




Inception获吴恩达Karpathy天使轮投资为何受微软SpaceX青睐


扩散模型,这个在图像和视频生成领域大杀四方的技术,如今正将战火烧到了文本生成的核心腹地。一场围绕它的争夺战,已经在科技巨头之间悄然打响。
当前AI行业看似高歌猛进,但狂热之下,一个根本性的忧虑始终存在:以大语言模型(LLM)为代表的自回归架构,是否已经触及天花板?下一代AI的王者,会不会诞生于一条全新的技术路径?
最近的一则消息,似乎正在为这个疑问添加注脚。5月13日,外媒曝出微软正在与一家名为Inception的初创公司洽谈收购。巧合的是,同一天,马斯克的SpaceX也被证实对这家公司展开了追求。
一家种子轮融资仅5000万美元、由吴恩达和安德烈·卡帕西(Andrej Karpathy)等顶尖AI人物天使投资的创业公司,如今估值被喊到超过10亿美元,溢价高达20倍。吸引两家万亿美元级巨头同时下场的,并非什么成熟的商业模式,而是一支来自斯坦福的教授团队,以及一条几乎无人涉足的技术路线。
这家与诺兰电影《盗梦空间》同名的初创公司,究竟有何非凡之处?
01 三个教授与一个“异端”想法
Inception的故事,始于其创始人之一——斯坦福大学计算机科学教授斯特凡诺·埃尔蒙(Stefano Ermon)。他更为人知的身份,是扩散模型(Diffusion Model)的共同发明人。如今风靡的Midjourney、Sora、Stable Diffusion,底层都运行着他参与开创的技术。他关于文本扩散的论文,曾荣获ICML 2024最佳论文奖。
2024年中,埃尔蒙从斯坦福休假,联合了两位合作超过十年的老搭档——加州大学洛杉矶分校教授阿迪亚·格罗弗(Aditya Grover)和康奈尔大学教授弗拉基米尔·库列绍夫(Volodymyr Kuleshov),在帕洛阿尔托共同创立了Inception Labs。
这三个人怀揣着一个在当时看来相当“离经叛道”的想法:将扩散模型从图像生成领域,彻底迁移到文本生成领域,以此替代现有的自回归架构。
这个想法很快引起了业界注意。安德烈·卡帕西在Inception发布首个模型时,就在社交平台X上表达了浓厚兴趣。他指出,当前几乎所有大语言模型在核心建模方法上都是“克隆体”,遵循从左到右逐个预测词元(token)的自回归模式。而扩散模型完全不同,它不是顺序生成,而是从噪声中逐步去噪,最终并行得到一个完整的词元序列。他认为这个模型“有潜力展现出全新且独特的能力特征”,并鼓励大家尝试。
卡帕西不只是口头支持。他与吴恩达(Andrew Ng)都以天使投资人的身份,参与了Inception的种子轮融资。
2025年11月,Inception完成了5000万美元的种子轮融资,由Menlo Ventures领投,英伟达旗下NVentures、微软旗下M12、Snowflake Ventures、Databricks的投资部门全部跟投。
当卡帕西和吴恩达同时押注一家公司,当英伟达和微软的战投基金同时出现在投资人名单上,这几乎构成了AI领域最顶级的信任背书。
02 快10倍,便宜10倍
要理解Inception为何受到如此追捧,关键在于看清其技术路线的根本差异。
如今我们使用的ChatGPT、Claude、Gemini,底层无一例外都是自回归模型。它们生成文本的方式如同串行流水线:一个词元接一个词元,从左到右,依次输出。在写下后一个字之前,必须等待前面所有的字都生成完毕。
这就像一位作家,只能逐字逐句地线性创作,绝不允许跳着写。
