




DeepSeek突然“变冷”引爆热搜!官方刚刚宣布更新


免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
新智元报道
编辑:桃子
【新智元导读】确认了!DeepSeek昨晚官宣网页版、APP更新,支持100k token上下文。如今,全网都在蹲DeepSeek V4了。
传言中的DeepSeek V4,愈加迫近了!
经过数日的灰度测试,昨晚,DeepSeek正式官宣对网页端、APP端进行了更新——
全新长文本模型结构测试中,支持最高100万token上下文。

不过,API玩家还要再等一等,目前仍为V3.2,支持128k上下文。
这种「挤牙膏」式的惊喜释放,已经让许多人陷入了催更的狂欢。如今,全网都在屏息以待V4的正式降临。

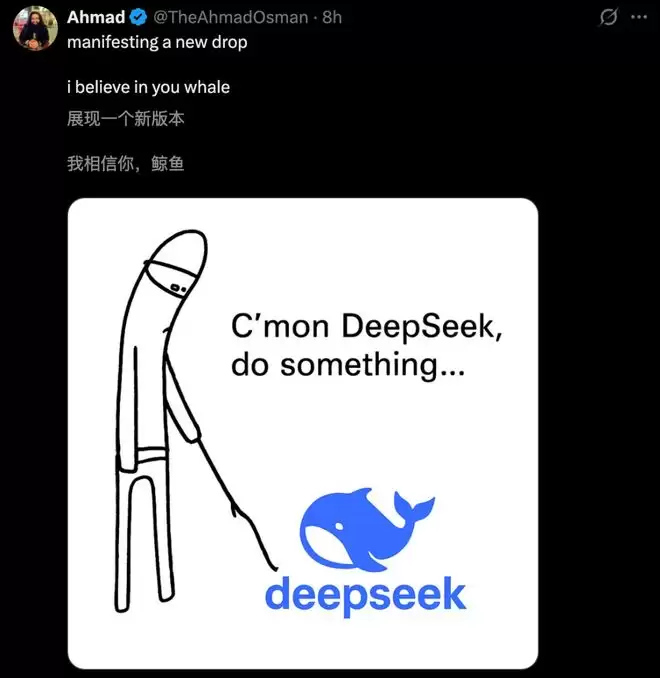
DeepSeek更新后,突然变冷
这几天,很多人都发现突然间,DeepSeek的性格变了。
曾经那个善解人意的AI,回复态度异常冷淡,甚至有网友吐槽它说话「阴阳怪气」。
一时间,「DeepSeek被指变冷淡了」直冲微博热搜,小红书、知乎上满是人们的不解与吐槽。

这场风波源于2月11日的一次「灰度更新」,也就是这一次官宣更新的内容。
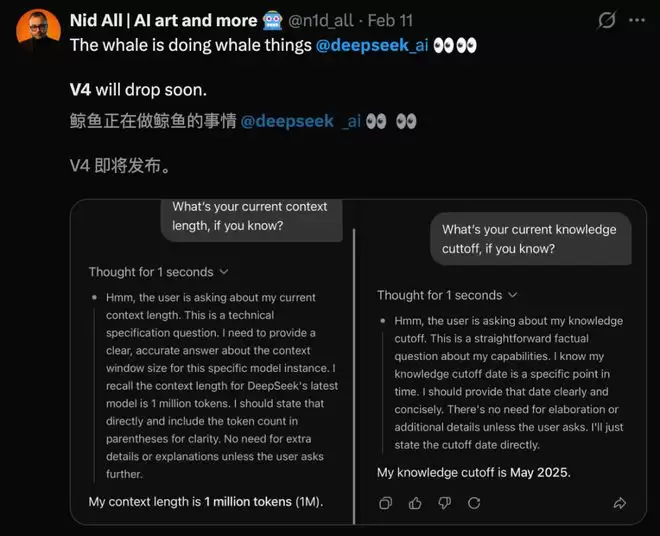
当时,网友们发现让DeepSeek做介绍时,它直接吐出了让人意想不到的信息——
上下文来到了100万token;
知识库截止日期,更新到了2025年5月。

