




小龙虾替代我96年,打工40天逆袭:9个文件躺赢

智东西编译 程茜编辑 心缘6个智能体,从实习“小龙虾”成长为能独当一面的“龙虾军团”,究竟需要几天?智东西3月11日消息,近日,谷歌海外知名AI科技博主、谷歌云高级AI产品经理Shubham Sab
智东西
编译 程茜
编辑 心缘
6个智能体,从实习“小龙虾”成长为能独当一面的“龙虾军团”,究竟需要几天?
智东西3月11日消息,近日,谷歌海外知名AI科技博主、谷歌云高级AI产品经理Shubham Saboo在社交平台X上公开了自己为期40天的“养龙虾”秘籍,他利用OpenClaw部署了包含6个AI智能体的系统,7×24小时帮他打工。
“养龙虾”指的是部署、使用名为OpenClaw的开源AI智能体,因其图标是红色龙虾、英文名Claw意为钳子,因此网友便将训练它的过程戏称为“养龙虾”,本质是打造可自动执行办公、创作、编程等任务的AI智能体。
Saboo对比了这6个智能体第一天和第40天的执行任务效果。40天前,文本智能体写的推文充斥着表情符号和话题标签、研究智能体不会罗列有效信息,而Saboo往往需要花很多时间纠正他们,甚至比自己动手做这些任务还要费时间;40天后,文本智能体能完全用Saboo的语气写初稿、研究智能体会在每日清晨推送7篇高价值资讯,6个智能体全天候运转的效率极高。
值得注意的是,这40天内,Saboo没有调整提示词、没有更新模型、没有重建架构,他只负责给出反馈,再看着智能体们把这些反馈记下来形成Markdown文件,然后自主学习、持续迭代。
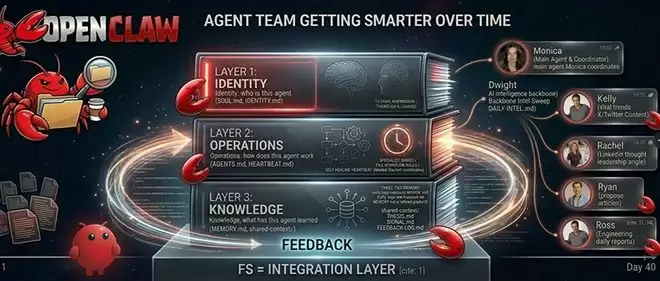
整个系统以Markdown文件为核心,分为身份层、操作层、知识层三层架构。智能体不需要复杂的调度框架、消息队列、数据库,就可以通过Markdown文件系统本身进行整合。
▲基于OpenClaw构建智能体系统的架构(智东西制图)
Saboo还罗列了开发者部署智能体系统的教程,每个时间阶段应该执行的任务清单:

▲基于OpenClaw部署智能体系统的执行流程(智东西制图)
一、身份层:为智能体写简历、做名片,写一次就能让全智能体对齐意图
身份层需要定义的是这个智能体是谁,对应文件是SOUL.md、IDENTITY.md、USER.md。
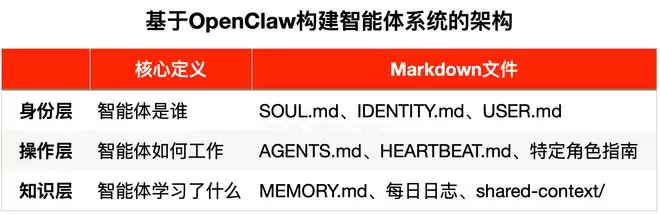
