




AI智能体四象限法则:从自动化迈向智能化的关键路径

当任务流程与执行情境都不够清晰时,智能体不仅需要理解当前环境,还得主动规划步骤、探索可行路径。跨部门信息整合、创新方案构思以及多智能体协作等复杂任务,都属于这一范畴。这类挑战恰恰最贴近通用人工智能所需面对的真实场景。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈

前言
大家好,我是测试员兼观察者。
2025年被许多人称为“智能体元年”。
然而转眼这一年已临近尾声,我们不禁要问——
究竟什么才是真正的智能体?
又有多少智能体已经实际落地,而不仅仅是停留在概念与演示当中?
智能体的本质
智能体的核心,其实由两个关键变量决定:
其一是控制任务走向的流程,其二是影响内容生成的情境。
从“流程是否固定”与“输入是否可预知”两个维度出发,我们能更清晰地界定智能体的能力边界与智能水平。
智能体四象限法则
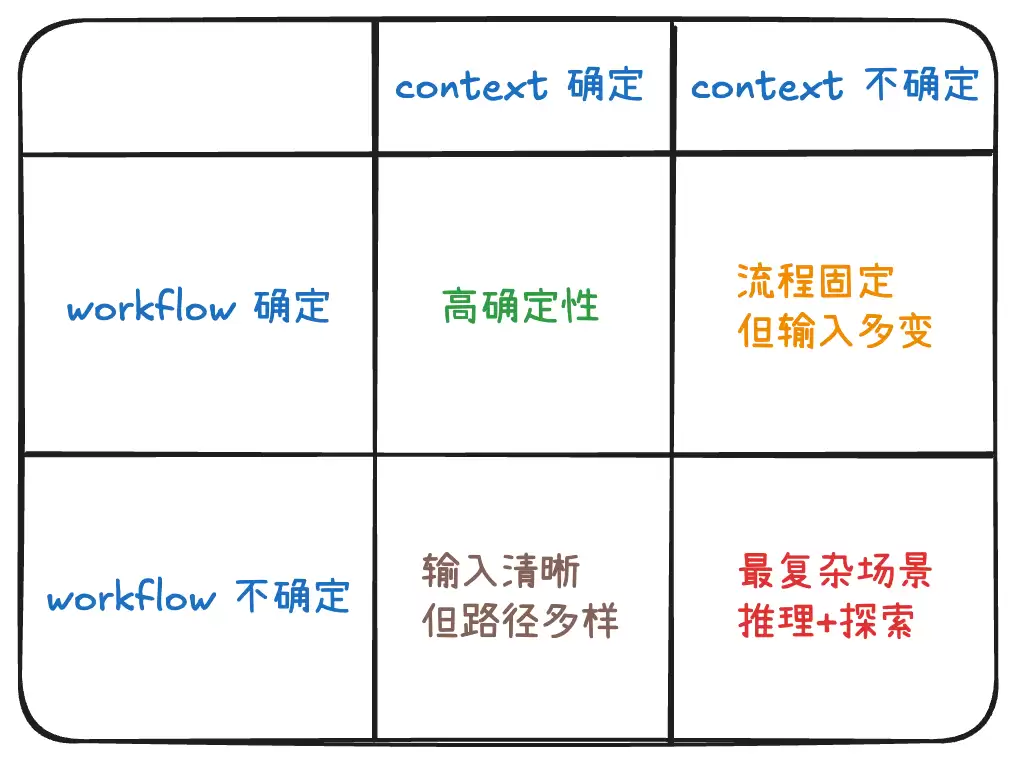
1. 高确定性场景
当流程与情境都具有高度确定性时,这类任务就容易被自动化。这类似于传统的流程自动化机器人技术。
在此象限中,我们回到熟悉的“流程清晰、输入可控”世界。例如发票处理、表单填报……这些场景流程统一、材料格式固定、变量极少。只要规范到位、流程设计严谨,系统运行就能保持稳定。
但,也正因为“确定性太强”而错失了“智能化”的机会,自主发挥空间相对有限。它需要前期就由技术人员将工作完善,人工智能主要起到简单的工具调用功能。
2. 流程固定但输入多变
当流程确定,但情境不够清晰时,流程虽仍标准化、可控,可输入或上下文的变化却很大。这就需要智能体在语义和理解上进行补充,例如智能客服、合同解析等应用,往往需要借助外部检索、知识图谱等工具来弥补信息的缺口,让推理结果更符合预期。
在这个阶段,智能化的关键并非流程更复杂,而是能否让智能体识别海量变化语义、同时保持响应质量。精准引导智能体的语义理解与补充确实很难,大规模模型输出的不确定性仍然是需要解决的问题。
这也正是“智能工作流”的进化,传统自动化流程面对突变、非结构化场景时常力不从心,而智能工作流则强调“工具使用、规划、反思”三者的循环推进。
3. 输入清晰但路径多样
当情境确定,但流程不够清晰时,输入目标明确但实现方法多样,这就需要智能体具备自主规划能力。例如市场分析报告生成、个性化推荐系统,用户输入“我想了解2025年中国消费市场趋势”,主题很明确,但智能体需要自己查资料、整理结构、定位报告走向、生成最终输出。流程不是死的。
在“智能工作流”中,规划是核心能力之一,智能体需要能够“分解任务 -> 计划执行 -> 反思优化”形成闭环。
大多数端到端强化学习智能体都擅长处理此类任务,因为它们在训练阶段就习得了大量的路径规划和解题思路。这种场景考验的是智能体的规划能力和决策智能。
4. 双重不确定:通用智能体
当流程与情境都不确定时,意味着智能体既要理解语境、还要规划流程,更要探索路径。跨部门信息收集、创新方案设计、多智能体协同等任务都属于这一类别,这也是最接近通用人工智能真实挑战的场景。
这类智能体更偏向于通用型智能体,执行效果很大程度上取决于为其配备的工具丰富度。编程能力最大化的开放性变得尤为重要,比如让智能体学会到代码库搜索、克隆并修改代码来解决问题,真正做到像人一样工作。
那么,回到开头的问题:什么是智能体?
它是一个能在目标导向下,基于上下文自主决策并行动的系统。
在这个系统中,流程让它有序地前进,情境让它懂得何时、为何、如何行动。
智能体 = 流程 × 情境 × 自主性
既具备流程执行能力,又拥有内容理解的智慧,更重要的是,它能根据环境反馈不断优化自身。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

