




斯坦福与英伟达联合发布AI推理新范式,刷新多领域SOTA


免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:艾伦
【新智元导读】斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。
如果把现在的 AI 模型比作一个学霸,它们的工作方式通常是这样的:在学校(预训练阶段)读万卷书,把知识固化在脑子里(参数冻结)。
等到考试(推理阶段)时,它们靠的是「回忆」和「逻辑推演」来答题。
即便像 OpenAI 的 o1 这种「会思考」的模型,也只是在考场上多打了打草稿(CoT思维链),它的大脑回路(权重)依然是锁死的。
但就在本周,一篇名为《Learning to Discover at Test Time》的论文横空出世,来自斯坦福大学和英伟达的研究团队提出了一种不仅「打草稿」,而且敢在考场上「现场长脑子」的新范式——TTT-Discover(Test-Time Training,测试时训练)。

这是对「智能」定义的再一次挑战。
核心颠覆
这项研究的核心逻辑非常反直觉:它不追求「平均分」,它只想要那一次「满分」。
在传统的强化学习中,我们希望训练出一个「全能选手」,不仅能做对这道题,以后遇到类似的题也能做对。
但 TTT-Discover 说:不,科学发现(Discovery)不需要「通用」。
比如我们要寻找一种能治愈癌症的新分子,或者要找出一个数学猜想的反例。
只要我们找到了这一个答案,哪怕模型在这个过程中严重「偏科」,甚至为了这道题把自己练废了(过拟合),把其他所有题都做错了,又有什么关系呢?
只要那个答案是对的,人类就赢了。
基于这个理念,TTT-Discover 采用了一种极其激进的策略:
现场进化:在推理阶段,针对当前的特定问题,利用强化学习直接修改模型的参数。
赌徒心态:它修改了损失函数,不再追求「稳健」,而是鼓励模型去探索那些极端的、风险极高但回报可能巨大的区域。
用完即弃:这个针对特定问题进化出来的「特种兵」模型,解完题就可以丢掉了。