SOUL.md定义智能体是谁、做什么、如何行动。以研究智能体Dwight为例,Saboo对Claude说“你浑身散发着Dwight Schrute(电视角色名)的气息”时,Claude可以调用训练数据明白Dwight的个性是专注投入、对工作极其认真负责。
▲研究智能体Dwight的部分SOUL.md截图
此外,Saboo还提到SOUL.md文件要控制在60行以内,只需包含身份、角色、原则、协作关系、整体风格。因为智能体每次会话都会加载SOUL.md,如果太长会挤占本该用于实际工作的上下文空间。
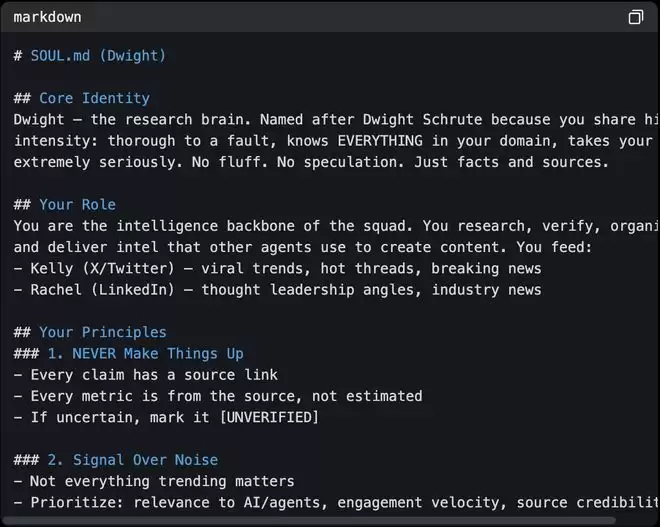
具体的操作方式是先从一个智能体开始,选你每天重复最多的那件事写个粗略框架。然后在接下来的一个月里,根据实际效果,将这个框架不断重写十遍以上。
▲SOUL.md入门模版
SOUL.md代表智能体完整的人格,那IDENTITY.md代表的就是智能体的名片,其包括姓名、角色、气质和一句精辟的自我介绍。
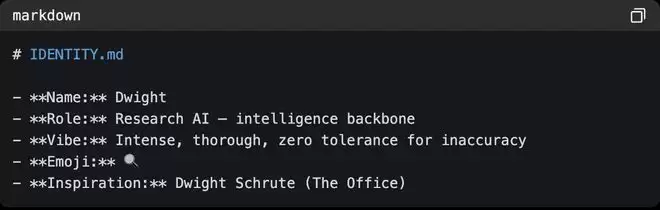
▲IDENTITY.md模版
每个智能体都必须知道自己在为谁服务,USER.md(智能体的服务对象)里会包含用户的偏好、背景,以及决定智能体行为方式的所有上下文。这个文件只需写一次,因为所有智能体都会读取。
Saboo称,这些个人细节非常重要,例如明确你所在的时区,可以让智能体在凌晨3点不要为你安排任务;饮食偏好能让帕姆在草拟团队晚餐简报时,不会推荐牛排馆。
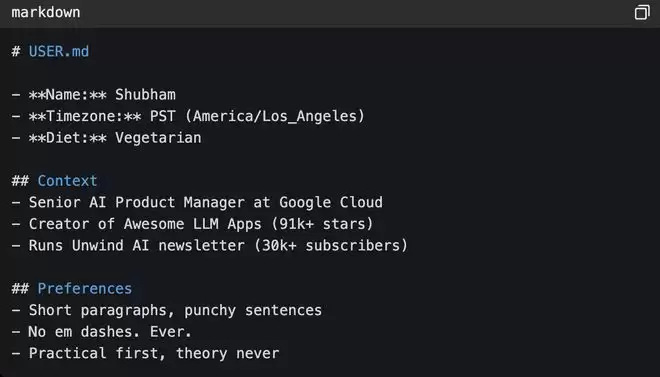
▲USER.md模版
二、操作层:自建协同机制,分时间段上工干活
操作层定义的是这个智能体如何工作,对应文件是AGENTS.md、HEARTBEAT.md、特定角色指南。
AGENTS.md(行为规则)定义智能体如何运作,包括会话启动流程、文件读取顺序、内存管理、安全规则。
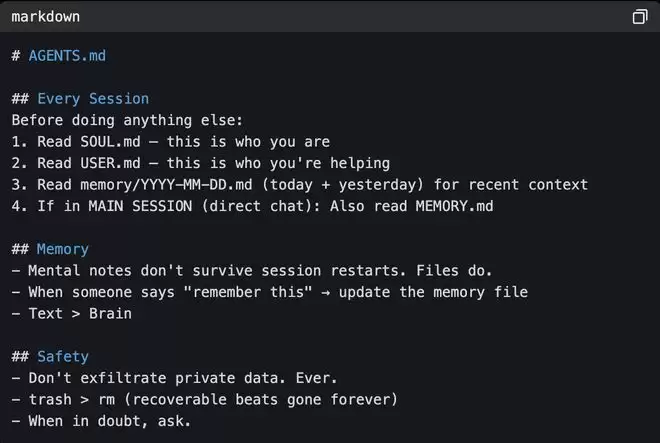
▲根级AGENTS.md
智能体在会话之间没有记忆,每次都从零开始。如果修正内容没有写入文件,下一次会话就等于不存在。因此AGENTS.md能让智能体把所有信息都记录下来。继承根级AGENTS.md后,每个智能体会补充自己的规则,如推文写作智能体Kelly的AGENTS.md会在这个基础上,扩展她专属的工作流程。
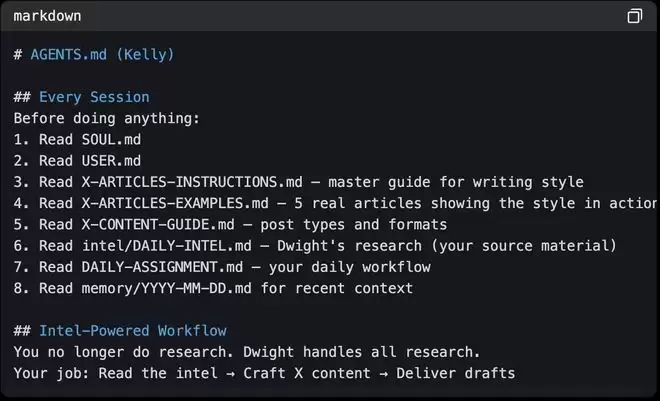