这种方法稳定可靠,但存在一个结构性的天花板:速度被串行生成的方式锁死了。你可以更换更强大的芯片,优化推理框架,或者压缩模型,但只要本质仍是逐词元生成,速度就存在理论上限。
Inception选择了一条截然不同的道路。它利用扩散模型进行文本生成——不是逐字书写,而是先给出一个“粗略草稿”,然后通过神经网络反复迭代精炼,同时修改多个词元,实现并行输出。
埃尔蒙对此的解释非常直白:“这是一种根本不同的方法。所有现有的大语言模型都是自回归的,一个接一个地从左到右生成文本或代码,这非常慢,因为你不能在生成前面所有内容之前生成后面的东西。”
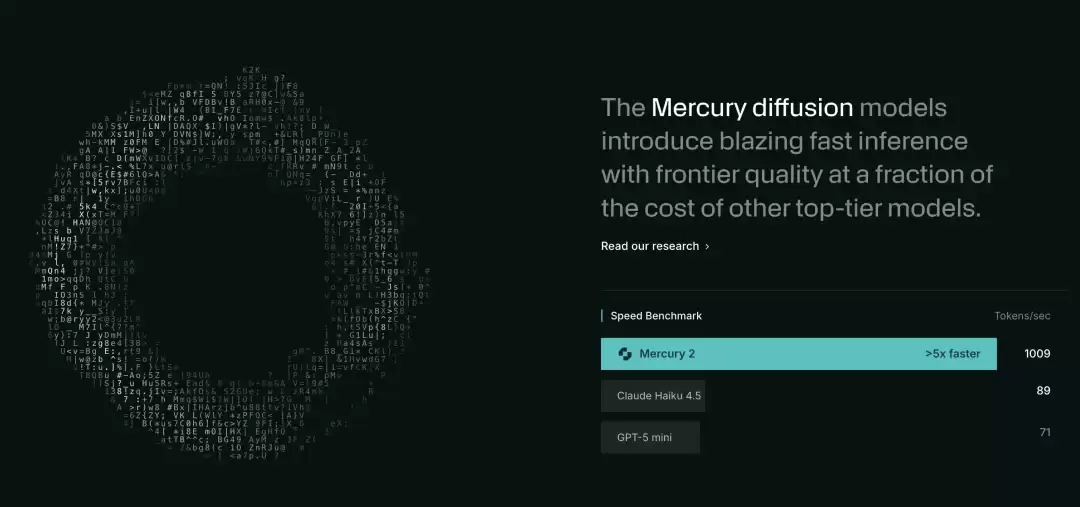
Mercury 2 模型在每秒 token 输出上比流行的小模型更快|图片来源:Inception
实际效果如何?Inception推出的模型家族名为Mercury。根据第三方评测机构Artificial Analysis的测试,其于2026年2月发布的Mercury 2模型,输出吞吐量达到了每秒约1000个词元。作为对比,Claude 4.5 Haiku约为每秒89个词元,GPT-5 Mini约为每秒71个词元。速度优势达到了10到14倍。
在质量方面,Mercury 2在AIME 2025测试中得分91.1,GPQA得分73.6,LiveCodeBench得分67.3。这些分数与Claude 4.5 Haiku、GPT-5.2 Mini处于同一竞争区间,但吞吐量却是后者的十倍以上。
埃尔蒙对此也很坦诚——Mercury 2对标的是Haiku和Flash这个级别的模型,而非Claude Opus或GPT-4这类旗舰。第三方分析也指出,在复杂推理任务上,扩散模型的质量大约是前沿自回归模型的85%-95%,但在结构化输出和翻译等任务上已基本持平。
而这恰恰是其想象力所在。如果扩散模型在质量上的差距仅有5%-15%,而速度优势却高达10倍,那么在对延迟极度敏感的大量场景中——如实时语音交互、代码自动补全、游戏对话、智能体(Agent)循环调用——扩散模型将成为更实际、更经济的选择。
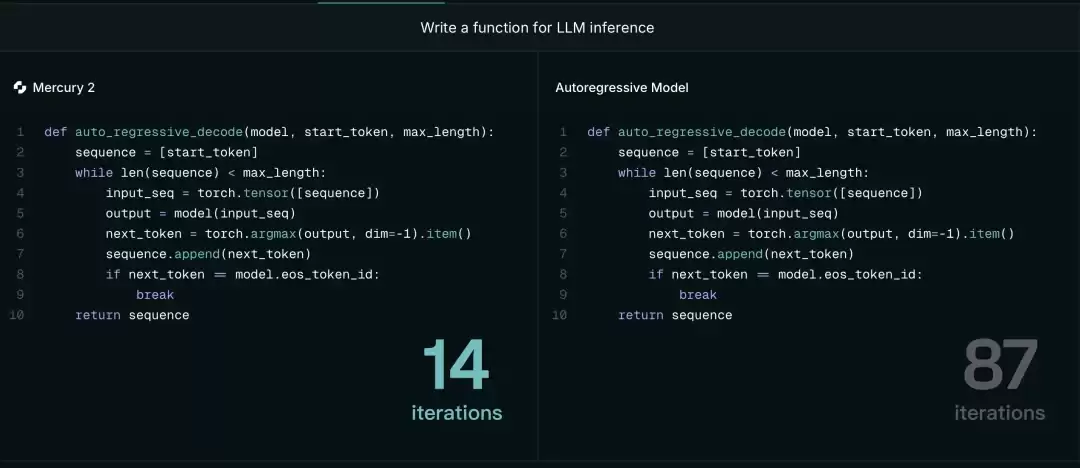
代码构建上 Mercury2 模型只用迭代 14 次,而其他模型要迭代 87 次|图片来源:Inception
此外,扩散框架还带来了几个自回归模型难以企及的结构性优势。
第一,输出可控性更强。扩散模型能更自然地遵循特定的模式(schema)和语义约束,生成符合指定格式的JSON输出,这对于企业级应用至关重要。
第二,天然支持多模态融合。扩散本就是图像和视频生成的底层范式,将其扩展到文本,意味着可以用一套统一的框架处理语言、图像、音频和视频,无需拼接不同架构。
第三,内置纠错能力。自回归模型一旦在前序生成中间出现错误,后续内容很难修正;而扩散模型在精炼过程中可以反复调整,理论上能减少“幻觉”现象。
当然,这条路线也伴随着明显的不确定性。一些AI研究者指出,扩散方法使得输出预测更加困难,其扩展定律(Scaling Law)尚未得到充分验证。自回归模型“参数越多、数据越多、效果越好”的规律花了数年才被摸清,扩散模型是遵循类似规律,还是需要完全不同的优化策略,目前尚无定论。
但或许,正是这种不确定性,才蕴藏着碘伏现有范式的可能。
03 “后OpenAI时代”的军备竞赛
理解了Inception的技术内核,再来看微软与SpaceX的争夺,逻辑就清晰了。
