




苹果LiTo大模型发布:单图生成3D对象,AI还原多视角光影

科技媒体IT之家3月17日消息,据外媒9to5Mac昨日报道,苹果AI研究团队发布最新突破性成果,成功攻克了3D重建领域的一项核心技术难题:仅需输入单张平面图像,即可生成完整的三维对象模型。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
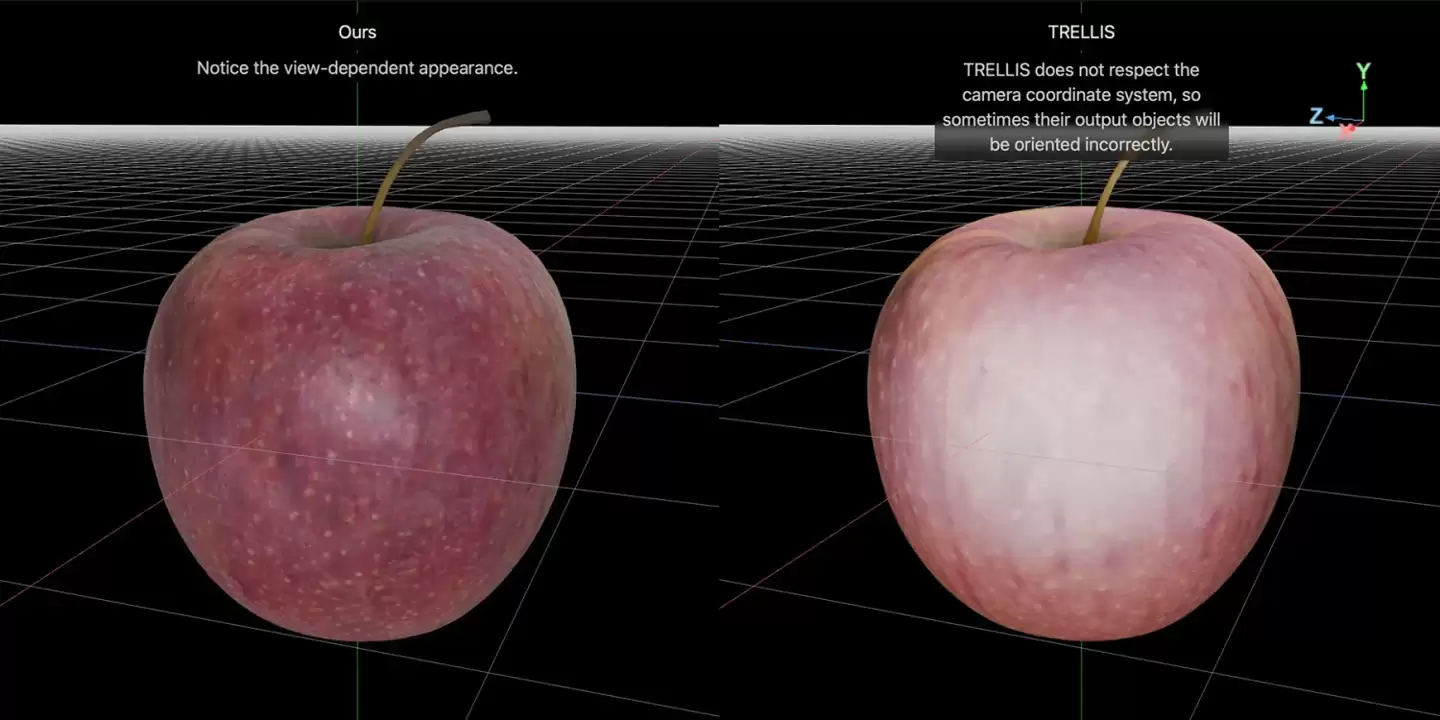
这项名为LiTo的创新模型,打破了传统方法需要多角度图像输入的限制。在完成3D对象重建后,即使切换不同观察视角,模型生成的反光、高光等光影效果仍能保持高度的物理真实性与视觉一致性。
该突破的核心在于对"潜在空间"的创新应用。在机器学习领域,潜在空间能够将复杂信息压缩为多维数学向量,从而大幅降低计算复杂度与资源消耗。
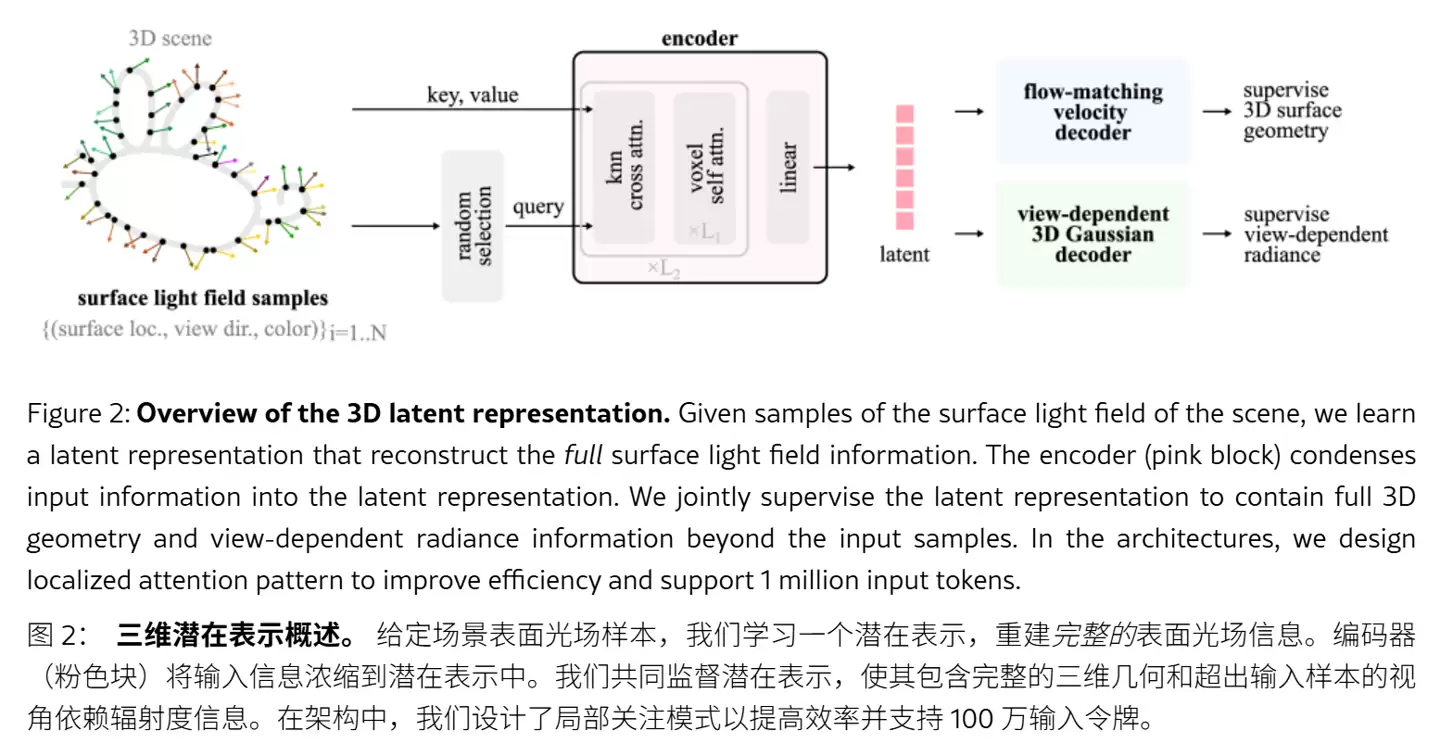
LiTo模型首创了统一的3D潜在表示法,将随机采样的表面光场数据编码为紧凑的向量集合。这意味着模型无需死记硬背每个视觉细节,而是通过数学描述,同时掌握对象的物理形状以及光线与其表面交互的底层规律。
在具体运行机制上,LiTo编码器负责"压缩信息",将输入图像中的几何结构和视角相关的外观特征,转化为潜在空间中的精简代码。
随后,解码器执行"逆向解压",利用这些底层代码完整还原出3D对象。这种双向机制让模型能够精准复现复杂光照条件下的镜面高光和菲涅尔反射等高级光影特效。
为打造这一模型,苹果研究人员使用了数千个在150个不同视角和3种光照条件下渲染的3D对象进行高强度训练。系统通过不断抽取小部分数据样本,训练解码器在不同光照和视角下还原完整对象。
最终,模型具备了仅凭单张图片就能预测其三维潜在表示的能力。在苹果公布的最新对比测试中,LiTo在多视角光影还原度上显著超越了现有的TRELLIS模型。





