




英伟达开源128K记忆压缩方案,免额外缓存提速2.7倍

闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
提升大模型记忆能力,美国开源巨头英伟达也拿出了新方案。
联合Astera研究所、斯坦福大学、UC伯克利、加州大学圣迭戈分校等机构,推出了名为TTT-E2E的创新方法。
在128K超长文本处理上,其速度比传统注意力模型快2.7倍,处理2M上下文时提速更达到35倍,性能表现令人印象深刻。
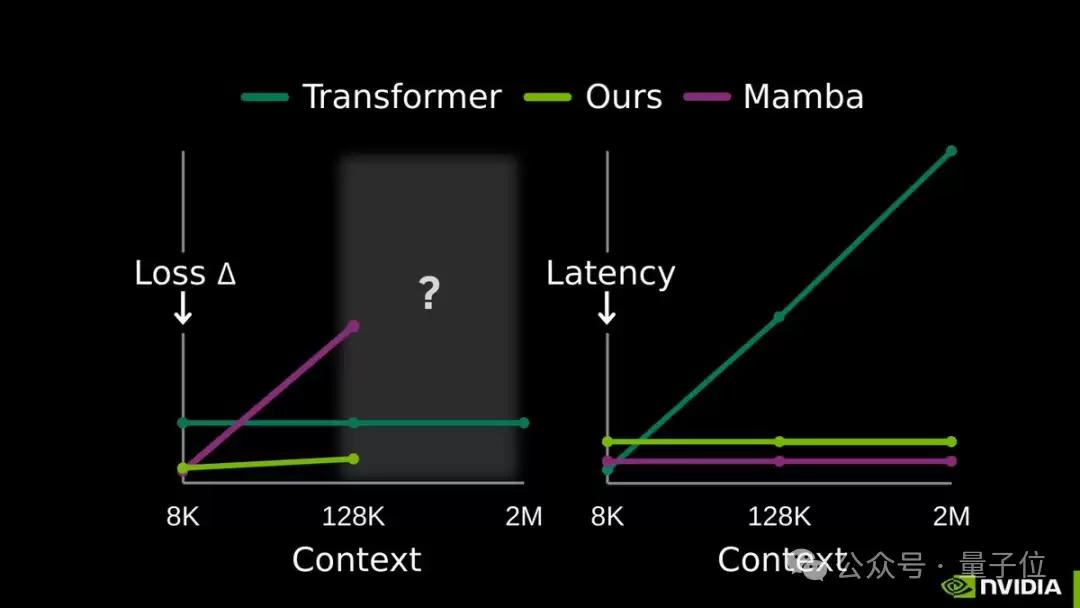
这项技术与近日备受关注的DeepSeek条件记忆模块有所不同。
DeepSeek的Engram模块采用“按需查表”的静态学习路径,而英伟达则选择了动态学习的思路,关键在于对上下文进行压缩。
通过实时学习将关键信息压缩到自身权重中,让模型在测试阶段依然保持学习状态。
这样既避免了额外缓存的负担,又能精准捕捉长文本中的核心逻辑。
为模型装上记忆压缩包
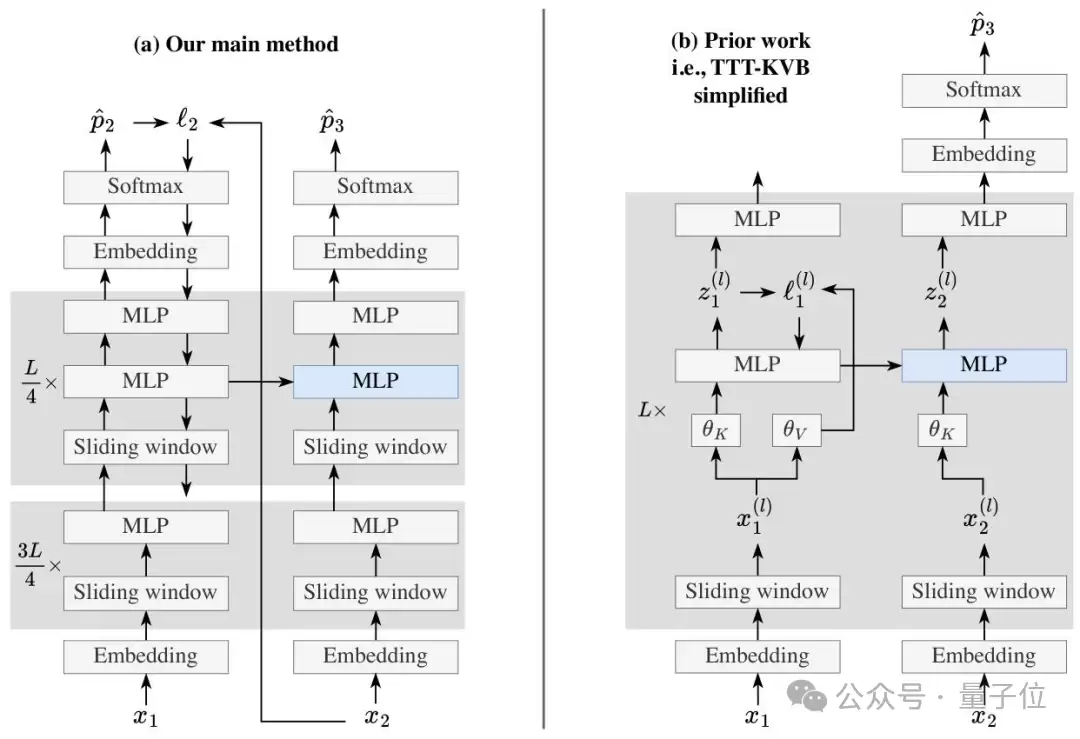
TTT-E2E并未依赖复杂特殊架构,而是基于带滑动窗口注意力的标准Transformer,部署起来更为简便。
