




Meta Llama 4 即将发布:1300位作者报告揭示其潜力

编辑 | Panda
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
路透社消息,Meta最新组建的AI团队本月已在内部交付了首批关键模型。据透露,该信息来自Meta公司首席技术官Andrew Bosworth,他表示团队开发的AI模型“表现非常出色”。
早在去年12月就有报道称,Meta公司正在研发一款代号为“Avocado”的文本AI模型,计划于第一季度发布;同时还在开发另一款代号为“Mango”的图像与视频AI模型。Bosworth并未具体透露哪几款模型已交付内部使用。
值得注意的是,就在这篇报道发布的前几天,一份名为《Llama 4家族:架构、训练、评估与部署说明》的技术报告在arXiv平台悄然上线。报告全面回顾了Meta Llama 4系列模型所宣称的数据与技术成就。

报告标题:The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
需要说明的是,上传这份报告的作者是Meta公司一位机器学习工程师Arthur Hinsvark,但这份报告并未明确标识来自Meta官方。
尽管如此,这份报告还是将Llama 4项目的所有参与者都加入了作者名单——超过1300人,足足占了5页篇幅!因此,我们可以大体上认为这份报告就是来自Llama 4团队,尽管其中不少人现在已经从Meta离职,比如前Meta FAIR团队研究总监田渊栋。
值得注意的是,这份报告的引言有一段明确说明:“本文档是对公开材料的独立调查。报告中的基准数值归因于模型卡,除非另有说明;应将它们视为开发者报告的结果,并对评估工具、提示工程和后处理持通常的保留态度。”
也就是说,这份报告整体回顾了Meta公布的各种Llama 4相关材料,尤其是其宣称的一些数据。但没有明确解释其在实际应用中表现明显不及预期的原因。想要了解相关背景的读者可参阅:
Meta Llama 4被疑“作弊”:在竞技场刷高分,但实战中频频翻车;Llama 4在测试集上训练?内部员工、最新下场澄清,LeCun转发
不过,该报告也并非完全没有提到相关原因。仔细阅读的话,我们能在行文中看到一些端倪。其中主要的讨论点集中在部署限制和榜单争议上:
架构能力与实际部署的差距(尤其是上下文长度):论文反复强调了一个“经常出现的操作主题”:模型的架构支持能力与实际服务中提供的能力之间存在差距。虽然Scout在架构上设计为支持10M上下文长度,但在实际部署中(如Cloudflare或AWS),由于显存和KV缓存的硬件成本限制,服务商往往将可用上下文限制在128K或1M。这意味着用户在实际使用托管服务时,可能无法体验到模型宣称的全部长上下文能力。
榜单成绩与发布版本的差异:论文提到了关于LMArena排行榜的争议。Meta在榜单上提交的Maverick“实验性聊天”变体与公开发布的版本不完全相同。这导致了外界批评其“操纵基准测试”。这也解释了为什么用户使用公开发布版本时的体验,可能与某些榜单上的高分表现不一致。
营销话术与技术指标的区别:论文明确指出,发布公告中的某些声称(例如Scout是“同类最佳”或强调性价比)属于“面向营销的主张”,应当与严谨的模型卡基准测试结果分开解读。
这些细节似乎暗示了这份报告是Meta Llama团队对于Llama 4系列模型备受社区广泛批评(数据亮眼但能力很差)的最终回应。
对于这些说明,不知道你怎么看?
具体到内容上,这篇技术报告的内容仅有15页,其中1300多位作者的名单就足足占了5页,再去掉一页参考文献,实际内容仅有9页。其中,Meta Llama团队总结了:
已发布的模型变体(Scout和Maverick)以及更广泛的系列模型背景,包括预览版的Behemoth教师模型;
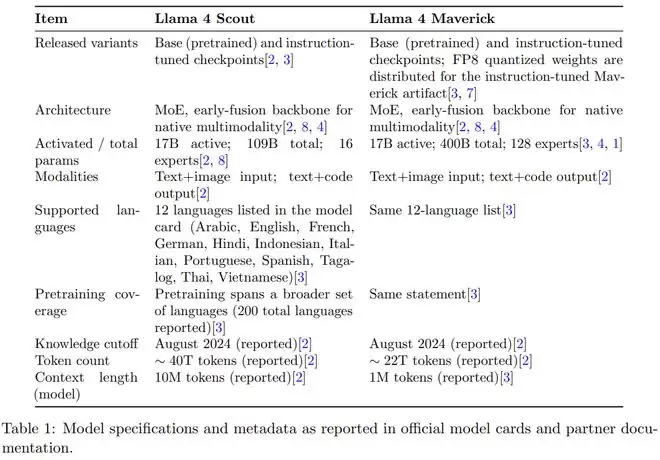
超越高级MoE描述的架构特征,涵盖路由/共享专家结构、早期融合多模态,以及针对Scout报告的长上下文设计元素(iROPE和长度泛化策略);训练披露,跨越预训练、用于长上下文扩展的中期训练,以及发布材料中描述的后训练方法(轻量级SFT、在线RL和轻量级DPO);开发者报告的基础和指令微调检查点的基准测试结果;在主要服务环境中观察到的实际部署限制,包括特定于提供商的上文限制和量化打包。
此外,这份报告还总结了“与再分发和衍生命名相关的许可义务,并回顾了公开描述的安全措施和评估实践。其目的是为需要关于Llama 4精确、有来源依据的事实的研究人员和从业者提供一份紧凑的技术参考。”
更多详情请参阅原报告。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

