




黄仁勋发Token当工资,硅谷兴起一场烧掉33个维基百科的流量竞赛

梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
OpenAI最烧Token的人有多狠?
一位匿名员工,上周处理了2100亿Tokens,是全公司之最,足够把整个维基百科填满33遍。
他不是在做什么惊天大项目,就只是公司内部排行榜第一名而已。
与此同时,在隔壁Anthropic一位Claude Code用户单月账单超过15万美元,折合人民币过百万元。
这便是硅谷新风尚Tokenmaxxing,直译过来就是“Token刷量大赛”。
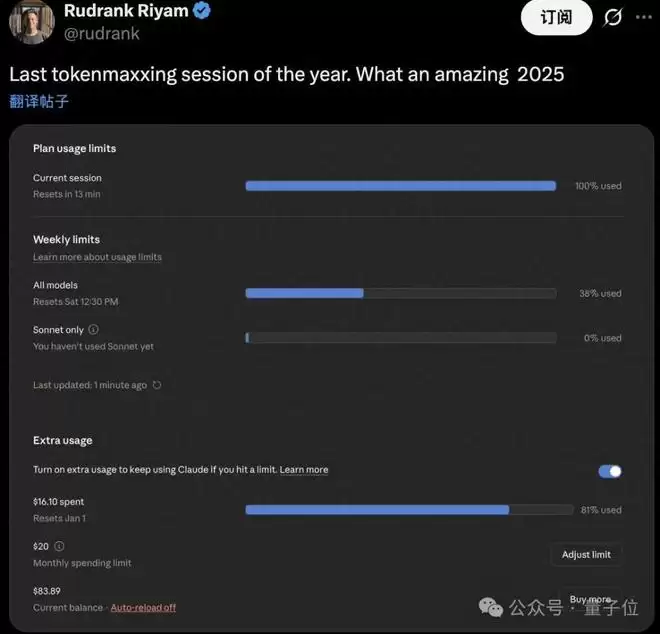
具体来说:
AI公司内部开始出现排行榜,追踪每个员工的token消耗量;招聘时,”你能给我多少token预算“正在成为工程师最关心的问题之一;Meta和Shopify甚至把AI使用量写进了绩效考核标准。
Token这个AI处理的最小文本单位,正在从技术术语变成硅谷的新型货币。
从月付200到年烧10万
风投机构Theory Ventures创始人Tomasz Tunguz亲身经历了Token账单的指数级膨胀。
六个月前,他每月在Claude上花200美元。然后加了三个agent订阅Codex、Gemini和Claude Code,月费涨到600美元。
接着他开始用AI把待办清单自动变成完成清单,每天处理31项任务,日均推理账单飙到92美元。再加上每月400美元的智能体浏览器。
半年之内,他的AI推理支出从年化7200美元涨到4.3万美元,再到超过10万美元。

但在一年前,一个人想用掉这么多token几乎不可能。
假设一个学生写篇论文,来回修改几轮,大概消耗1万个token,约等于7500个英文单词。
要烧掉几十亿个Token,得在电脑前不停下指令好几十小时。
Coding Agent改变了一切。
Claude Code、Codex这类工具可以在无人监督的状态下连续工作数小时,审查和编辑大型代码库,从一条指令生成完整程序。每个agent还能派生出子agent处理不同子任务,每一步都在生成成千上万个Token。
龙虾OpenClaw更是24/7不停工作。
Token消耗的爆炸直接推高了AI公司的收入。
Anthropic今年在两个月内将收入预期翻了一倍多,Claude Code年化收入达到25亿美元。
OpenAI的Codex周活跃用户超过200万,年初以来增长两倍,Token使用量增长五倍。
Google去年透露,其AI模型每月处理超过1.3万万亿(quadrillion)个Token。
不过,这场增长背后有个关键推手:补贴。
OpenAI和Anthropic都在200美元/月的订阅计划里提供了价值约1000美元的Token额度。
和当年打车、外卖用发优惠券抢市场的逻辑一模一样。
Token成为第四种薪酬
英伟达GTC 2026上,黄仁勋把这股暗流推到了台面上,抛出了一个让所有人竖起耳朵的提议:
工程师年薪几十万美元,我会在基础薪资之上再给他们相当于一半年薪的token,让他们能力放大10倍。当然我愿意这么做。
黄仁勋成了第一个公开谈论“公司Token预算”的重量级CEO。
在他的框架里,Token正在变成继工资、奖金、期权之后的第四种薪酬。

