




苹果联合人大发布VSSFlow模型:无声视频AI生成音效与配音

2月10日消息,科技媒体9to5Mac近日发布文章,透露苹果公司已联合中国人大团队,成功推出了名为VSSFlow的新型AI模型。这项技术突破了传统音频生成的局限,能够在单一框架下,从无声视频中同时合成出逼真的环境音效与清晰的人声语音。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
该模型的核心在于其“化静为动”的能力,可对无声视频数据进行端到端处理。基于统一的架构,系统能同步生成与画面高度契合的环境声场,同时输出精准自然的语音对白。这一成果不仅解决了过往音频模型功能单一的问题,其生成质量更是达到了业界领先水平。
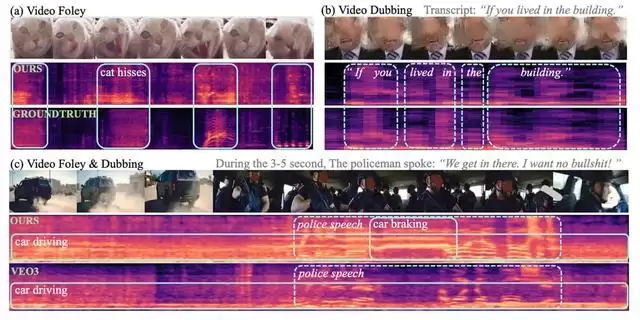
根据博文介绍,在VSSFlow问世之前,业内模型往往存在明显的功能偏向:专攻视频转语音的模型难以输出清晰人声,而基于文本的语音合成模型又无法有效处理复杂的环境噪音。
传统的解决方案通常需要将两项任务分阶段进行训练,这不仅增加了系统复杂度,还常因任务冲突而导致性能下降。VSSFlow则另辟蹊径,采用了10层的架构设计,并引入“流匹配”技术,让模型能够自主学习如何从随机噪声中,精准重构出目标语音信号。
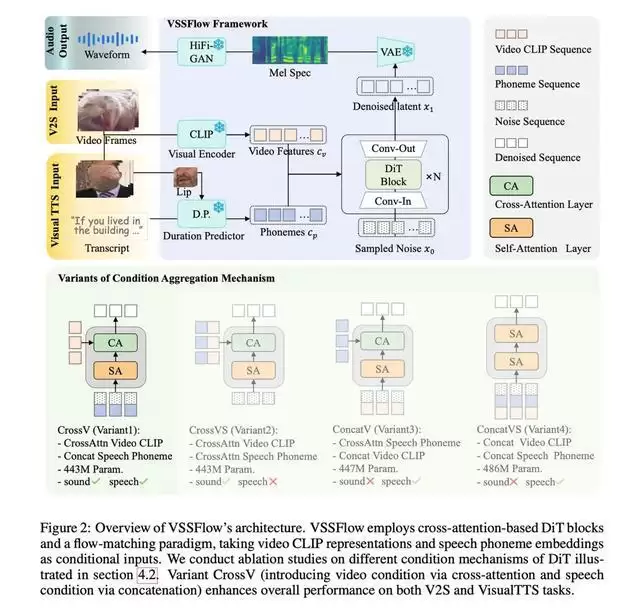
研究团队在训练过程中发现了一个惊喜的现象:联合训练不仅没有引发任务干扰,反而产生了“互助效应”。具体来说,语音数据的训练提升了音效生成的质量,而音效数据的加入也优化了语音的最终表现。
为了实现这一效果,团队向模型输入了混合数据,其中包含带有环境音的视频、配有字幕的讲话视频,以及纯文本转语音数据。通过利用合成样本微调模型,使其学会了如何同时输出背景音与人声。
在实际运行中,VSSFlow以每秒10帧的频率从视频中提取视觉线索,从而塑造出匹配的环境音效,同时依据文本脚本精准引导语音生成。
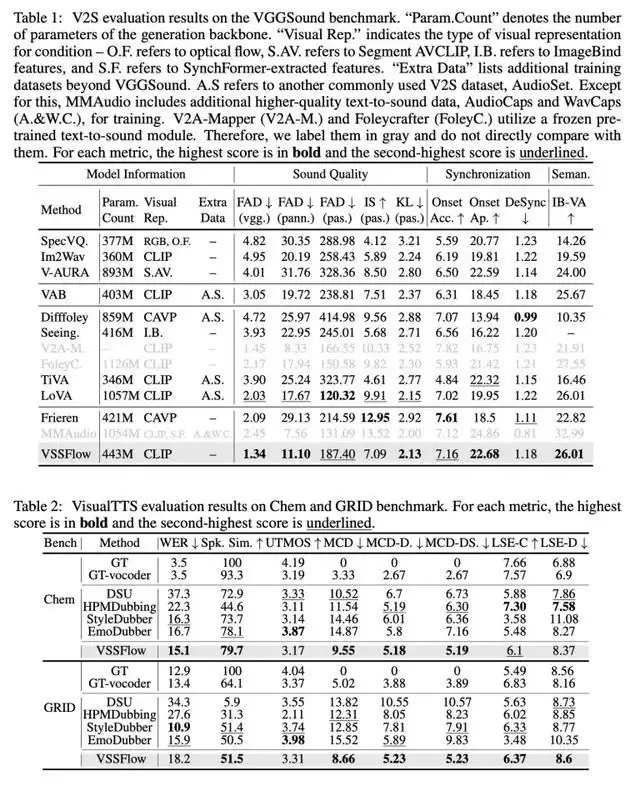
测试数据显示,该模型在多项关键指标上均优于那些专为单一任务设计的竞品模型。目前,研究团队已在GitHub上开源了VSSFlow的相关代码,并正在推进模型权重公开以及在线推理演示的开发工作。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

