表现显著优于GPT-4o-mini-tts和Mimo-audio-7b-instruct;在角色扮演测试中也超越了Gemini-2.5-pro-preview-tts。
Qwen3-TTS-VC-Flash
该模型支持通过自然语音进行3秒级别的音色克隆。基于克隆出的音色,可生成多语种音频,同时对复杂文本和带有环境背景音的“野生”音频都具有较高的处理鲁棒性。
多语种音色克隆:在MiniMax TTS Multilingual Test Set上,Qwen3-TTS在中、英、法、意等语种的内容稳定性方面优于MiniMax、ElevenLabs及GPT-4o-Audio-Preview;其平均词错误率(WER)也位居第一。
Qwen3-TTS-Voice-Design API 文档:
https://www.alibabacloud.com/help/zh/model-studio/qwen-tts-voice-design?spm=a2ty_o06.30285417.0.0.56a0c9216Ey6VM
Qwen3-TTS-Voice-Clone API 文档:
https://www.alibabacloud.com/help/zh/model-studio/qwen-tts-voice-cloning?spm=a2ty_o06.30285417.0.0.56a0c921WnHNlN
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:通义千问Qwen3-TTS两款AI语音模型发布:支持定制与声音复刻要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点客服需用标准化话术应对投诉,先归类前5类高频问题,再按情绪安抚、事实澄清(按需)、解决方案三层结构设计模板,并在阶跃AI后台配置变量话术且通过模拟测试后启用。客户投诉时情绪往往激烈,客服若临时组织语言容易词不达意、激化矛盾,需要一套能快速调用、语气得体、覆盖高频场景的标准化话术模板。 梳理投诉类型
通义千问系列模型升级至Qwen2,涵盖0 5B至72B共五个尺寸,全部标配分组查询注意力机制,上下文长度最高支持128Ktokens。新增27种语言训练数据,在代码、数学等能力上显著提升,Qwen2-72B超越Llama-3-70B等顶尖开源模型。
腾讯发布混元文生图大模型加速库,生图时间缩短75%,支持ComfyUI界面与HuggingFace三行调用。作为业内首个中文原生DiT架构开源模型,支持中英双语输入,最低11GB显存。
StabilityAI推出StableAudioOpen1 0,专门用于生成鼓点、乐器乐段及环境音效等短音频片段,时长最长47秒。该模型遵循非商业研究社区协议开源,允许用户进行微调,训练数据源自FreeSound及免费音乐档案,确保不含版权材料,可用于研究和创作。
- 日榜
- 周榜
- 月榜
热点快看