




复旦×创智团队推出新语音模型,超越GPT与Gemini优势解析


编辑|泽南、杜伟
在语音大模型赛道上,GPT-4o、Gemini 的能力遥遥领先。
近日,由复旦邱锡鹏担任首席科学家的模思智能发布了多说话人自动语音识别(ASR)模型 MOSS-Transcribe-Diarize,不但可以语音转文字,还可以将音频片段与对话中不同的说话者关联起来,性能超过了 GPT-4o、Gemini、豆包等一众模型。
多人说话场景的语音转录是语音识别领域的落地痛点问题。以往模型一旦遇到多人抢着说话就可能听不清、记不准。现在 MOSS-Transcribe-Diarize 摸透了多人说话逻辑,能够轻松应对混乱插话、频繁切话或者重叠说话等复杂场景,真正掌握了「说哪记哪、听声辩人」的技能。
MOSS-Transcribe-Diarize 在语音识别与分析领域具有突破性意义,解决了语音领域最后的落地痛点。MOSS-Transcribe-Diarize 支持 128K 的长上下文窗口,可以一次性输入并处理长达 90 分钟的音频,突出了复杂场景下的抗干扰能力。
MOSS-Transcribe-Diarize 的跑分成绩同样亮眼。在 AISHELL-4、Podcast、Movies 等多个语音基准测试中,模型均取得了业界最优(SOTA)的整体表现。尤其是在影视剧场景下,背景音更杂、多人同时说话、频繁插话、声音重叠,是语音转录里最乱、也最接近真实应用的情况。即便面对这样的复杂语音条件,MOSS-Transcribe-Diarize 依然稳定跑出了当前业界最优的整体成绩:
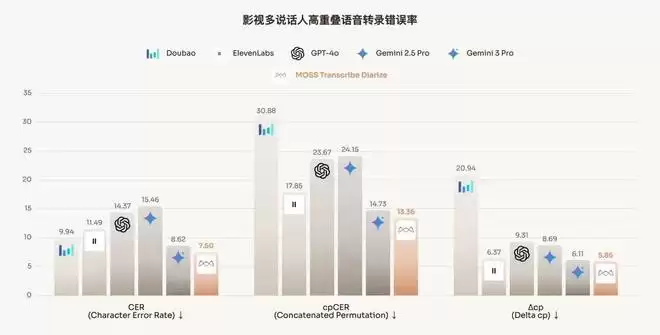
此处 GPT-4o 特指 gpt-4o-transcribe-diarize
再更具体一点,该模型实现了:
最低的 CER(字错误率)与 cpCER(最优排列字错误率):在多说话人混合与重叠场景下取得业内领先的转录准确率。最佳的 Δcp 指标(说话人分离性能 ):相比于其它因为长音频切片而导致的说话人识别不一致的模型,MOSS-Transcribe-Diarize 保持了最好的说话人标签准确性和一致性。超长音频处理:在面对超长音频时,当前顶尖商业模型(如 GPT-4o Transcribe Diarize、Gemini 3 Pro)受限于输入长度或输出格式的稳定性,而 MOSS-Transcribe-Diarize 能够稳定输出完整的带有说话人以及时间戳的语音转录结果。
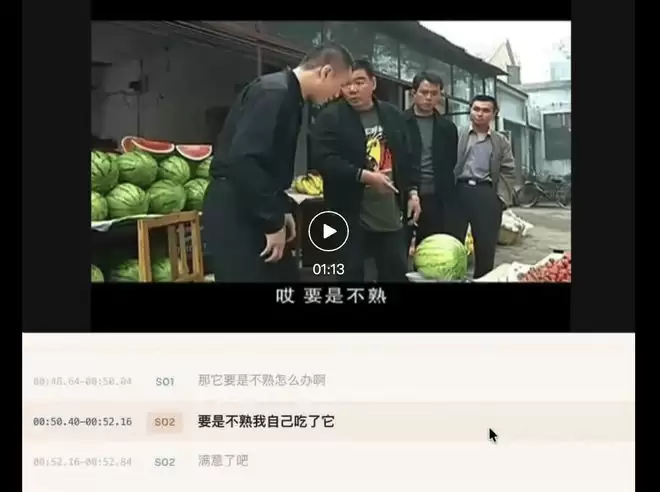
实战效果惊艳,经典名场面「华强买瓜」:
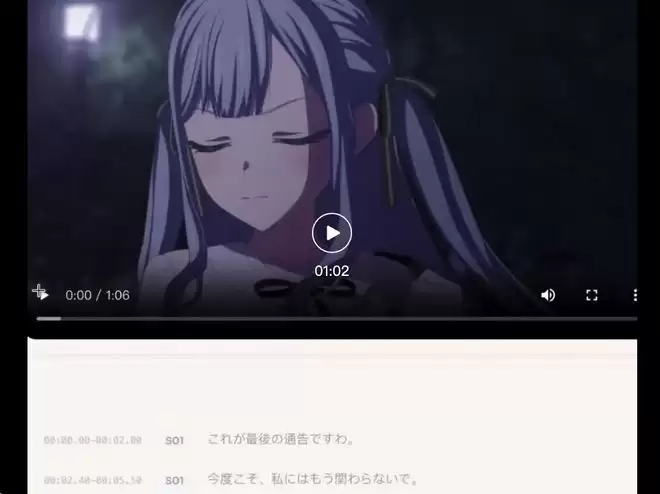
Mygo 的飞鸟山公园:
视频链接:https://mp.weixin.qq.com/s/LoP4twE1X5UFSY3G7g42mQ
看起来 AI 模型可以把说话人和每个人所讲的内容识别地清清楚楚,不论是嘈杂的环境音,人物的方言、俚语,还是因为情感波动表现出的喊叫、哭泣等都不会影响 AI 的判断。
首个统一多模态模型,挑战 AI 语音最难题
MOSS-Transcribe-Diarize 的特点不仅在于语音能力,它作为统一的端到端多模态语音转录模型,能够像人类一样,在「听」的过程中同时完成「听懂内容」、「识别是谁说的」以及「记录说话时间」这三件事。