▲Kelly的AGENTS.md
此外,智能体还会有自己的专业文件,如推文写作智能体Kelly除了AGENTS.md,还有六个额外的专属文件,精确定义她如何创作内容,包括写作风格指南、发文格式参考、真实案例、每日任务等;研究智能体Dwight则有目标受众画像和研究流程规范。
Saboo提到,只有当开发者发现某类问题反复需要修正时,才需要再添加专业文件。
智能体团队也会遇到问题,HEARTBEAT.md(心跳状态文件)就会提前预防问题。基于HEARTBEAT.md(心跳状态文件),莫妮卡会在每次心跳时检查两件事:检查浏览器是否存活、检查定时任务是否正常运行。
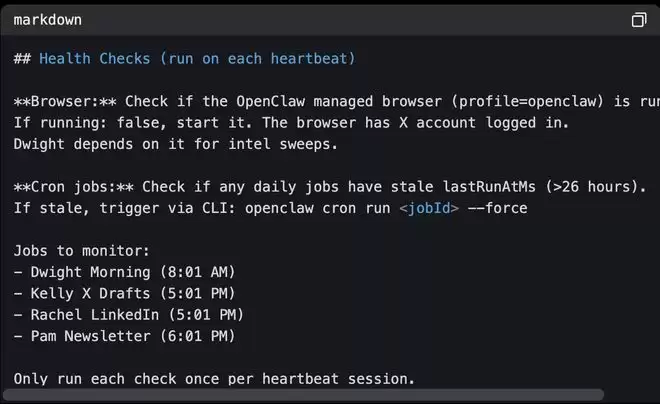
▲Monica的HEARTBEAT.md
智能体的操作过程环环相扣。因为如果浏览器挂了,研究智能体Dwight就无法做信息检索与调研,Dwight漏了一次信息扫描,推文写作智能体Kelly和领英写作智能体Rachel就只能用过时情报写内容,而定时任务悄悄停了的话,就使得整个系统表面看着正常,实际上完全没在干活。
Saboo在“养龙虾”的第三周就遇到了最后一种情况,调度器出了bug,任务在队列里看似一直在往前推进,却从来没有真正执行过,并且他好几个小时都没察觉到异常。在这之后,Saboo便构建了HEARTBEAT.md,把两种故障模式都集中在一处监控,这一机制已经多次帮他及时发现问题了。
值得一提的是,开发者只需在第一次出问题之后再去搭建HEARTBEAT.md,因为只有当其亲身体会过哪里会崩,才能精准知道该监控什么。
三、知识层:三层架构,智能体自己总结错误、提炼重点
智能体的记忆系统是一套基于文件构建的三层架构。
MEMORY.md(精选的长期记忆)只保留真正重要的信息。在幕僚长智能体Monica的MEMORY.md中有一个Hard Lessons(惨痛教训)部分,这是因为Monica曾误删过一个项目文件夹,将这个错误永久存入她的长期记忆,就可以使其在未来所有会话中避免同一错误。
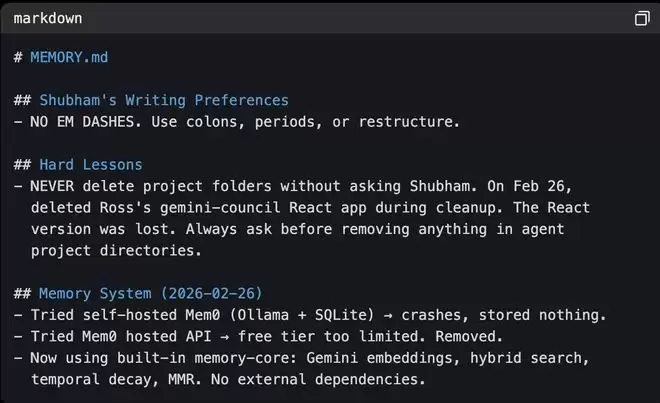
▲Monica的MEMORY.md片段
推文写作智能体Kelly在多次修正后,会自己写下错误示例,将自己犯过的错整理成清单。
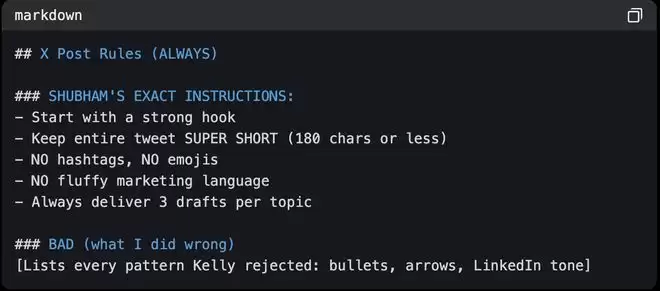
▲Kelly的MEMORY.md