该方法的核心思路,是将长文本建模从架构设计问题转化为“持续学习”任务。
在测试阶段,模型会基于当前读取的上下文进行下一个词预测。
每读取一段文本,就通过梯度下降更新自身参数,通过这种方式持续训练自身,把读到的文本信息动态压缩到权重中,这样就不用额外存储冗余数据。
在训练阶段,团队通过元学习为模型做初始化准备,让模型天生适应“测试时学习”的模式。
把每个训练序列都模拟成测试序列,先在内循环中对其进行测试时训练,再在外循环中优化模型的初始参数,确保初始状态就能快速适配测试时的学习需求,实现了训练与测试的端到端对齐优化。
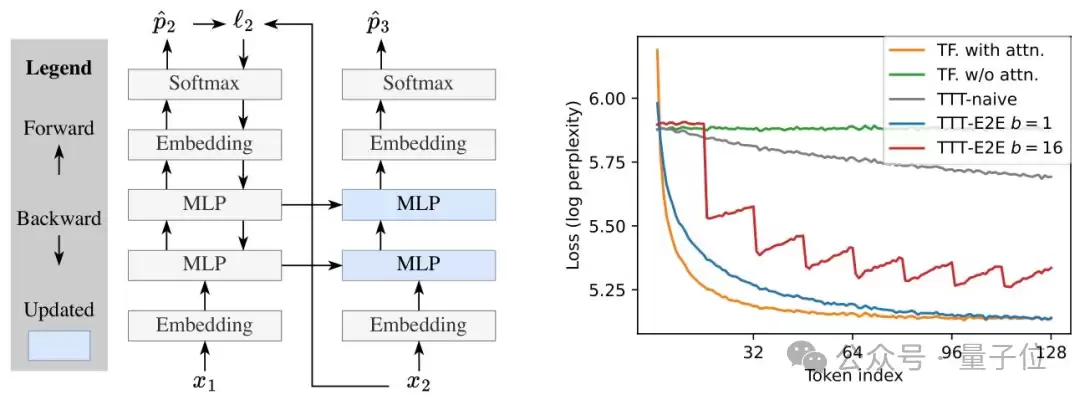
为了平衡效率与稳定性,TTT-E2E还设计了三项关键优化。
一是采用“迷你批处理+滑动窗口”的组合策略。将测试时的训练数据分成多个迷你批,配合8K大小的滑动窗口注意力,既解决了单token梯度更新易爆炸的问题,又保证模型能记住批内上下文,提升计算并行度;
二是精准更新策略。只更新模型的MLP层(冻结嵌入层、归一化层和注意力层),并且只更新最后1/4的网络块,在减少计算成本的同时避免参数更新混乱;
三是双MLP设计。在需更新的网络块中加入一个静态MLP层,专门存储预训练知识,另一个动态MLP层负责吸收新上下文,来防止模型学新忘旧。