云知声发布山海知医慧保大模型
云知声发布医疗健康保险大模型“山海知医慧保”,基于自研通用底座并融合临床数据,提供医保合规与商保理赔解决方案。该模型覆盖政策问答、智能审核等全流程,关键指标显著提升,现已通过标准化接口上线,助力保险领域AI规模化应用。

智汇云舟数字孪生技术如何赋能产教融合实训革新
数字孪生技术通过三维重建、空间智能与视频孪生,高效构建虚拟场景,实现个性化教学与沉浸式虚实融合体验。它解决了传统实训设备更新慢、场景脱节等问题,让学生在安全可重复的环境中掌握复杂技能,并以自主可控的核心技术为实训室建设提供安全灵活的基础。

特拉维夫大学新方法揭秘AI分区管理思维提升语言模型理解力
你有没有想过,当你跟ChatGPT或其他AI助手聊天时,它们的“大脑”里究竟是怎么组织知识的?就像我们人类的大脑会把不同类型的记忆和知识分门别类存放一样,AI的“思维”也需要某种组织方式。最近,一项开创性的研究为我们理解AI语言模型的内部工作机制,提供了一个全新的视角。 传统上,科学家们倾向于将AI

腾讯AI Lab推出Locas技术实现AI长文本记忆突破
近日,一项由腾讯AI Lab团队发表于顶级学术平台arXiv(论文编号:arXiv:2602 05085v1)的研究引发了广泛关注。这项名为Locas的突破性技术,直指当前大语言模型(LLM)在处理超长上下文时面临的核心瓶颈:如何实现持续、稳定的信息记忆,同时有效防止在学习新知识时对原有能力的覆盖与

Lexsi Labs发布C-?Θ技术:AI安全控制从实时监控升级为一次性改造
2026年2月,Lexsi Labs团队在人工智能安全领域取得了一项突破性进展。其发布于arXiv平台的研究论文(编号:arXiv:2602 04521v1)提出了一种名为“C-?Θ”(电路限制权重算术)的创新技术。该技术的核心目标,是解决大语言模型(LLM)部署中的核心矛盾:如何在实现高效安全控制








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