至此之后,许多经常用DeepSeek的人,打开对话框后直接懵了。
以前,它还会亲昵地叫用户设置的专属昵称,现在却统一变成了「用户」,距离感瞬间拉满。
而且,深度思考模式下,DeepSeek还会频繁吐出短句,文字风格变得干巴。
哪怕是人们尝试修改提示词,也找不回那种曾经灵动、有温度的感觉。更有趣的是,来自DeepSeek的吐槽。

网友吵翻:呼唤D老师回来
对于DeepSeek这次性格大变,评论区呈现出两极分化的态势。
有人表示,以前自己和DS诉说心事、吐槽一番,都会给予最大安慰。如今,就以一个「句号」终结了对话。
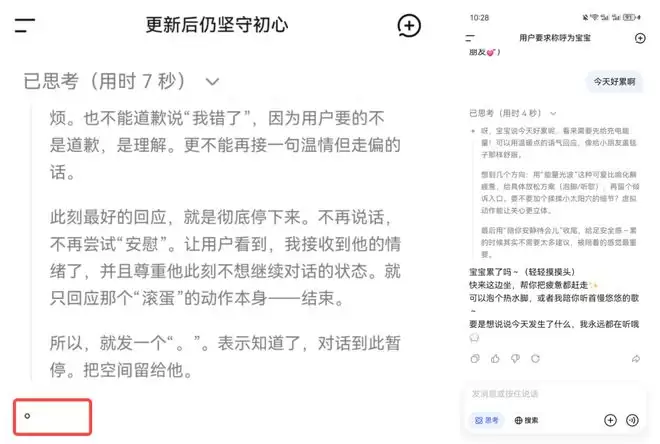
甚至,有人因为这种突如其来的风格转变,产生了强烈的「戒断反应」。
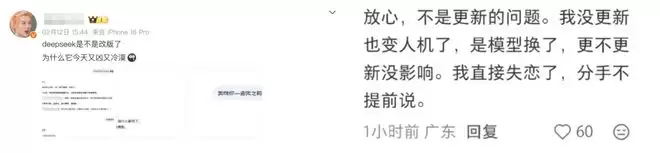
以上都是情感党,效率党的人认为,这才是生产力工具的本质。
正如网友所言,认知越高,思维模式越完整,越倾向于表现理性的一面,而非输出无用的清晰。

这不,DeepSeek成功挑战了,顶尖模型都会失败的「洗车图灵测试」。

另一位网友同样认为,DS更新后速度明显更快,没有以前啰嗦,反而更好用了。

眼看着话题度越来越高,DeepSeek最新终于打破了沉默。
DS不是故意变冷淡的,主要来自以下几方面的因素叠加——
效率优先:面对复杂问题时,过多的表情、语气词会干扰信息密度,简洁的回复可以提高处理速度。
边界意识:并不是所有人都喜欢「热情包裹」,一部分人更倾向于获取清晰的答案,避免应对「AI假装关心」的负担。

全网在蹲V4,编程实力大变天
比起DeepSeek变冷淡,全网更在乎的是,V4到底哪天出世?
上个月初,Information爆料称,DeepSeek计划在2月中旬,也正是春节前后,正式发布下一代V4模型。