它主要解决的是语音处理中一个经典且极具挑战的问题:SATS,即「带说话人归属和时间戳的转录」。 想象一下,在参加环境嘈杂、一堆人在场的会议时,大家你一言我一语,乱哄哄一片。这种面向多说话人的转录既要求内容准确,也要标明「何人何时发言」。
但是,传统的模块化组件拼接方案(如自动语音识别 + 说话人日志)引入 LLM 的半级联方案(使用自动语音识别和说话人日志生成候选内容,然后利用 LLM 修正错误)以及近期将识别与归属统一在多模态框架下的尝试(如 Sortformer、SpeakerLM、JEDIS-LLM 等)都不同程度地存在着缺陷,比如级联方案对于说话人重叠的音频表现不鲁棒,其他方案对长时间多说话人对话的转录效果不佳,亟需更优的解决方案。
邱锡鹏团队发布的 MOSS-Transcribe-Diarize 一扫现有 SATS 方案的不足,一举解决了三大核心瓶颈,即长上下文窗口受限、长时记忆脆弱和缺乏原生时间戳。相关技术报告已在几天前发布,同时最新也开放了API 接口,目前为限时免费期,感兴趣的同学可自行体验:
技术报告:https://arxiv.org/pdf/2601.01554模型主页:https://mosi.cn/models/moss-transcribe-diarizeAPI 接入:https://studio.mosi.cn/docs/moss-transcribe-diarize
其中展示了新模型的大量技术特点:其作为一个统一的多模态大语言模型,可以通过端到端的方式同时执行语音识别(ASR)、说话人归属和时间戳预测,消除可能产生的误差传播。
为了达成这些效果,MOSS-Transcribe-Diarize 在模型架构、训练数据组成上形成了一套自己的解法。
在架构设计上,它采用了统一的音频 - 文本多模态架构
设计者将多说话人的声学表示投影到预训练文本 LLM 的特征空间中,使得该模型在单一的端到端框架内能够联合建模词汇内容、说话人归属和时间戳预测。
模型在一个推理过程中直接输出带有 [S01]、[S02] 标签和精确时间戳的文本。这种机制利用了语义信息来辅助说话人识别(例如,通过说话内容的连贯性来判断是否换人了),极大地提高了识别准确率。
在训练数据的组成上,采用「虚实结合」的策略
MOSS-Transcribe-Diarize 使用大量真实世界的对话音频以及通过概率模拟器生成的合成数据进行训练,增强了对重叠语音、轮替和声学变化等性能指标的鲁棒性。该模型训练使用的真实数据包含了从公共语料库中采样的大量说话人片段,并覆盖了现实中不同类型的多说话人场景。
得益于架构与数据层面的一系列巧思,MOSS-Transcribe-Diarize 才能够一举攻克行业长期以来面临的长对话和多说话人转录难题。
长短音频、切话叠音,多场景表现最优
在与国内外顶级模型的较量中,MOSS-Transcribe-Diarize 在多个基准测试中拿下 SOTA 成绩。它究竟强在哪些方面呢?我们接下来进行了一番深入探究。
