




商汤多模态大模型:剑指世界级,一体化架构实现图像智能生成

智东西作者 陈骏达编辑 李水青智东西3月6日报道,今天,商汤科技发布最新技术博客——《NEO-unify:原生架构打造端到端多模态理解与生成统一模型》。NEO-unify是一个从底层统一多模

智东西
作者 陈骏达
编辑 李水青
智东西3月6日报道,今天,商汤科技发布最新技术博客——《NEO-unify:原生架构打造端到端多模态理解与生成统一模型》。NEO-unify是一个从底层统一多模态理解与生成的端到端原生架构,在保留抽象语义与细粒度表征的同时,展现更高数据训练效率。
当前,多模态模型普遍采用“视觉编码器(VE)用于理解,变分自编码器(VAE)用于生成”的组合式设计。这套范式虽行之有效,却也内在割裂了感知与创造,常面临模块协同与效率权衡的挑战。
能否更进一步,让AI像人一样,直接从最原始的像素和文字中,统一地进行学习、理解与生成?这正是NEO-unify尝试回答的根本问题。它摒弃了传统的VE与VAE,首次构建了一个真正的端到端原生统一模型,在同一个架构内直接处理像素与文本,并在此基础上协同完成理解与生成任务。
初步研究成果显示,该设计在保持强大语义理解与细节恢复能力的同时,显著提升了训练与计算效率。
博客地址(英文):
https://huggingface.co/blog/sensenova/neo-unify
博客地址(中文):
https://www.sensetime.com/cn/news-detail/51170543?categoryId=72
一、不需要VE也不需要VAE,模型表现打平Qwen3-VL
长期以来,多模态研究已形成一种默认范式:视觉编码器(Vision Encoder, VE)负责感知与理解,而变分自编码器(Variational Autoencoder, VAE)则用于内容生成。近期的一些工作尝试构建共享编码器,但这种折衷往往引入新的结构性设计权衡。
由此回到第一性原理:构建一体化模型直接处理原生输入,即像素本身与文字本身。商汤科技联合南洋理工大学,提出一种全新的架构范式:NEO-unify(preview),一个原生、统一、端到端的多模态模型架构。它不仅越过了当前视觉表征的争论,也摆脱了预训练先验和规模定律瓶颈的限制。最关键的是:不需要VE,也不需要VAE。
NEO-unify则是一个端到端统一框架,能够直接从近乎无损的信息输入中学习,并由模型自身塑造内部表征空间。
它首先引入近似无损的视觉接口,用于统一图像的输入与输出表示;其次,采用原生混合Transformer(Mixture-of-Transformer,MoT)架构,使理解与生成能够在同一体系中协同进行。
最终,通过统一学习框架实现跨模态训练:文本采用自回归交叉熵目标,视觉通过像素流匹配进行优化。
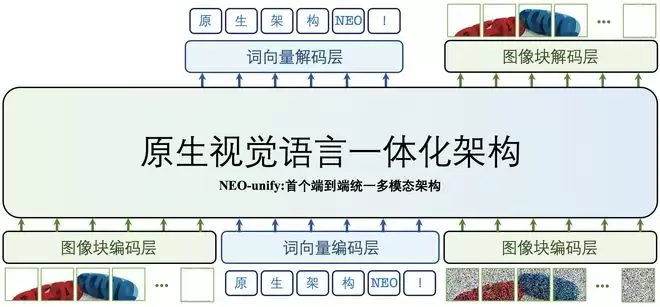
实验结果显示,采用NEO-unify架构的模型在多项基准测试上的表现超过同尺寸的前沿视觉语言模型,排进了同尺寸模型的第一梯队,基本与Qwen3-VL模型打了平手。
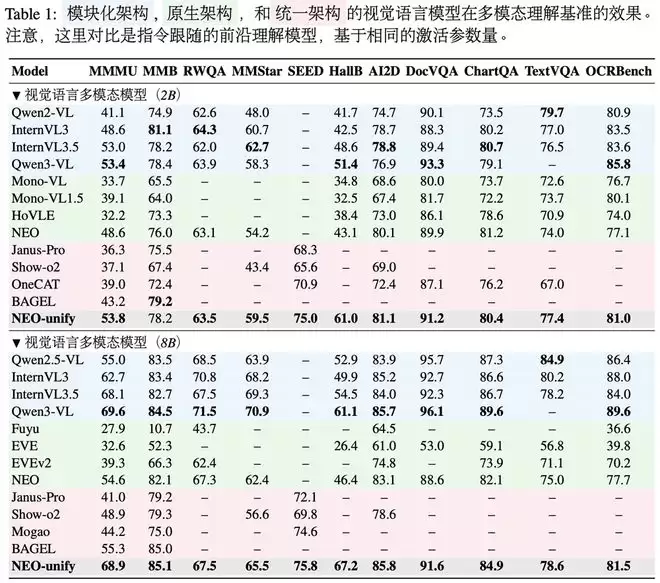
二、无编码器同时保留抽象语义与细粒度表征,展现更高数据训练效率
那么,这一模型背后究竟有哪些关键技术发现呢?
商汤此前的工作NEO(Diao et al., ICLR 2026)表明,原生端到端模型同样能够学习到丰富的语义表征。在此基础上,商汤进一步观察到一个有趣的现象:即使在冻结理解分支的情况下,独立的生成分支仍然能够从表示中抽取并恢复细粒度的视觉细节。
基于这一发现,商汤训练了NEO-unify(2B)。在初步9万步预训练后,模型在MS COCO 2017上取得31.56 PSNR和0.85 SSIM,而Flux VAE的对应指标为32.65和0.91。这一结果表明,即使不依赖预训练VE或VAE,近似无损的原生输入仍能够同时支持高质量的语义理解与像素级细节保真。
据此,商汤进一步开展探索:NEO-unify将所有全模态条件信息统一输入到理解分支,而生成分支仅负责生成新的图像。
在冻结理解分支的情况下,NEO-unify(2B)仍展现出较强的图像编辑能力,同时显著减少了输入图像token的数量。在使用开源生成与图像编辑数据集并进行初步6万步混合训练后,模型在ImgEdit基准上取得3.32的成绩,且理解分支在整个训练过程中保持冻结。
借助预训练的理解分支与生成分支,NEO-unify使用相同的中期训练(MT)与监督微调(SFT)数据进行联合训练。即使在较低的数据比例和损失权重下,理解能力依然保持稳定,而生成能力则收敛很快。二者在MoT主干中协同提升,整体冲突极小。
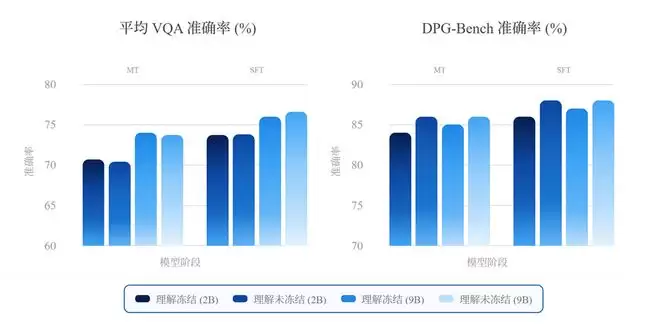
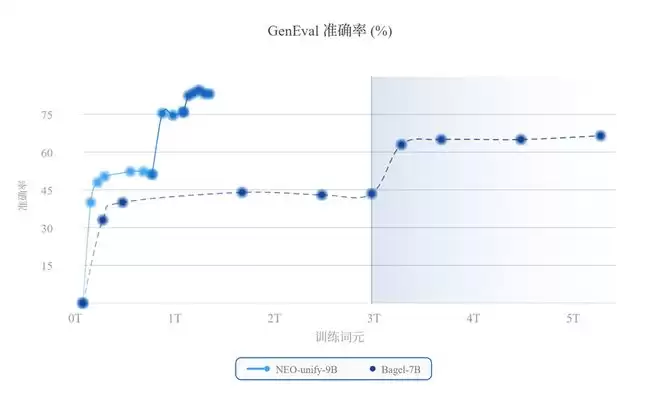
此外,商汤首先进行web-scale预训练,随后在多样且高质量的数据语料上依次进行中期训练(MT)和监督微调(SFT)。与7BBagel模型相比,NEO-unify展现出更高的数据训练效率,在使用更少训练token的情况下取得了更优的性能。
结语:多模态理解与生成一体化或成世界模型基础
NEO-unify团队认为,随着多模态理解生成一体化的模型出现,模型不再在模态之间进行转换,而是能够原生地跨模态思考。多模态AI不再只是连接不同系统,而是构建一个从未割裂的统一智能体,并让所需能力从其内部自然涌现。
理解生成一体化是AI大模型领域的前沿方向之一,被认为是更接近人类智能的一种模型形式。目前,业界已经基本完成文字理解生成一体化模型的探索,而多模态理解生成一体化模型,则有望成为全模态推理、视觉推理、空间智能乃至世界模型的重要基础。