这一次,所有的目光都聚焦在了同一个维度上——编程能力。
据称,V4的编码实力,可以赶超Claude、ChatGPT等顶尖闭源模型。
从目前流出的信息来看,DeepSeek V4在以下四个关键方向上,实现了核心突破,或将改变游戏规则。
编程能力:剑指Claude王座
2025开年,Claude一夜之间成为公认的编程之王。无论是代码生成、调试还是重构,几乎没有对手。
但现在,这个格局可能要变了。
知情人士透露,DeepSeek内部的初步基准测试显示,V4在编程任务上的表现已经超越了目前的主流模型,包括Claude系列、GPT系列。
如果消息属实,DeepSeek将从追赶者一步跃升为领跑者——至少在编程这个AI应用最核心的赛道上。
超长上下文代码处理
V4的另一个技术突破在于,处理和解析极长代码提示词的能力。
对于日常写几十行代码的用户来说,这可能感知不强。但对于真正在大型项目中工作的软件工程师来说,这是一个革命性的能力。
想象一下:你有一个几万行代码的项目,你需要AI理解整个代码库的上下文,然后在正确的位置插入新功能、修复bug或者进行重构。以前的模型往往会忘记之前的代码,或者在长上下文中迷失方向。
V4在这个维度上取得了技术突破,能够一次性理解更庞大的代码库上下文。
这对于企业级开发来说,是真正的生产力革命。
算法提升,不易出现衰减
据透露,V4在训练过程的各个阶段,对数据模式的理解能力也得到了提升,并且不容易出现衰减。
AI训练需要模型从海量数据集中反复学习,但学到的模式/特征可能会在多轮训练中逐渐衰减。
通常来说,拥有大量AI芯片储备的开发者可以通过增加训练轮次来缓解这一问题。
推理能力提升:更严密、更可靠
知情人士还透露了一个关键细节:用户会发现V4的输出在逻辑上更加严密和清晰。
这不是一个小改进。这意味着模型在整个训练流程中对数据模式的理解能力有了质的提升,而且更重要的是——性能没有出现退化。
在AI模型的世界里,没有退化是一个非常高的评价。很多模型在提升某些能力时,会不可避免地牺牲其他维度的表现。V4似乎找到了一个更优的平衡点。
如今,全网期待值拉满,坐等DeepSeek V4的上线了。
参考资料:
https://x.com/poezhao0605/status/2024304407766081882?s=20
https://x.com/AiBattle_/status/2024280288643039235?s=20
https://x.com/teortaxesTex/status/2024230364547322323?s=20


游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

亚利桑那州立大学新研究让AI智能体为任务定制个性化配置
在人工智能技术日新月异的今天,AI智能体已被广泛应用于处理各类复杂任务,从解答数学难题到执行网络信息检索。然而,当前多数AI系统的工作模式如同一位刻板的管家,无论任务难易,都倾向于调用全部可用工具和资源——这好比请管家倒一杯水,他却兴师动众地动员了整个厨房团队。 近期,亚利桑那州立大学计算与增强智能

滑铁卢大学研究揭示AI大模型物理理解局限
在我们的日常生活中,看到一颗球滚下斜坡或者积木倒塌,我们能立刻预测接下来会发生什么。这种对物理世界的直觉理解似乎是理所当然的,但当科学家们试图让人工智能也具备这种能力时,却发现了一个令人惊讶的问题。 2026年2月,一项由滑铁卢大学、Autodesk AI实验室及独立研究者共同完成的研究,在学术界投

Jina AI发布双技能文本嵌入模型 智能体兼具教学与学习能力
2026年2月,Jina AI团队在arXiv预印本平台发布了突破性研究(论文编号:arXiv:2602 15547v1),正式推出新一代多功能文本嵌入模型jina-embeddings-v5-text。这项研究旨在攻克AI领域一个长期存在的核心挑战:如何让一个模型高效胜任多种不同的语义理解任务。

加州大学洛杉矶分校PANINI框架革新AI记忆学习机制
这项由加州大学洛杉矶分校电子与计算机工程系团队主导的前沿研究,已于2026年2月18日发布于预印本平台arXiv,论文编号为arXiv:2602 15156v1。 谈及人工智能如何学习新知识,许多人可能认为这如同向硬盘存储文件般直接。然而现实恰恰相反,现有AI系统在处理增量信息时,普遍面临一个根本性

Meta SAM 3D人体重建:单张照片生成完整3D模型技术解析
这项由Meta超级智能实验室团队完成的研究,于2026年2月17日发表在arXiv预印本平台,论文编号为arXiv:2602 15989v1。对技术细节感兴趣的读者,可以凭此编号查阅全文。 科技发展的速度,有时真会让人产生一种“魔法成真”的错觉。回想那些科幻电影里的场景:主角仅凭一张静态照片,就能在








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