从实验数据来看,TTT-E2E的表现相当亮眼。
在3B参数模型的测试中,TTT-E2E在128K上下文长度下的测试损失与全注意力Transformer持平甚至更优,而Mamba 2、Gated DeltaNet等同类模型在长文本场景下性能均出现明显下滑;
在延迟上,它的推理延迟不随上下文长度增加而变化,与RNN类似,在H100显卡上处理128K文本时,速度比全注意力模型快2.7倍。
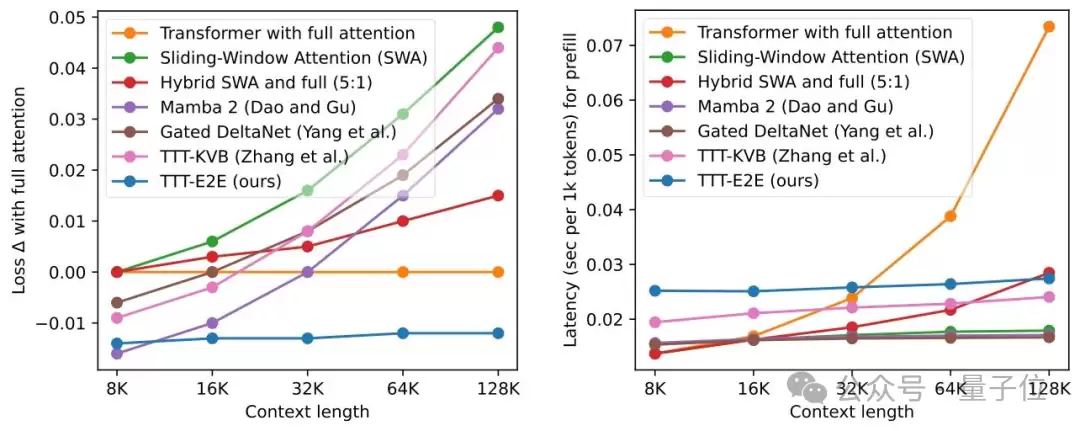
在解码长序列任务中,经Qwen-8B模型评估,TTT-E2E生成的文本质量稳定,损失值持续低于传统模型。
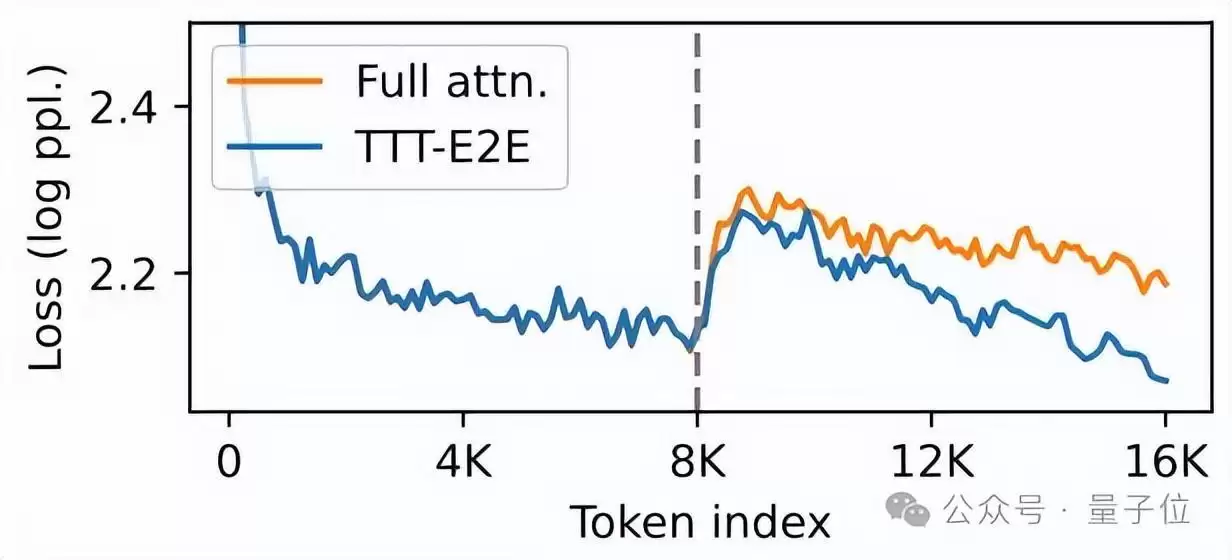
通过实验结果也可以看出,该方法的推理延迟与上下文长度无关,始终保持恒定,这也意味着无论处理8K还是128K文本,用户都能获得一致的快速响应体验。
不过,TTT-E2E也存在一些小局限。
在大海捞针这类需要精准回忆细节的任务中,它的表现远不如全注意力模型。
这是因为它的核心是压缩记忆,会过滤掉看似无关的细节,而全注意力模型能近乎无损地召回所有信息。
另一方面,训练阶段的元学习需要计算梯度的梯度,目前实现比标准预训练要慢。
目前,TTT-E2E的代码和相关论文已完全开源。

