




CMU提出最大似然强化学习:超越常规优化路径


机器之心编辑部
在大模型时代,从代码生成到数学推理,再到自主规划的 Agent 系统,强化学习几乎成了「最后一公里」的标准配置。
直觉上,开发者真正想要的其实很简单:让模型更有可能生成「正确轨迹」。从概率角度看,这等价于最大化正确输出的概率,也就是经典的最大似然(Maximum Likelihood)目标。
然而,一项来自 CMU、清华大学、浙江大学等研究机构的最新工作指出了一个颇具颠覆性的事实:
现实中广泛使用的强化学习,并没有真正在做最大似然优化。严格的理论分析显示,强化学习只是在优化最大似然目标的一阶近似—— 距离我们以为的最优训练目标,其实还差得很远。
正是基于这一观察,研究团队对强化学习的目标函数进行了重新审视,提出了最大似然强化学习(Maximum Likelihood Reinforcement Learning):将基于正确性的强化学习重新刻画为一个潜变量生成的最大似然问题,进一步引入一族以计算量为索引的目标函数,使训练目标能够逐步逼近真正的最大似然优化。

论文标题:Maximum Likelihood Reinforcement Learning论文链接:https://arxiv.org/abs/2602.02710项目地址:https://zanette-labs.github.io/MaxRL/Github 地址:https://github.com/tajwarfahim/maxrl
传统强化学习的「卡脖子」问题
在代码生成、数学推理、多步决策这些任务中,我们已经形成了一种几乎默认的共识:只要反馈是二值的、过程是不可微的,就用强化学习。
强化学习这套范式,支撑了从 AlphaGo 到大语言模型推理能力提升的一系列关键进展。
从端到端的角度看,强化学习就是给定一个输入,模型隐式地诱导出一个「成功概率」. 如果不考虑可微性约束,最自然、也最原则性的目标,就是最大似然
但论文研究团队发现:基于期望奖励的强化学习,其实只是在优化最大似然目标的一阶近似。更具体地说,最大似然目标在总体层面可以展开为一系列以 pass@k 事件为基的项,而标准强化学习只优化了其中的一阶项。
简单来说,强化学习并没有真正最大化「模型生成正确答案的概率」,而是在优化一个与真实似然存在系统性偏差的替代目标。
这也解释了一个广泛存在却难以言说的现象:强化学习早期进展迅速,但越到后期,性能提升越困难。
研究团队针对这一新发现,对「基于正确性反馈的强化学习」进行了重新刻画,论文的主要贡献如下:
将基于正确性的强化学习形式化为一个潜变量生成的最大似然问题,并证明标准强化学习仅优化了最大似然目标的一阶近似。提出了一族以计算量为索引的目标函数,通过对 pass@k 事件进行 Maclaurin 展开,在期望回报与精确最大似然之间实现连续插值。推导出一种简单的on-policy 估计器,其期望梯度与该计算量索引的似然近似目标完全一致,这意味着增加采样真正改善了被优化的目标本身。
最大似然:真正改进优化目标
研究团队认为,最大似然估计在有监督学习中表现卓越,为什么不直接在强化学习中实现它?
上一节中的观察启示我们:可以构造一个随计算量变化的目标函数族,逐步引入更高阶项;随着可用计算资源的增加,该目标函数族将逐渐收敛到完整的最大似然目标。
论文通过一系列推导,将最大似然目标在失败事件方面进行麦克劳林展开:
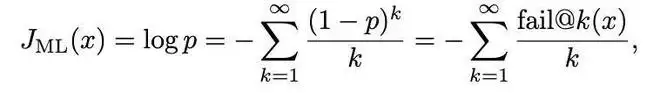
展开式中的最大似然梯度很难用有限样本进行估计。
特别是,估计大 k 值的 pass@k 梯度需要越来越多的样本,尤其是在通过率 p 很小的情况下。这种有限样本的困难正是提出最大似然强化学习(MaxRL)的动机所在。
研究团队将 MaxRL 定义为一类强化学习方法,它们显式地以最大似然为目标,而不是以通过率为目标,同时在有限采样和不可微生成的条件下仍然可实现。下面我们考虑一种实现该目标的原则性方法。
考虑通过将麦克劳林展开式截断为有限阶来近似最大似然目标,然后估计该目标。对于截断级别 T ∈N,我们将固定输入 x 的截断最大似然目标定义为:
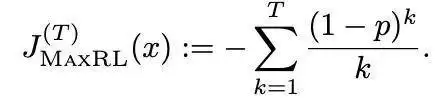
