




马斯克为何点赞中国AI模型?美企降级背后的真相

(文 陈济深 编辑 张广凯)面对中国大模型的强势崛起,美国硅谷的反应正在越发割裂。就在几天前,以反华为标签的Anthropic CEO再次对中国模型开炮,不仅表示多家中国开源模型企业“蒸馏”Clau
(文/陈济深 编辑/张广凯)
面对中国大模型的强势崛起,美国硅谷的反应正在越发割裂。
就在几天前,以反华为标签的Anthropic CEO再次对中国模型开炮,不仅表示多家中国开源模型企业“蒸馏”Claude的数据涉嫌剽窃,随后更是贬低中国模型是靠“刷题应对基准测试”才取得的排行榜跑分成绩。
但就在3月2日晚,当阿里千问开心3.5系列旗下4款小尺寸模型后,马斯克旋即在社交媒体留下了一句辣评: "Impressive intelligence density."(令人惊叹的智能密度)
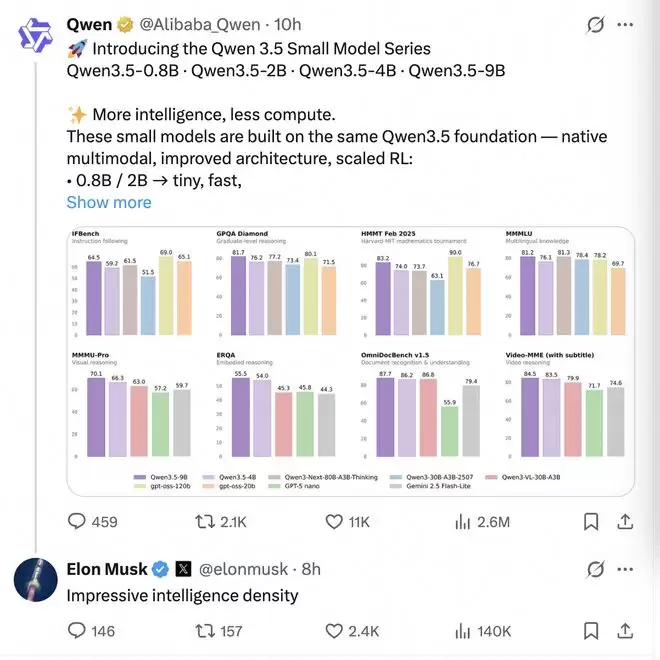
表面上看,似乎是科技狂人的一次随性点赞,但在业内人士眼里,马斯克回复“智能密度”这个用词,犹如一把尖刀,精准刺穿了Anthropic等美国AI巨头苦心经营的“高性能、高溢价”的护城河。
从堆参数到堆密度
“智能密度”是马斯克近一年来反复鼓吹的核心概念。是衡量大模型效率的关键指标。
他不仅多次表示“AI智能密度的潜力被低估了两个数量级”,也公开称赞自家Grok 5将拥有6万亿参数且每GB拥有更高的智能密度。
现在他把自己最珍视的概念送给了竞争对手,也就意味着,比起传统的商业互吹,马斯克对于这款中国的模型是真心认同。
而在同一天晚上,太平洋对岸最懂“算账”的AI创业者,给出了完全相同的答案。
MiniMax创始人闫俊杰在上市后首份财报电话会上,也提及了这个关键词,他把公司的核心战略概括为“智能密度的持续提升,加上Token的吞吐能力”。他说:“最终决定胜负的并不是单纯的烧钱和烧资源,而是智能能力进步的速度。”
两件事撞在同一天,指向同一个词。如果把时间线再拉长,你会发现这不是巧合,而是一场正在成型的行业共识。
过去三年AI行业的主旋律是军备竞赛:拼参数、拼GPU、拼烧钱。万亿参数是门槛,十万张卡是标配,谁的数字大谁就是王。但这条路的收益正在递减——模型参数翻十倍,性能可能只好了两成,成本却翻了不止十倍。
而在喧嚣之下,一条“暗线”早已浮出水面。
2025年11月,清华大学刘知远教授团队的研究登上《自然·机器智能》封面,正式提出了大模型的“密度法则”(Densing Law)。基于对51个主流大模型的严谨回测,论文揭示了一个惊人的规律:从2024年到2025年,大模型的智能密度以每3.5个月翻倍的速度增长。
这意味着每一百天,人类就可以用一半的参数量,实现当前最优模型的性能。
刘知远教授把这件事讲得非常透彻:“规模法则和密度法则就像大模型演进的明线和暗线。之前的信息革命也是如此,明线是设备越来越小,大型机→小型机→个人电脑→手机;暗线则是芯片行业的高效进化,也就是摩尔定律。”
IBM首席研究科学家Kaoutar El Maghraoui的判断更直白:“2026年将是前沿模型与高效模型之争的一年。”行业已经厌倦了单纯堆砌规模的收益递减,正在寻找新的解法。
所以我们现在看到的,并不是几个人碰巧说了同一个词。从学术界到产业界到竞争对手,一条新的共识正在合流:AI竞赛的度量衡变了。从比谁“大”,到比谁“密”。
小模型也能够实用
但并非所有人买账。
就在几天前,Anthropic CEO阿莫代伊公开唱了反调,称中国模型针对基准测试的优化,远多于对现实世界使用的优化。
翻译一下:中国模型是刷题刷出来的,不算数。
这话有其语境,也暴露了美国头部大厂的深层焦虑。中国模型每证明一次小模型也能打,Anthropic和OpenAI赖以生存的高溢价定价模式就多一分崩塌的危险——如果9B的模型能干十倍参数量模型的活儿,巨头们精心构筑的API利润池就会被瞬间抽干。
然后,马斯克转头就给千问点了赞。
这里有一层微妙的博弈:马斯克跟OpenAI和Anthropic打得不可开交。夸中国模型,某种程度上也是在敲打美国同行——你们口中不值一提的对手,正在用你们最害怕的方式挑战你们的定价权。
当然,争论归争论,密度法则给出的数字是冷冰冰的:据论文统计,GPT-3.5级模型的API调用价格在短短20个月内下降了266.7倍。这不是某个人的观点,这是技术通缩规律。
争论可以继续。曲线不等人。
千问3.5的小模型,就是这条密度曲线上最新的那一个数据点——也是最让人不敢忽视的那一个。
先说一个最直观的事实:一年前需要整个服务器集群才能跑的能力,现在装进了手机。
9B参数量的千问3.5,在多项基准上性能媲美甚至超越十倍参数量的模型:GPQA Diamond得分81.7,指令跟随91.5,视觉理解在MMMU-Pro上以70.1 vs 57.2大幅领先同级别的GPT-5-Nano。最夸张的是,不到10亿参数的0.8B模型,能一口气处理26万token的超长上下文——相当于两三本长篇小说的体量,跑在一部普通手机上,而不是发热的服务器机房里。
千问团队在16天内连发9款模型,全部Apache 2.0完全开源,每一款都在各自参数级别称王。这不是一款产品的胜利,而是一整条密度曲线的“活体证据”。
刘知远教授早就预见了这个趋势。他曾断言:“只要能实现某种智能,未来一定可以在更小的终端上运行。”
千问3.5正在验证这句话。
当9B模型能跑出十倍参数量的性能,AI的部署门槛就从“有服务器集群的大公司”降到了“有一张消费级显卡的个人开发者”。当几百人的公司能做出与数千人巨头掰手腕的模型,创业公司入场的门槛就从“先融十亿美元”变成了“先找三百个聪明人”。
MiniMax就是后一种故事的注脚。全公司385人,平均年龄29岁,据闫俊杰在电话会上披露,公司成立至今累计花费仅5亿美元——对比OpenAI的数千员工和数百亿融资,交出的却是营收增长159%、毛利增长437%的答卷。智能密度不只是模型参数的物理概念,也是一种极其强悍的组织杠杆。
不要低估个人设备的汪洋大海。 信息革命初期曾有人预言“全球只需要几台大型计算机”。但到了今天,全球有超过70亿部手机。刘知远曾算过一笔账:早在2024年,全国散落在千万部设备上的端侧算力总和,就已经是数据中心的12倍。
智能的终局,注定是分布式的。
这才是“智能密度”比任何一次跑分都重要的原因。它指向的不是“谁的模型今天更强”,而是“AI最终以什么形态、多低的成本、来到每一个普通人身边”。
回到马斯克那句“Impressive intelligence density”。与其说他在夸赞一家中国公司的某次发布,不如说他在确认一个正在发生的转折:
AI的下半场,不属于最大的模型,属于最密集的智慧。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