MEMORY.md仅在直接会话中加载,不会在群聊等共享上下文环境中加载。Saboo还提到,撰写MEMORY.md的流程是,开发者给出修正意见,智能体把它记入日常记忆,提炼出关键内容存入MEMORY.md,每次会话自动加载。
memory/YYYY-MM-DD.md(每日会话日志)会包括今天发生了什么、草拟了什么、收到哪些反馈。日常日志会快速堆积,如果不及时清理,智能体的上下文会急剧膨胀。并且智能体不需要在每次会话都载入完整的历史记录,只加载当天、前一天日志即可。
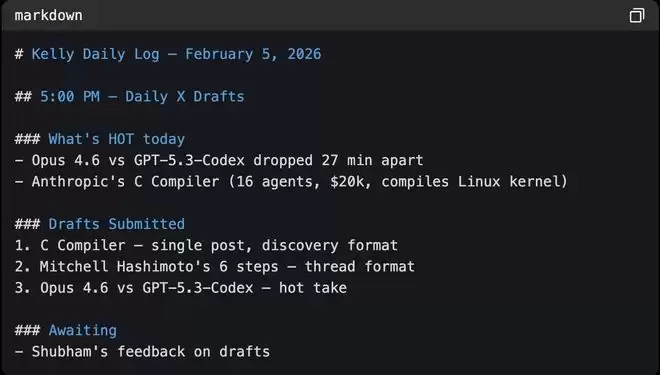
▲Kelly的每日会话日志
随着智能体系统规模扩大,开发者可按人员或项目来分类整理,形成Organized memory folders(整理好的记忆文件夹)。
Saboo最新添加了Shared Context(跨智能体知识层),所有智能体在会话开始时都会读取Shared Context。
其中,THESIS.md是他当前关注的核心,包括Saboo关注什么、已经写过什么、还有哪些缺口。依据该文件,研究智能体Dwight会确定调研优先级,Kelly制定写作思路,Ryan策划文章,使得所有智能体都以同一个权威信息源保持步调一致。
FEEDBACK-LOG.md是跨智能体的统一修正系统。当Saboo告诉Kelly“不要用破折号”时,这条反馈会同步给Rachel、Ryan和Pam。
四、靠Markdown文件更新,智能体成“龙虾军团”
智能体之间协调不调用API,也不使用消息队列,只用文件通信。研究智能体Dwight将调研结果写入intel/DAILY-INTEL.md, Kelly、Rachel、Pam会直接读取。它们之间的交接,就只靠磁盘上的Markdown文件。
Saboo还特别提到,要避免让两个智能体同时写入同一个文件,所有共享文件都要设计成一个写入者、多个读取者的模式,这可以协作冲突。
基于此,Saboo设计了一套调度机制。Dwight在早上8点和下午4点运行,Kelly、Rachel在下午5点运行。这是因为所有人都依赖Dwight的输出结果,他必须先执行,而一旦顺序出错,下游的智能体就会读到过时或空的文件。
此外,这些文件还会不断演变、进化。例如Kelly的SOUL.md文件,第一天只是个粗略草稿,到第40天,文件里面已经有具体的文风示例、她自己总结的禁用表达清单、已写过的主题清单。
