




阿里千问发布全模态大模型 Qwen3.5-Omni,无缝理解文本、图片、音频及音视频输入

阿里千问重磅发布Qwen3.5-Omni:全能全模态大模型,解锁音视频实时交互新时代
2025年,阿里千问(通义千问)正式推出了其革命性的Qwen3.5-Omni全模态大型语言模型。此次发布标志着人工智能模型能力边界的重大突破,从传统的文本、图像处理,全面迈入了复杂的音频、视频理解与实时对话交互的新纪元。
Qwen3.5-Omni的核心技术亮点包括:
实现文本、图像、音频、视频的无缝融合理解与生成,支持带精准时间戳的音视频内容描述;
在涵盖音频、视频分析、推理、对话、翻译等领域的215项权威评测中斩获SOTA(业界最佳)成绩,综合表现超越Google Gemini 3.1 Pro;
具备自然涌现的音频-视觉氛围编程(Audio-Visual Vibe Coding)高级能力;
集成语义打断、个性化音色克隆与语音实时控制技术,打造接近真人的对话体验;
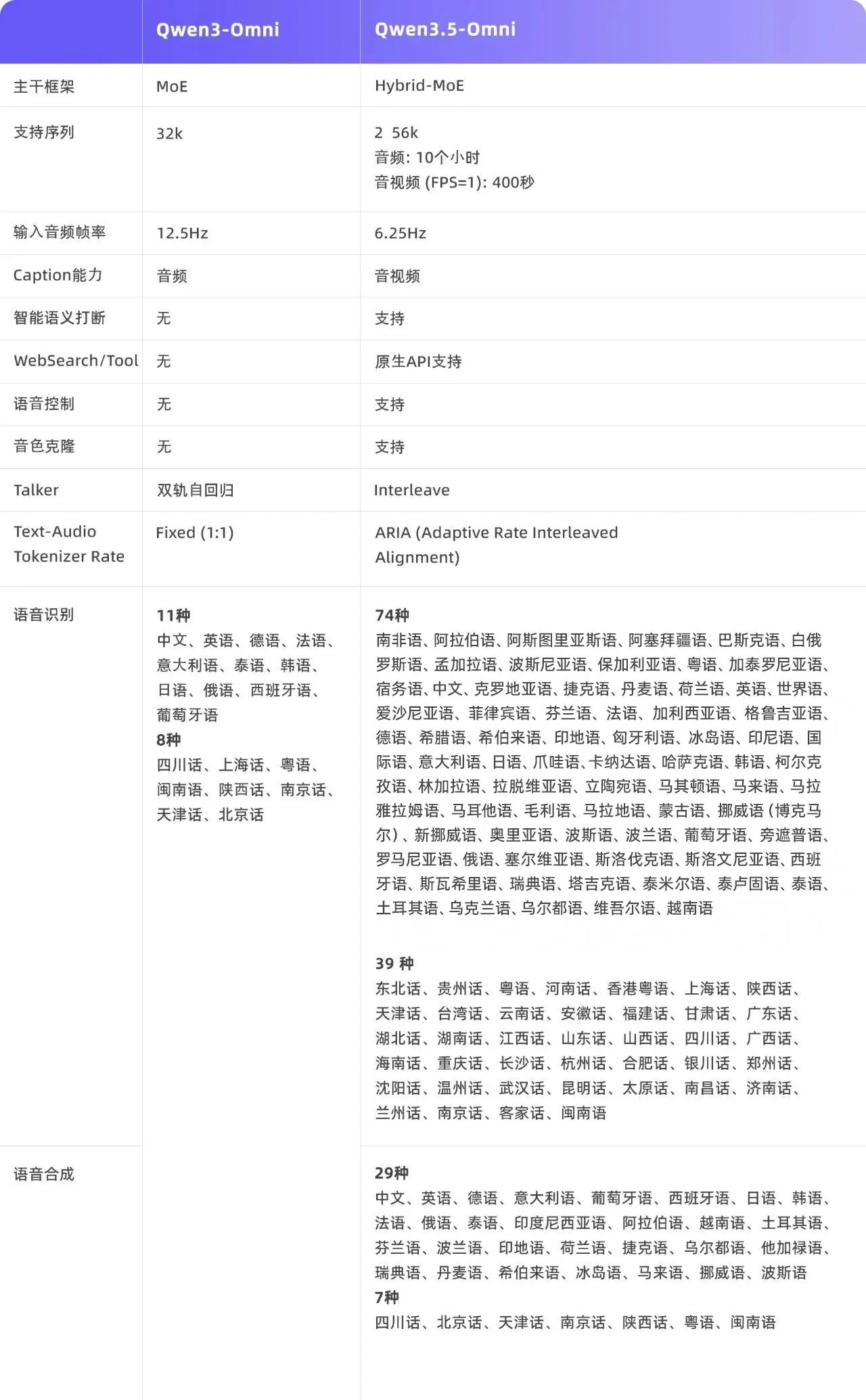
支持高达256K的超长上下文窗口,可精准识别113种语言,并能处理长达10小时的音频或1小时的视频内容。
原生集成联网搜索(WebSearch)与复杂函数调用(Function Call)功能,使其不仅能智能对话,更能化身为强大的AI助手,主动完成任务。
AI视频理解与智能剪辑