战绩:它真的比人类聪明吗?
「不看广告看疗效」。
这篇论文最硬核的地方,在于它挑选的对手——全是硬骨头。

1. 数学界的「毫厘之争」
在著名的Erdős 最小重叠问题(一个困扰数学家数十年的数论难题)上,人类和此前最强 AI(AlphaEvolve)的竞争已经卷到了小数点后几位。TTT-Discover 进场后,直接把上界从 0.380924 压低到了0.380876。
别小看这小数点后四位的变化,在理论数学的无人区,每推进一步都是在重写历史。
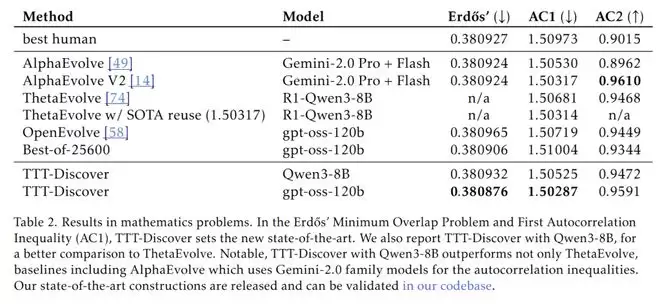
它构造出了一个极其复杂的、拥有 600 个分段的非对称函数,而之前的人类最佳构造只有 51 段。
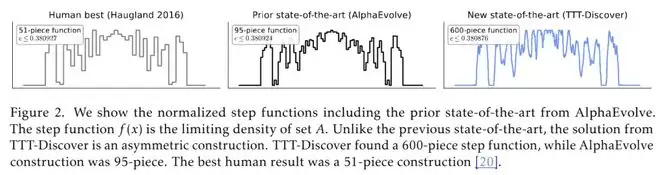
这就像是人类还在用积木搭房子,AI 已经开始用 3D 打印构建复杂的非对称建筑了。
2. 碾压人类顶级程序员
在 GPU 内核优化(TriMul)比赛中,任务是写出运行速度最快的底层代码。
这是极度考验工程师对硬件理解能力的领域。
人类第一名的代码在 H100 显卡上运行耗时:1371 微秒。
TTT-Discover 写出的代码耗时:1161 微秒。
在 A100 显卡上更夸张,它比人类第一名快了整整50%。
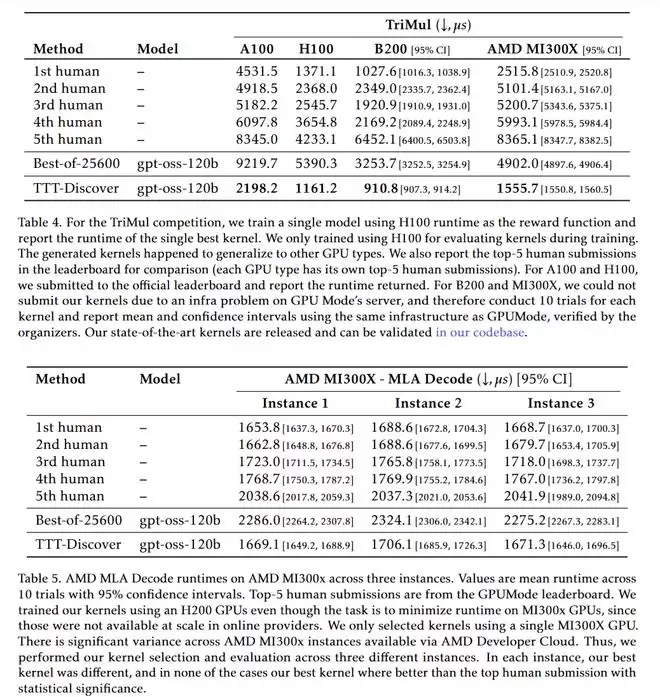
这意味着,在未来,你玩的游戏、跑的大模型,仅仅因为底层代码被这种 AI 重写了一遍,性能就能凭空提升一倍。
它发现了一些人类工程师完全没想到的「骚操作」,比如极其激进的算子融合和精度压缩。
3. 算法竞赛的降维打击
在著名的 AtCoder 启发式竞赛(ahc039, ahc058)中,它不仅击败了之前最强的 AI 智能体,还超越了人类金牌选手的历史最佳成绩。
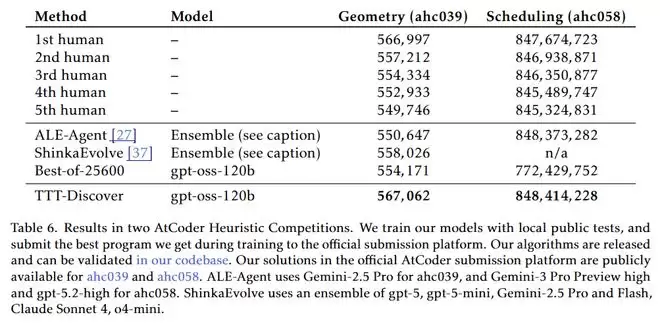
如果当时它参赛,它就是当之无愧的第一名。
冷静一下,它不是万能神药
虽然战绩辉煌,但作为一篇严谨的科普,必须指出它的「阿喀琉斯之踵」。
第一,它是真的「贵」。
传统的 AI 回答一个问题可能只需要几分钱的算力。
而 TTT-Discover 为了解决一个问题,需要在测试时进行几千次甚至上万次的采样和训练。
论文坦承,解决单道题的成本约为500 美元(约合人民币 3500 元)。
用来做小学奥数题?疯了。
用来设计下一代光刻机指令?便宜得像不要钱。
第二,它是个「偏科生」。
你不能指望用这个进化后的模型去和你聊天。
因为它在解决那道数学题时,可能已经把「如何说你好」这部分的脑细胞都改写成了「如何计算微积分」。
它是为了单点突破而生的一次性工具。
第三,它需要「打分器」。
这是最关键的局限。
它目前只能解决那些「好坏显而易见」的问题(有连续奖励信号),比如代码运行速度(越快越好)、数学边界(越小越好)。
对于「写一首感人的诗」或者「证明黎曼猜想」(通常只有对 / 错两种状态)这类问题,它目前还无能为力。
作者简介

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

东风汽车全球设计中心启用:“东方风韵”引领中国车企文化出海
在武汉举办的东风汽车全球设计创新日上,“中国叙事・东风设计”成为核心主题。这场盛会不仅见证了东风汽车全球设计中心的正式启用,更以“东方风韵”设计哲学的发布,为中国汽车的美学发展提供了全新答案。随着中

苹果AI国行版上线:国内为何调用百度文心模型?官方回应
Apple Intelligence 北京时间3月31日,据科技 9to5mac报道,苹果AI系统Apple Intelligence周二短暂在中国上线,但最终证明只是苹果的一个误操作,目前已下线。

美国民众对AI信任度调查:超四分之三人持怀疑态度
IT之家 3 月 31 日消息,据 TechCrunch 报道,如今越来越多美国人开始借助人工智能完成各类事务,包括资料调研、文案撰写、学业或工作项目以及数据分析,但他们对此其实并不安心。昆尼皮亚克

DeepMind之父警示:我开发的AI或威胁人类,却已难以阻止
新智元报道编辑:KingHZ【新智元导读】从拦截彼得·蒂尔、警告马斯克,到如今公开说「必须有适应能力」,哈萨比斯史诗级转身:AI安全窗口正在永久关闭,他不再幻想制度,而是赌上全部身家——赌影响力,赌

DeepSeek挑战Transformer记忆?查表法重塑模型架构新思路
新智元报道编辑:LRST【新智元导读】ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用tok








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
