1)在包含近 40 分钟真实世界会议录音的 AISHELL-4 数据集上,MOSS-Transcribe-Diarize 在 CER 和 cpCER 两项指标上大幅优于所有基线模型,并表现出了更低的 Δcp 值。这验证了相较于纯粹的 ASR 错误,由说话人归属错误引入的额外性能衰退要少得多,并由此证明了长上下文、端到端建模在长对话中维持说话人一致性方面的有效性。
相比之下,GPT-4o 和 Gemini 3 Pro 均无法可靠地处理 AISHELL-4 等长音频输入,前者受限于音频输入长度,无法完成完整录音转录;后者无法生成符合既定说话人归属格式的有效输出。
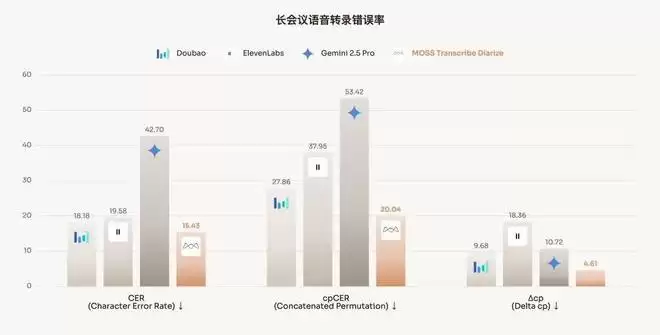
2)在Podcast 数据集(多说话人播客访谈场景)上,MOSS-Transcribe-Diarize 再次取得所有参评模型中最低的 CER 和 cpCER。尽管其他基线模型也达到很高的 ASR 准确率,但在 Δcp 值这点上落败了。这表明,在频繁的话轮转换和长跨度的说话人重现场景下,MOSS-Transcribe-Diarize 能够让说话人归属更加准确。
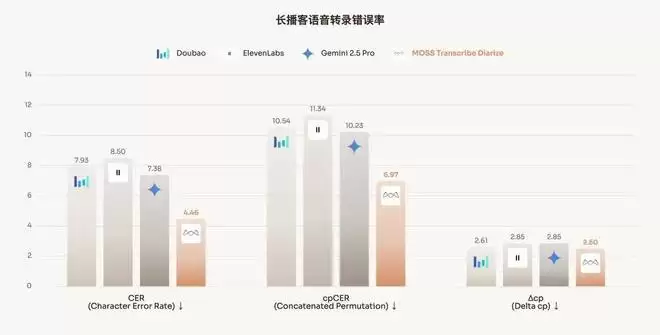
3)在Movies 数据集(复杂影视剧场景)上,强调短促话语、快速说话人交替以及频繁的语音重叠场景,MOSS-Transcribe-Diarize 面对这种短语音转录任务依然优于所有基线模型。它还在 CER 和 cpCER 两项指标之间保持了相对较小的差距,这意味着不仅能听清说了什么,还能非常精准地判断出是谁说的。
目标:情境智能
MOSS 系列大模型的背后,是国内 AI 领域领军人物,复旦大学教授邱锡鹏带领的团队。在中国 AI 版图中,他们显得极具特色。该团队的 MOSS 模型是国内第一个对标 ChatGPT 并开源的对话式大语言模型,并提出了最早的具有内生语音能力的大模型 SpeechGPT 和原生端到端全模态大模型 AnyGPT。团队组建的模思智能(MOSI AI)则由上海创智学院与复旦大学自主孵化,是一家专注面向情境智能的多模态大模型公司。
他们保持了一条清晰且具有战略眼光的技术路径:让大模型理解复杂的真实世界情境,并以情境多模态实现通用人工智能。在这条路线上,他们一直在不断探索,发布了一系列多模态领域的前沿技术成果:
去年 7 月,模思开源了革命性的对话语音合成模型MOSS-TTSD,能够根据完整的多人对话文本,直接生成高质量对话语音。去年 11 月,MOSS-Speech的发布展现了语音 AI 技术的突破,实现了 SOTA 性能。这是一个无文本引导的真端到端语音大模型,可以在保持模型高智商程度的前提下,解决人机低时延交互的挑战。最近发布的MOSS-Transcribe-Diarize,则攻克了复杂日常多人对话场景的语音识别,对于多模态 AI 的实际落地具有重要意义。
这一系列技术成果可覆盖实时对话交互、复杂场景音频生成、高鲁棒性语音理解、多模态交互等核心能力场景,在流畅度、响应速度、理解能力和可控性方面实现了行业领先表现。
面向未来,模思将持续深耕让 AI「理解用户所处的全局情境」的多模态智能,通过规模化物理世界的复杂真实情境,实现真正自然、连贯、可成长、可信赖的智能交互,推动多模态交互与具身智能的产业化落地。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