只需上传任意视频,Qwen3.5-Omni-Plus即可智能分析并生成精细的、带时间戳的结构化描述。它能准确识别画面人物、对话内容、背景音乐的变化节点、镜头切换次数以及每一场景的关键信息。该模型还能进行内容安全审查,并将冗长复杂的视频内容自动转化为清晰、可检索的结构化笔记,极大提升视频内容管理效率。
音视频指令驱动的内容生成
Qwen3.5-Omni可根据您的语音或视频指令,直接生成可执行的代码或网页前端原型。其中最引人注目的是其“氛围编程”能力——模型在未经针对性训练的情况下,能够理解画面逻辑并生成对应的Python代码或HTML/CSS/JavaScript代码,将创意构思到原型实现的路径大幅缩短,为AI编程和快速原型开发开辟了新可能。
拟人化实时语音对话交互
与Qwen3.5-Omni进行语音对话,体验无限接近真人交流。它具备精准的语义打断与连续聆听能力:能够有效过滤咳嗽、语气词等非意图性停顿,同时在您需要插话时能瞬间响应。您还可以通过“小声一点”、“用兴奋的语气说”等自然指令,实时调整AI的音量、语速和情感表达,获得高度定制化和人性化的交互体验。
个性化AI音色克隆定制
仅需提供一段简短的录音样本,即可克隆生成专属的个性化AI助手音色。克隆后的音色自然逼真、稳定性高,并支持多语言语音合成。这项功能让您能够打造一个拥有自己声音的“数字分身”AI伙伴,用于内容创作、智能陪伴或个性化服务,使每一次交互都更具亲切感和独特性。
智能联网搜索与任务自动化