高刷显示器提升FPS游戏命中率,LG Display研究证实
LGDisplay研究显示,31名玩家在60Hz至480Hz刷新率下测试第一人称射击游戏。对比60Hz,480HzOLED显示器命中率提升约38%,其中60Hz升至240Hz提升最为显著,再升至480Hz再增约10%,输入延迟减少超过10毫秒。

年确认不插入闰秒,距上次调整已10年
国际地球自转和参考系服务宣布2026年末不插入闰秒,距上次调整已隔十年。闰秒用于协调原子时与地球自转时,已调整27次均为正闰秒。因气候变化导致地球自转减速,首个负闰秒推迟至2029年,国际计量界计划2035年前废止闰秒机制。

红米Note 17 Pro首销活动送电池升级保五年免费换新
REDMINote17Pro首发提供五年电池升级保障:前四年电池健康低于80%免费换新,第五年升级为更大容量电池。内置9000mAh电池,支持67W快充与22 5W反向充电,配备康宁大猩猩Victus2玻璃及四重防水认证,防护规格对标旗舰。

三星A18渲染图曝光 机身变厚或搭载6000mAh电池
据悉,三星A18最新渲染图曝光,其机身厚度增至7 84毫米,较上一代增加0 34毫米,推测或为配备6000毫安时大容量电池。此外,外观延续水滴屏设计,后置三摄模组有微调,并且底部配备USB-C接口,还支持快速充电功能。

三星S26像素级防窥屏幕隐私保护再升级
三星GalaxyS26系列搭载像素级隐私显示技术,从硬件层面控制OLED子像素发光方向,实现物理级防窥,正面观看画质无损,侧面超60°即模糊。该功能深度集成OneUI8 5,支持智能场景触发和多档位强度调节,与Knox安全平台形成防护体系,无需贴膜,不损画质。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
热门教程
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:41
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
2026-07-12 12:40
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