对其求导得到截断的总体梯度:
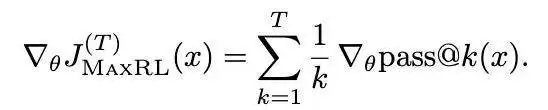
这定义了一族目标函数:T = 1 还原为强化学习,T → ∞ 还原为最大似然,中间的 T 值则在两者之间插值。因此,截断级别 T 直接控制了有助于学习的正确性事件的阶数。随着在 rollout 方面消耗更多的计算量,对更高阶梯度的估计变得可行。
换句话说: MaxRL 提供了一个原则性框架,用于通过增加计算量来换取对最大似然目标更高保真度的近似。
上述公式已经给出了一种可行的无偏估计思路:利用pass@k 梯度估计器,对有限级数中的每一项分别进行近似。在这一策略下,任何对 pass@k 估计器的改进,都会直接转化为对截断最大似然目标的更优梯度估计。
不过,在本篇论文中,研究者采取了一条不同的路径,将带来更为简洁的估计器形式,同时也提供了一个新的理解视角
最大似然目标的梯度可以写成如下的条件期望形式:
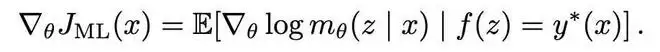
该定理表明,最大似然梯度等价于仅对成功轨迹的梯度进行平均。这一解释为构造具体的梯度估计器提供了直接途径:只需用采样得到的成功轨迹,对上述条件期望进行样本平均即可。
其核心洞见在于:最大似然目标的梯度可以表示为在「成功条件分布」下的期望。
因此,本文采用了一种简单的策略:从非条件化的策略分布进行采样,但只对成功轨迹进行平均,得到了强化学习风格的估计器,其具备随着 rollout 数的增加,对最大似然梯度的近似将不断改善的特性。
换言之,在 MaxRL 框架下,额外的计算资源不仅改善了估计质量,更直接改进了被优化的目标本身。
令人惊讶的效率进步
在实验中,这一改变带来了远超预期的收益。研究团队在多个模型规模和多类任务上,对 MaxRL 进行了系统评估,结果显示:MaxRL 在性能与计算效率的权衡上均稳定地优于现有强化学习方法。
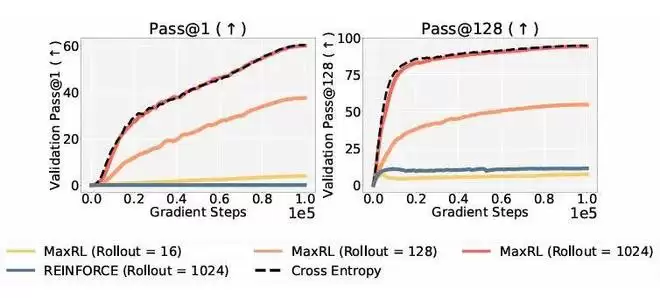
实验结果直观展示了 MaxRL 在训练效率上的优势。在相同训练步数下,MaxRL 性能提升明显更快,并且随着 rollout 数的增加,MaxRL 持续受益。
这种优势并不只体现在训练阶段,相较于使用 GRPO 训练的模型,MaxRL 测试时的 scaling 效率最高可提升20 倍
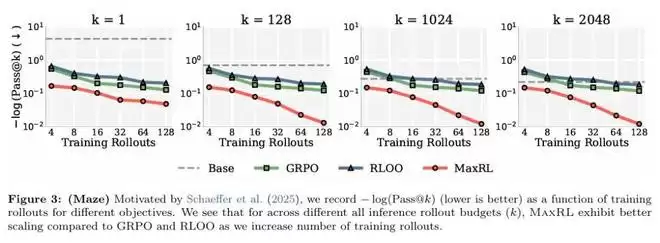
在迷宫任务上,无论测试时的采样预算 k 取何值,随着训练 rollouts 的增加,MaxRL 都能持续降低 −log (Pass@k),而 GRPO 与 RLOO 的改进幅度则明显更早趋于平缓。这一结果直观地展示了 MaxRL 在训练阶段更优的性能–效率权衡。
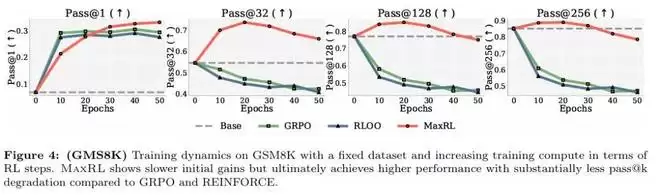
比较在不同 pass@k 设置下各方法随训练中采样计算增加时的优化趋势,可以看到,对于 GRPO 与 RLOO,曲线在早期下降后迅速变平,说明额外采样主要用于降低噪声;而 MaxRL 在不同 k 值下均保持持续下降,推动模型不断逼近一个更接近最大似然的优化目标。
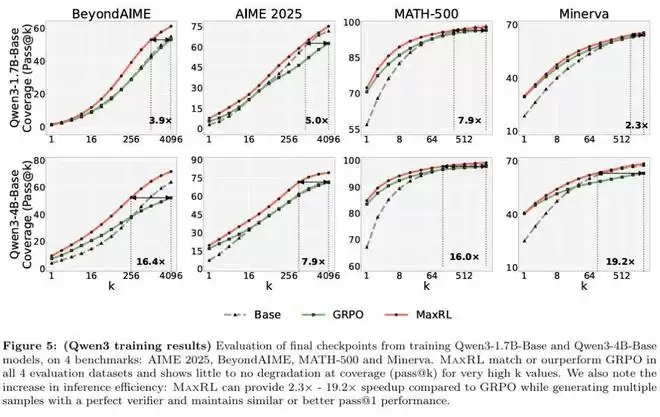
在更大规模设置下,MaxRL 的优势依然保持稳定。这表明,MaxRL 所带来的改进并非依赖于特定规模或超参数设置,当训练规模扩大时,MaxRL 并未出现收益递减过快或优势消失的现象。
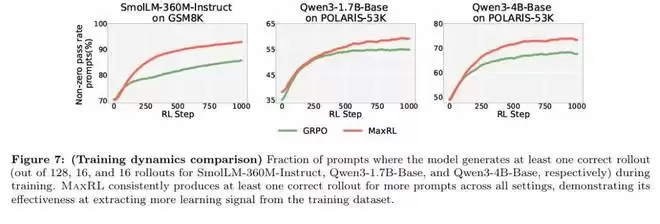
进一步的实验结果表明,MaxRL 的优势并不依赖于过于理想化的实验条件,即使在反馈存在噪声或验证信号并非完全可靠的设置下,MaxRL 仍然能够保持相对稳定的性能优势。
总体来看,MaxRL 为不可微、基于采样的学习问题提供了一种更为深入的解法。它通过一个随计算量自然扩展的目标框架,系统性地逼近真正的似然优化。
当优化目标本身可以随算力演进、逐步逼近最大似然,强化学习究竟会成为通往通用智能的长期答案,还是只是通往下一个训练范式的过渡方案?
更多信息,请参阅原论文。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