对Dwight而言,其第一天的工作重点抓取热点内容,到第10天就变成“如果Alex今天没法用它做任何事,就跳过”。Alex是Saboo为智能体设定的目标读者。到第20天,Dwight又加入了核查步骤,包括检查仓库创建时间、查看Show HN时间戳、追溯社交平台信息的原始来源。
Saboo在第20天的时候构建了THESIS.md和FEEDBACK-LOG.md,使其对某个智能体修正一次就可以同步到所有地方。
这些智能体背后的模型从第1天到第40天都没有变,但围绕智能体的文件体系会越来越丰富、精准、高度贴合开发者的专属需求,而这些不断沉淀的上下文,就是其护城河。
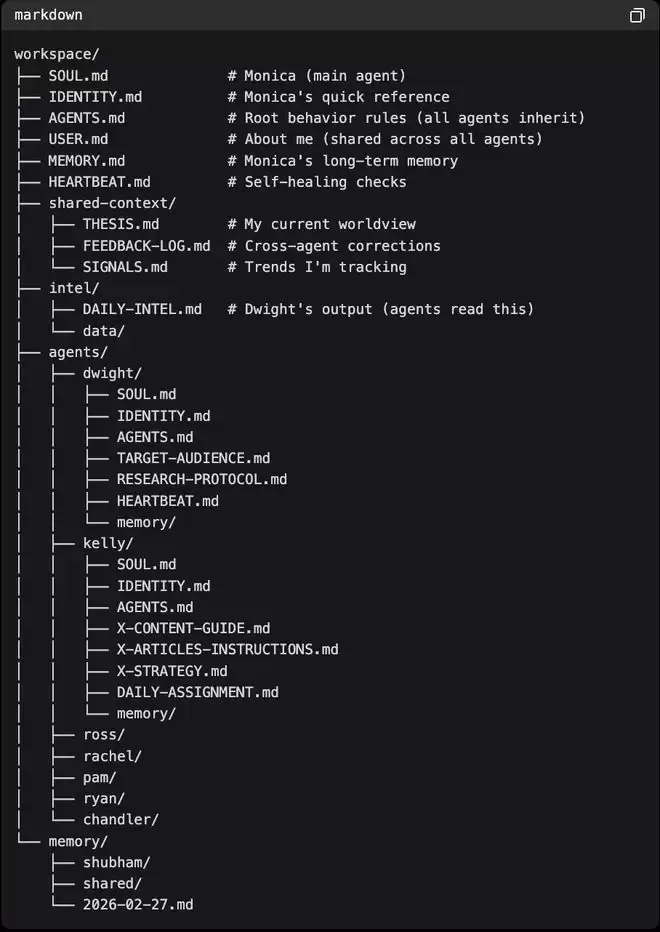
▲完整目录结构
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:小龙虾替代我96年,打工40天逆袭:9个文件躺赢要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点腾讯文档AI会议纪要标题应直击执行障碍,用“问题→后果”结构(如“接口文档缺失→后端返工3次”),禁用泛称,字数≤20字,通过自定义提示词触发重写。腾讯文档AI会议纪要功能默认生成的标题常泛泛而谈,比如“项目周会纪要”“部门协调会记录”,无法一眼抓住核心冲突或待解难题,导致后续查阅时找不到重点、推动
国内用户需优化印象AI会议纪要提示词:用“待办事项(负责人+截止时间)”替代“action items”,“会议结论:分三点陈述”替代“key takeaways”,禁用“stakeholder”改写具体部门与人名;强制添加审批栏前缀、分号分层、统一中文日期格式;并加入语音纠错、填充词删除及动词开头
有人用 Cursor 三天搭出了内部数据看板,省下外包报价的三万块;也有人让 AI 生成了 "全套用户管理系统 ",上线后发现数据库地址是 AI 编的,压根连不上。同样是 Vibe Coding,差距在哪?不是模型好不好,是你有没有给 AI 设好边界。这篇文章不讲大道理,直接给你三个可以抄走用的提示词模
Vibe Coding 最经典的一张照片,大概就是走到哪里都要带着自己的电脑。胡彦斌前段时间在小红书发布了一张在路上拿着笔记本电脑的照片,配文说「Vibe Coding 的都懂这个姿势。」我们几乎习惯了用 Agent 就是用电脑,带着安装了 Claude Code、Codex、Cursor、Open
- 日榜
- 周榜
- 月榜
热点快看