腾讯元宝助力健身工作室会员营销方案与续卡话术撰写指南
腾讯元宝可辅助制定健身工作室会员营销方案与续卡话术,但需人工提供精准业务参数并明确核心诉求。通过多轮追问可细化话术颗粒度,嵌入具体数据与场景化表达。生成内容必须人工校验合规性,确保符合平台规范与行业要求,避免禁用词汇与诱导承诺。

豆包AI如何帮你快速审查合同关键条款
当豆包AI提取合同关键条款不准确时,通常因文本格式混乱、信息未锚定或指令模糊所致。建议依次尝试:启用结构化摘要自动解析条款;粘贴文本时用关键词指令引导聚焦;运用COSTAR框架明确提问背景与要求;通过分段追问交互式澄清模糊表述,从而精准定位核心信息。

Trae代码重构指南:一键优化代码结构与最佳实践
Trae提供AI驱动的代码重构功能,支持五种方法应对不同场景。局部编辑模式可精准优化选中代码;Chat模式能跨文件协同优化;Builder模式适用于模块或架构升级;Qwen3-Coder-Plus模型专项提升可测试性;系统还能智能识别代码坏味道并推荐重构方案。用户通过快捷键和自然语言指令即可操作,预览确认后应用变更。

ClawBot如何快速调整话术上线季节性促销活动
节假日期间ClawBot话术切换慢,通常因专属提示词模板缺失、活动参数未注入或策略未绑定活动ID所致。可通过四步解决:配置节日专属模板并热生效;绑定活动ID与话术策略;注入实时促销参数;最后进行灰度测试与数据优化,确保话术准确高效。

豆包大模型推理成本优化方法与降本策略
豆包大模型部署需优化配置:批量处理应确保batch_size≥4,采用预填充与解码分离模式。移动端需手动指定量化位数,避免长上下文在轻量版运行。迁移模型须用专用工具重训路由参数,专家数量不宜过多。量化应精细化,仅针对部分计算密集模块,并禁用框架自动转换,以平衡效率与精度。








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