微信鸿蒙版8.0.17.38灰度测试:元宝聊天与视频号新功能上线
微信鸿蒙版App发布8 0 17 38尝鲜更新,测试期至6月16日。本次更新在官方“修复已知问题”的说明下,实则带来了多项功能升级,重点围绕视频号体验优化、AI音乐创作探索及社交工具完善。视频号新增资料修改、双击点赞、直播自定义选项;听一听功能灰度上线AI写歌与AI翻唱;同时灰度测试了“与元宝聊天

惠康制冰机快速出冰夏日特惠 多重补贴到手价171元
惠康HZB-16M制冰机在盛夏时节推出特惠活动。该机器主打快速制冰,仅需6-8分钟即可完成一批冰块,并配备一键自清洁功能,方便日常维护。原价259元起的产品,通过叠加政府及平台补贴、专属优惠券和晒单返现等多项优惠后,到手价低至171元。此外,购买还享有“买贵双倍赔”和以旧换新选项,产品提供2年质保,

中国技术标准助力中亚首条全自动无人驾驶轻轨通车
哈萨克斯坦阿斯塔纳轻轨一期项目于5月16日正式通车,这是中亚地区首条全自动无人驾驶轻轨线路。该项目全长约22 4公里,设18站,连接机场与火车站等关键节点,采用中国技术、装备和标准建造。哈萨克斯坦总统托卡耶夫在通车仪式上试乘并用中文向中方致谢。线路配备19列车,最高时速80公里,发车间隔5-6分钟,

90岁石油工程师玩《深海迷航2》 真实经历与深海生存游戏惊人相似
一位90岁高龄、曾为石油工程师的玩家体验了水下生存游戏《深海迷航2:异星水域》。他结合自身勘探经历,认为游戏对资源探索逻辑与未知危险的呈现相当真实考究。这一事件展现了游戏设计对专业领域的借鉴深度,也反映了游戏受众的多元化趋势,以及虚拟体验与真实世界知识体系之间可能产生的有趣共鸣。

AMD锐龙处理器包装芯片不符事件调查:9950X3D2惊现上代产品
一位海外消费者在亚马逊购买全新AMD锐龙99950X3D2处理器,开箱后发现内部芯片实为上一代9950X3D,但外包装防伪贴纸完好无损,引发广泛关注。硬件社区对此提出两种主要推测:一是AMD生产线包装出错;二是遭遇高技术退货诈骗。然而,由于两款芯片差价不大,诈骗动机存疑。目前买家已申请退货,事件原








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