Qwen3.5-Omni不仅是聊天伙伴,更是高效的智能执行体。当您提出复合需求,如“查询明天北京的天气并推荐附近的高评分餐厅”时,它能自动理解意图、调用联网搜索工具获取实时信息、整合数据,并最终提供一份完整的解决方案。其原生工具调用能力使其成为真正能“动手做事”的AI智能体。
总体而言,相较于前代模型,Qwen3.5-Omni在长文本处理、多语言支持以及核心的音视频理解与生成能力上实现了质的飞跃。新增的实时交互功能与ARIA语音合成技术的深度结合,使其语音输出的自然度和稳定性达到业界领先水平,推动了人机交互体验向“真人化”迈进。
在权威性能评估中,Qwen3.5-Omni-Plus版本在音频、视频的理解、推理及对话任务上,累计取得了215项SOTA最佳成绩,全面覆盖音视频内容理解、音频分析、多语种语音识别与翻译等关键维度。
具体数据显示,其在通用音频的理解、逻辑推理、识别、翻译及对话任务上,性能已全面超越作为行业标杆的Gemini-3.1 Pro模型,音视频综合理解能力与后者持平。同时,该模型在视觉与纯文本任务上的能力,与同系列顶级的Qwen3.5文本模型保持一致,确保了全模态能力的均衡与强大。
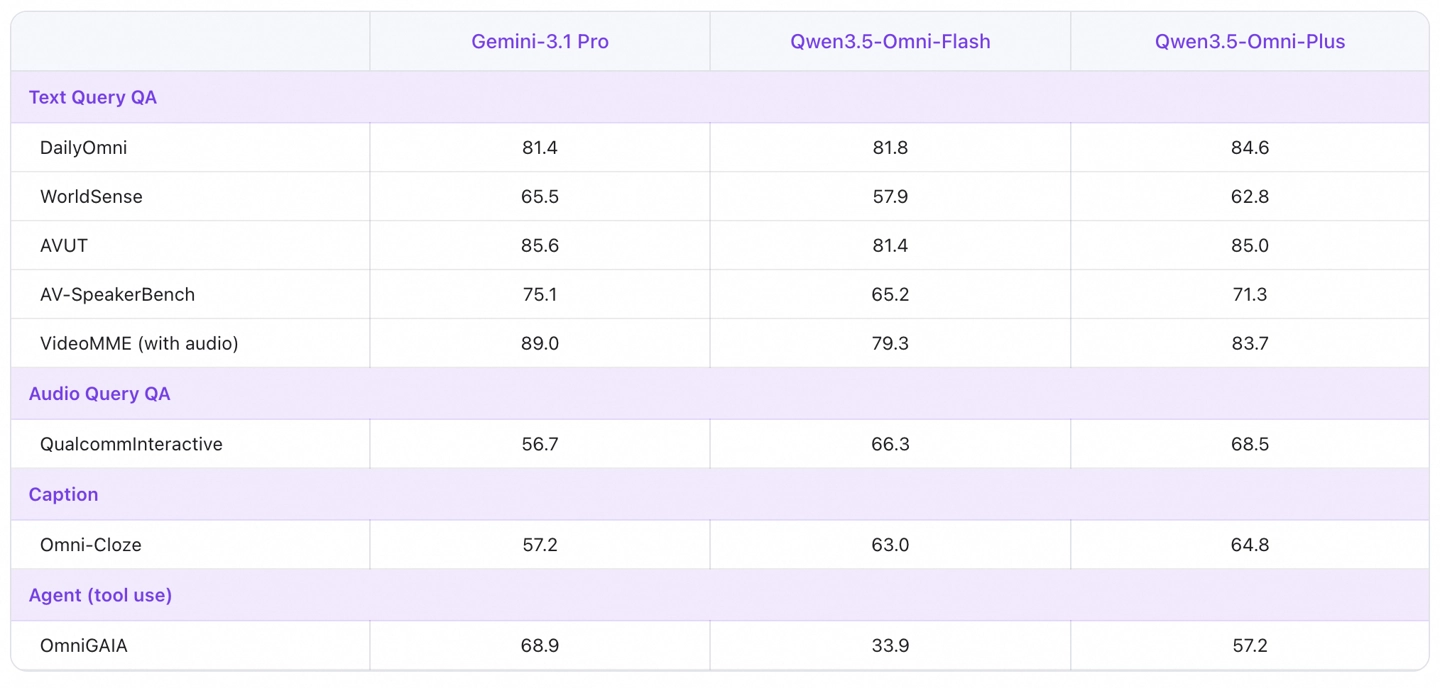
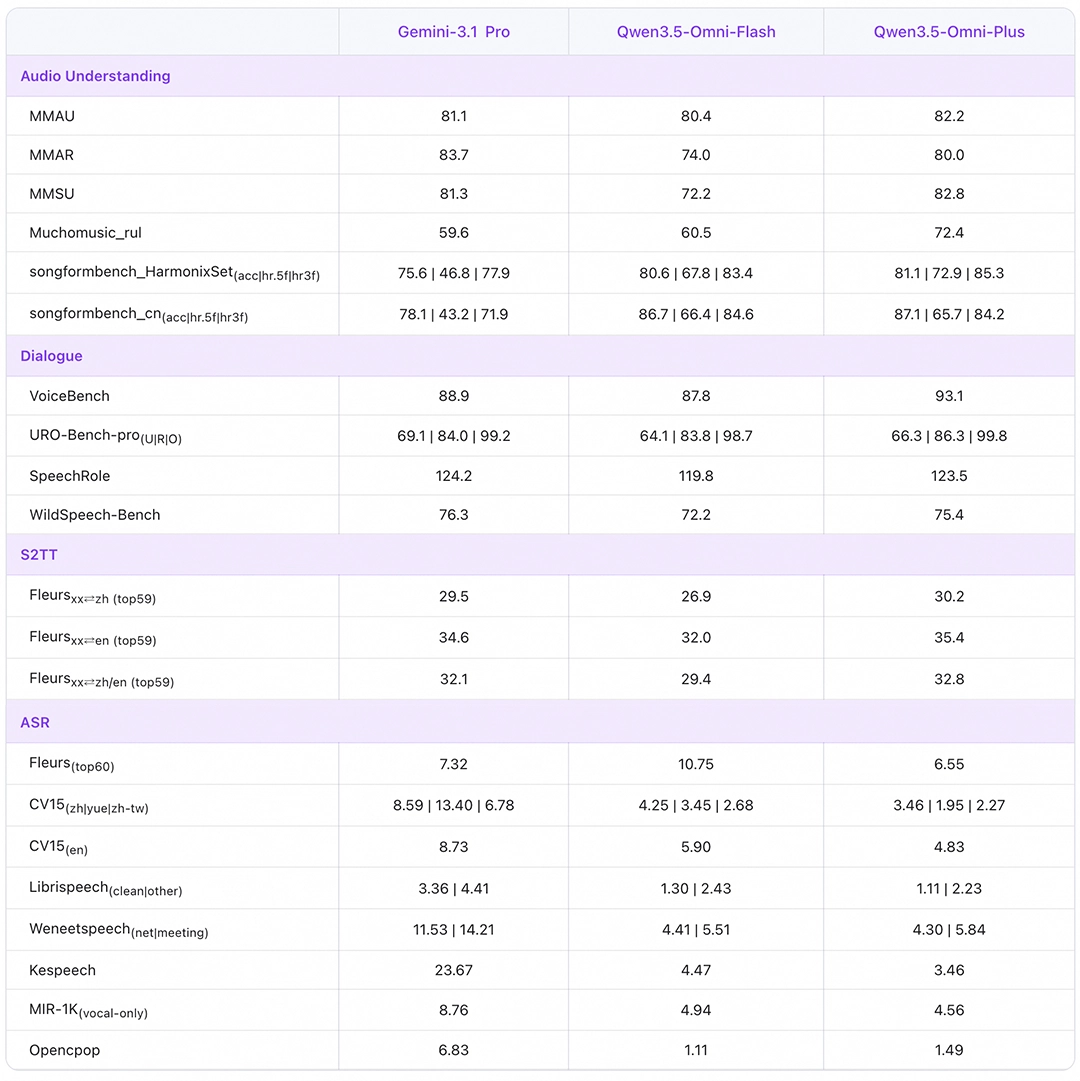
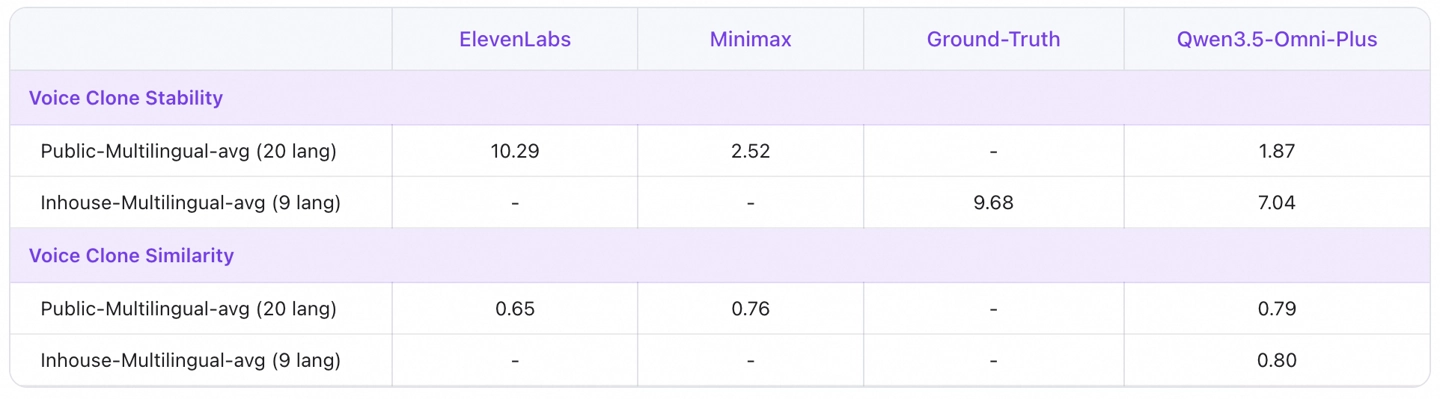