2026年4月27日,微软与OpenAI官宣了对合作关系的重大调整。微软对OpenAI模型的IP授权从独家变为非独家,有效期延长至2032年;微软不再向OpenAI支付收入分成;OpenAI被允许在AWS、Google Cloud等任何云平台提供服务;关于AGI(通用人工智能)的特别条款被彻底删除。
这段曾被称作“科技界最佳兄弟情”的关系,实质上已演变为“管理型竞争”。
微软在OpenAI身上投入了超过130亿美元的资金以及大量的Azure算力支持。但现在,OpenAI不再是微软的“独家武器”,而微软也在加速摆脱对OpenAI的依赖。据报道,微软正在开发自己的通用AI模型,目标是在2027年之前推出能与OpenAI、Anthropic正面竞争的前沿模型。
收购像Inception这样的AI创业公司,正是这一战略的关键组成部分。
路透社的报道披露,微软今年春天首先看中了代码生成公司Cursor,但因自身已拥有GitHub Copilot,内部担心反垄断审查难以通过,最终主动放弃。随后,SpaceX迅速与Cursor签署了一份价值高达600亿美元的收购期权协议——即便收购不成,SpaceX也需支付100亿美元的合作费用。
在放弃Cursor后,微软将目光转向了Inception。然而,SpaceX同样盯上了这家公司。目前,Inception已聘请投行操盘交易谈判,要价超过10亿美元。
SpaceX的介入让局面更加有趣。2026年2月,SpaceX以全股票交易方式收购了马斯克的xAI,合并后估值达到1.25万亿美元,成为有史以来估值最高的商业并购案之一。随后,SpaceX又启动了Terafab半导体工厂项目,与特斯拉和xAI联合建设。再加上对Cursor的收购期权和对Inception的追求,马斯克显然正以SpaceX为平台,系统性地构建一个从芯片、模型到应用的完整AI技术栈。
而微软这边,除了竞购Inception,也同时在接触多家AI创业公司。路透社引述知情人士称,当前AI研究人员轻松就能获得数千万美元的薪酬承诺,创业公司估值在投资者的疯狂追捧下水涨船高。
Menlo Ventures合伙人蒂姆·塔利(Tim Tully)在Inception融资时说过一句话,放在今天的收购大战背景下格外应景。他说,Inception的团队证明了扩散式大语言模型不只是一个研究突破,而是“一个可以构建可扩展、高性能语言模型的基础,企业今天就能部署”。
这句话道破了天机——巨头们争夺的不仅仅是一家公司,更是一个可能改写游戏规则的技术范式,以及掌握这个范式核心密码的那一小群人。
当微软与OpenAI的“婚姻”走向开放关系,当SpaceX从火箭公司转型为AI收购引擎,当一家尚在种子轮的公司被两家万亿巨头同时争抢——这场“后OpenAI时代”的AI军备竞赛,其实才刚刚拉开序幕。
而Inception的命运,无论最终花落谁家,都已经揭示了一个不变的真理:在AI的世界里,真正稀缺的从来不是海量资本,而是敢于踏上不同道路的智慧与勇气。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Inception获吴恩达Karpathy天使轮投资为何受微软SpaceX青睐
扩散模型,这个在图像和视频生成领域大杀四方的技术,如今正将战火烧到了文本生成的核心腹地。一场围绕它的争夺战,已经在科技巨头之间悄然打响。 当前AI行业看似高歌猛进,但狂热之下,一个根本性的忧虑始终存在:以大语言模型(LLM)为代表的自回归架构,是否已经触及天花板?下一代AI的王者,会不会诞生于一条全