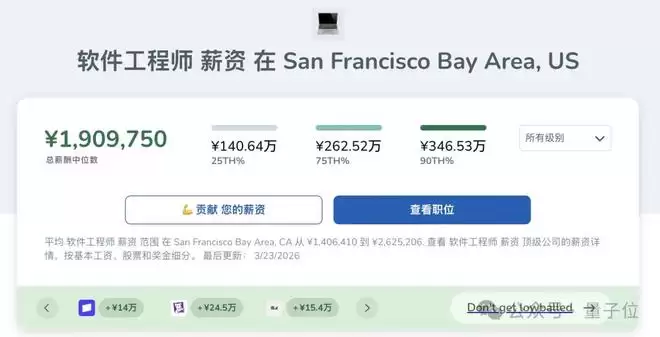
根据薪酬追踪 Levels.fyi的数据,硅谷75分位软件工程师的年薪是37.5万美元(约262万人民币)。如果再加10万美元的token预算,总包就是47.5万美元,其中21%是token。
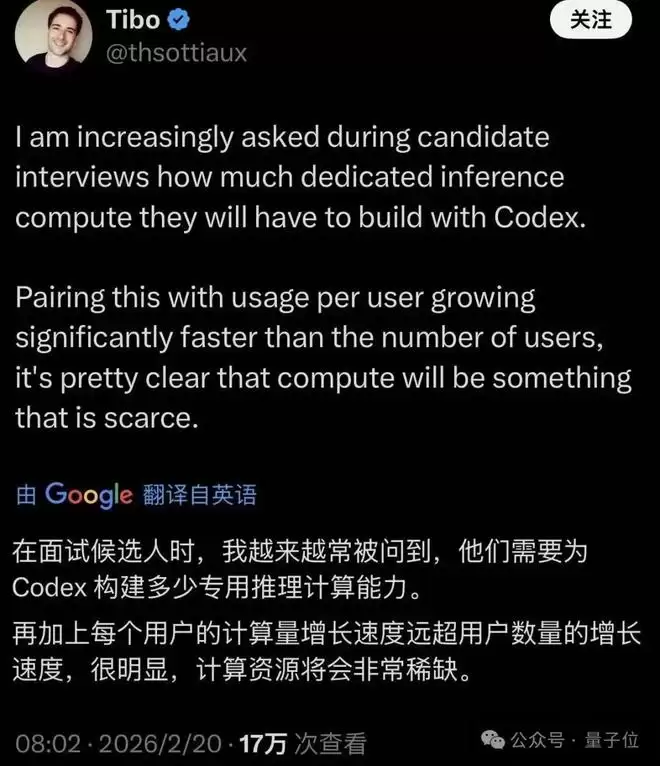
OpenAI Codex工程负责人Thibault Sottiaux最近在X上写道,AI算力正变得越来越稀缺、越来越值钱:
候选人面试时越来越多问我:我能有多少专属推理算力。
内卷还是生产力?
在OpenAI内部,员工已经可以在排行榜上看到同事消耗了多少token。
公司token预算正在成为一种员工福利,就像医疗保险或免费午餐。
另一面,Shopify和Meta已经把AI使用纳入了绩效考核,奖励重度使用的员工,批评不用的。
风险投资人Nikunj Kothari这样描述弥漫硅谷的新情绪Token焦虑。
晚饭时的开场白过去是“你在做什么?”现在变成了“你跑了几个agent?”
但质疑声音也在出现。一位匿名OpenAI员工评价同事们的token竞赛:这看起来不可持续。
排行榜不衡量产出质量。那些刷到数十亿token的人,到底在产出有用的东西,还是只是在空转、看起来很忙?
当一家公司为每个员工支付的Token费用接近甚至超过这个人的工资时,财务部门对“人头”的算法就会发生变化:
如果算力在干活,到底需要多少人来协调它?
参考链接:
[1]https://tomtunguz.com/inference-as-compensation/
[2]https://www.nytimes.com/2026/03/20/technology/tokenmaxxing-ai-agents.html
[3]https://www.wsj.com/tech/ai/claude-code-cursor-codex-vibe-coding-52750531

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

新加坡国立大学破解AI看图说话难题让机器描述更准确
人工智能的“幻觉”问题,特别是大模型在图像描述任务中凭空捏造内容的现象,一直是制约其可靠应用的关键挑战。2026年2月,一项由新加坡国立大学与北京大学深圳研究生院联合发布的突破性研究,为这一难题提供了全新的理解与一套高效、简洁的解决方案。这项研究(论文预印本编号:arXiv:2602 22144v1

斯坦福大学JavisDiT++实现AI有声有色视频生成
这项由浙江大学、新加坡国立大学、多伦多大学等全球顶尖科研机构联合完成的研究成果,已正式发表于2026年国际学习表征会议(ICLR 2026),论文预印本编号为arXiv:2602 19163v1。对于希望深入探究技术细节的读者,可通过此编号查阅完整的学术论文。 在浏览短视频时,你可能已经察觉到一种普

北大提出AI推理双车道方案解决大模型对话卡顿难题
这项由北京大学计算机学院主导,联合清华大学及DeepSeek-AI共同完成的前沿研究,其成果已正式发布于2026年2月的arXiv预印本平台,论文编号为arXiv:2602 21548v1。关注大语言模型推理优化的研究者与开发者,可通过此编号查阅论文全文与技术细节。 在与大语言模型进行深度、多轮对话

清华大学AI突破:赋予虚拟世界持久记忆,解决视频生成失忆难题
想象一下,你正在体验一款开放世界游戏。当你站在高塔之巅,远方的山脉清晰可见。随后你转身离开,去探索地图的其他角落。许久之后,当你再次回到这座塔顶,那座山依然以完全相同的姿态矗立在原地。这种空间持久且一致的认知,是人类理解世界的基础。 然而,若让当前的主流AI来动态生成这样的游戏场景,结果会大相径庭。

大模型压缩技术COMPOT让AI运行更高效
随着人工智能模型参数规模不断突破千亿级别,其庞大的存储需求和计算开销已成为实际部署的主要瓶颈。针对这一挑战,MWS AI基础研究中心与ITMO大学联合提出了一种名为COMPOT的创新模型压缩技术。这项发表于2026年2月预印本平台(arXiv:2602 15200v1)的研究,为大语言模型高效“瘦身








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