你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:商汤多模态大模型:剑指世界级,一体化架构实现图像智能生成要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点佑驾创新与乐动机器人达成战略合作,围绕技术、产品、场景、数据四维度展开深度协同,旨在加速物理AI规模化落地,拓展无人车与机器人场景边界,推动具身智能商业化进程。
Meta开放AI算力租赁业务,市场反应从算力过剩转向算力商业运营。GPU从自用转向对外出租,算力从成本中心转为利润中心。AI云竞争核心从拥有GPU数量转向稳定跑满GPU的能力,依赖同步与参考时钟等底层基础设施的长期稳定运行。
针对大型多仓库工程(30+微服务、10+前端微应用),搭建包含规则、技能、子代理、13阶段工作流与门禁脚本的Harness系统,解决PRD不可信、方案与代码脱节、改完无人验证、交付环节琐碎等痛点,使AI在真实业务中稳定跑完需求。
部署MCP Toolbox前,先看清它的适用场景与安全边界,避免在权限管理不完善时接入敏感数据。 核心内容: 1 MCP Toolbox的核心功能与两种使用路线 2 项目适合与不适合的团队场景分析 3 实际验证的安全检查与关键限制 先说结论 MCP Toolbox 很适合小团队研究“让 AI
- 日榜
- 周榜
- 月榜
热点快看