龚宇谈AI如何赋能影视行业科技与创作融合新路径
4月21日,爱奇艺创始人兼CEO龚宇深度阐述了AI技术对影视行业的变革意义。他着重指出,科技发展的核心逻辑在于赋能于人,而非简单替代。在影视制作领域,AI的应用目标清晰且具有层次:首要任务是服务广大观众,通过技术创新驱动内容生产,实现作品在数量、质量与精彩程度上的全面跃升;其次,是为包括演员、导演、

AI写真制作教程 即梦AI效果实测与使用指南
想要通过即梦AI生成足以媲美专业摄影的个人写真,却总感觉成品不够真实自然?问题的关键往往在于对生成流程的细节把控。从一张普通的生活照到一张以假乱真的AI写真,其核心在于精准理解模型特性并巧妙运用提示词。以下这套经过实践验证的五步操作法,将系统性地指导你跨越这道技术鸿沟,轻松获得理想效果。 一、准备高

豆包App上线博物馆AI导览功能支持边走边听讲解
5月18日,字节跳动旗下豆包App重磅推出“博物馆讲解”新功能,为文博爱好者与普通游客带来了全新的智能观展体验,让逛博物馆变得更加轻松、有趣且富有深度。 如何使用这项AI博物馆讲解服务?操作流程非常简单便捷。当您身处博物馆展厅时,只需打开豆包App,在对话框内找到并点击“博物馆讲解”功能按钮,即可开

Trae多文件编辑如何批量修改关联文件并保持内容一致
在团队协作开发或进行大规模项目重构时,开发者常面临一个普遍难题:当需要修改一个被多处引用的函数或变量时,如何高效、准确地同步更新所有相关文件?手动逐一查找并修改不仅耗时费力,而且极易因遗漏或误改导致代码逻辑不一致,引发难以排查的运行时错误。 如果你正在使用Trae代码编辑器,并因需要同步修改多个存在








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