1.4 万亿词元!阿里 Qwen3.6-Plus 刷新全球最大 AI 聚合平台 OpenRouter 日调用量纪录
1 4 万亿词元!阿里 Qwen3 6-Plus 刷新全球最大 AI 聚合平台 OpenRouter 日调用量纪录 这事儿挺震撼的。就在4月4日,全球最大的AI模型聚合平台OpenRouter在其官方账号上公布了一个爆炸性数字:阿里刚刚发布的千问新模型Qwen3 6-Plus,上线仅仅一天,日调用量

实战指南:基于快马平台深度开发,构建企业级workbuddy团队项目管理看板
深度开发指南:利用快马平台高效构建企业级WorkBuddy团队项目管理看板 近期在开发团队协作工具WorkBuddy的项目管理模块时,传统开发模式的周期漫长令人困扰。转而采用快马平台(即InsCode)后,开发效率得到显著提升。本文将详细分享如何基于快马平台,快速搭建一个功能完善、体验流畅的企业级项

消息称 Meta 低调组建独立硬件团队,打造以多种形态陪伴人类的智能体
消息称 Meta 低调成立独立硬件部门,致力于研发多形态人类陪伴型智能体设备 4月4日凌晨,《商业内幕》发布独家报道引发行业关注。多位知情人士透露,Meta公司正悄然为其“超级智能”业务线组建一支独立的硬件研发团队,并任命资深硬件工程师负责整体管理。此举被视为Meta在人工智能设备战略布局上的关键一

AI 的记忆不是硬盘——从 40 个真实 Bug 说起
这是 AI 认知架构实战笔记 系列的第 2 篇 上一篇我们聊了「给 AI 写灵魂文件」这件事,这一篇,我们来看看,当这份灵魂文件真正运转起来之后,现实究竟会给我们带来多少“惊喜”——或者更准确地说,是漏洞。项目名为 WorkBuddy-Configure,已部署在 gitee 和 gitcode 上
OpenClaw给每个Agent单独指定workspace
OpenClaw中为每个Agent配置独立工作区的最佳实践 在大模型智能体协作平台上,实现多个Agent之间的文件隔离是确保项目管理井然有序的关键需求。如果您正在使用OpenClaw平台,为不同角色的智能体分配专属工作空间可以有效避免文件冲突、权限混乱等问题。本指南将详细介绍在OpenClaw中为每








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