新加坡国立大学破解AI看图说话难题让机器描述更准确
人工智能的“幻觉”问题,特别是大模型在图像描述任务中凭空捏造内容的现象,一直是制约其可靠应用的关键挑战。2026年2月,一项由新加坡国立大学与北京大学深圳研究生院联合发布的突破性研究,为这一难题提供了全新的理解与一套高效、简洁的解决方案。这项研究(论文预印本编号:arXiv:2602 22144v1

斯坦福大学JavisDiT++实现AI有声有色视频生成
这项由浙江大学、新加坡国立大学、多伦多大学等全球顶尖科研机构联合完成的研究成果,已正式发表于2026年国际学习表征会议(ICLR 2026),论文预印本编号为arXiv:2602 19163v1。对于希望深入探究技术细节的读者,可通过此编号查阅完整的学术论文。 在浏览短视频时,你可能已经察觉到一种普

北大提出AI推理双车道方案解决大模型对话卡顿难题
这项由北京大学计算机学院主导,联合清华大学及DeepSeek-AI共同完成的前沿研究,其成果已正式发布于2026年2月的arXiv预印本平台,论文编号为arXiv:2602 21548v1。关注大语言模型推理优化的研究者与开发者,可通过此编号查阅论文全文与技术细节。 在与大语言模型进行深度、多轮对话

清华大学AI突破:赋予虚拟世界持久记忆,解决视频生成失忆难题
想象一下,你正在体验一款开放世界游戏。当你站在高塔之巅,远方的山脉清晰可见。随后你转身离开,去探索地图的其他角落。许久之后,当你再次回到这座塔顶,那座山依然以完全相同的姿态矗立在原地。这种空间持久且一致的认知,是人类理解世界的基础。 然而,若让当前的主流AI来动态生成这样的游戏场景,结果会大相径庭。

大模型压缩技术COMPOT让AI运行更高效
随着人工智能模型参数规模不断突破千亿级别,其庞大的存储需求和计算开销已成为实际部署的主要瓶颈。针对这一挑战,MWS AI基础研究中心与ITMO大学联合提出了一种名为COMPOT的创新模型压缩技术。这项发表于2026年2月预印本平台(arXiv:2602 15200v1)的研究,为大语言模型高效“瘦身








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