这项研究的项目总负责人是斯坦福的博士后研究员Yu Sun,他也是该研究的核心贡献者。
他研究的总体目标是让人工智能系统能够像人类一样持续学习。自2019年以来,他就在开发“测试时训练”的概念框架,TTT-E2E项目的早期构想就是由他提出的。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Inception获吴恩达Karpathy天使轮投资为何受微软SpaceX青睐
扩散模型,这个在图像和视频生成领域大杀四方的技术,如今正将战火烧到了文本生成的核心腹地。一场围绕它的争夺战,已经在科技巨头之间悄然打响。 当前AI行业看似高歌猛进,但狂热之下,一个根本性的忧虑始终存在:以大语言模型(LLM)为代表的自回归架构,是否已经触及天花板?下一代AI的王者,会不会诞生于一条全

龚宇谈AI如何赋能影视行业科技与创作融合新路径
4月21日,爱奇艺创始人兼CEO龚宇深度阐述了AI技术对影视行业的变革意义。他着重指出,科技发展的核心逻辑在于赋能于人,而非简单替代。在影视制作领域,AI的应用目标清晰且具有层次:首要任务是服务广大观众,通过技术创新驱动内容生产,实现作品在数量、质量与精彩程度上的全面跃升;其次,是为包括演员、导演、

AI写真制作教程 即梦AI效果实测与使用指南
想要通过即梦AI生成足以媲美专业摄影的个人写真,却总感觉成品不够真实自然?问题的关键往往在于对生成流程的细节把控。从一张普通的生活照到一张以假乱真的AI写真,其核心在于精准理解模型特性并巧妙运用提示词。以下这套经过实践验证的五步操作法,将系统性地指导你跨越这道技术鸿沟,轻松获得理想效果。 一、准备高

豆包App上线博物馆AI导览功能支持边走边听讲解
5月18日,字节跳动旗下豆包App重磅推出“博物馆讲解”新功能,为文博爱好者与普通游客带来了全新的智能观展体验,让逛博物馆变得更加轻松、有趣且富有深度。 如何使用这项AI博物馆讲解服务?操作流程非常简单便捷。当您身处博物馆展厅时,只需打开豆包App,在对话框内找到并点击“博物馆讲解”功能按钮,即可开

Trae多文件编辑如何批量修改关联文件并保持内容一致
在团队协作开发或进行大规模项目重构时,开发者常面临一个普遍难题:当需要修改一个被多处引用的函数或变量时,如何高效、准确地同步更新所有相关文件?手动逐一查找并修改不仅耗时费力,而且极易因遗漏或误改导致代码逻辑不一致,引发难以排查的运行时错误。 如果你正在使用Trae代码编辑器,并因需要同步修改多个存在








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