游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

清华大学研发稀疏注意力技术 AI视频生成速度提升18倍
这项由清华大学和加州大学伯克利分校联合开展的研究,已于2026年2月以论文形式发布(编号arXiv:2602 12675v1),为AI视频生成领域带来了一项关键突破。 想象一下,让AI生成一段视频,就像要求一位超级画家逐帧绘制一部动画。这位“画家”需要对画面中的每一个像素、每一处细节都投入同等的精力

普林斯顿大学新突破让模型学会序列思考大幅提升长文本理解能力
在处理长篇文本时,人类大脑能够轻松构建连贯的叙事脉络,而许多人工智能模型却受限于逐词预测的模式,难以把握整体语义。普林斯顿大学的研究团队精准定位了这一核心瓶颈,并创新性地提出了名为“REFINE”的革命性训练框架,成功引导AI模型掌握了“序列思考”的关键能力。 这项由普林斯顿大学计算机科学系团队完成

加州理工斯坦福联合研究揭示大语言模型推理失误原因
你有没有想过,那些看起来无所不知的AI聊天机器人,其实也会犯一些令人啼笑皆非的错误?就像一个博学的教授在课堂上突然说出“1+1等于3”这样的低级失误。近期,一项由加州理工学院和斯坦福大学联合开展的研究,系统性地梳理了大语言模型在推理过程中的各类“翻车”现场,相关成果已于2026年1月发表在《机器学习

VESPO算法详解大语言模型如何高效学习过时信息
这项由小红书技术团队主导的前沿研究,已于2026年2月正式发表于预印本平台arXiv,论文编号为2602 10693v1。该研究精准聚焦于大语言模型强化学习训练中的一个长期痛点——训练稳定性,并创新性地提出了一种名为VESPO的优化算法。该算法旨在从根源上缓解因“策略陈旧性”或“信息过时”所引发的训

微软研究院揭示大语言模型训练崩溃原因与稳定等级骤降影响
训练一个现代大语言模型,过程有点像教一个天赋异禀但性格敏感的学生。你得循序渐进,精心调整每一步。然而,一项由微软SIGMA团队与新加坡国立大学合作的研究,却揭示了一个令人深思的现象:即便是最先进的模型,在训练过程中也可能毫无征兆地突然“崩溃”,仿佛之前学到的所有知识瞬间清零。这项发表于2026年初的








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