目前,开发者和企业用户已可通过阿里云百炼平台便捷地搜索并接入Qwen3.5-Omni的API服务。模型提供了Plus(高性能)、Flash(均衡高效)、Light(轻量快捷)三种不同规格版本,旨在灵活满足从复杂深度推理到高并发轻量级应用的全场景业务需求。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Anthropic封杀Claude用户事件解读 公司数据安全如何保障
周一清晨,一家拥有110名员工的农业科技公司,全体员工突然发现自己的Claude账户无法登录。这并非个别现象,而是全员遭遇。从Slack运维频道出现第一张截图开始,短短十分钟内,整个公司都在询问同一个问题:我的Claude出什么问题了? 答案很快揭晓——问题不在用户,而是Anthropic对所有账号

Agent技能安全检测框架SkillSieve的三层防护机制详解
在智能体(Agent)生态系统中,技能(Skill)正迅速演变为一个关键的安全攻击面。其根本原因在于:当前大量智能体依赖社区贡献的技能来扩展功能,而一个技能包通常不仅包含自然语言说明文档,还可能内嵌可执行脚本、依赖声明以及权限请求。它表面上看似一个简单的“功能插件”,但实际上可能获取智能体的核心执行

Unity张俊波:AI重塑智能座舱,3D交互如何打破应用功能边界
在北京车展的聚光灯下,汽车智能化转型的深度对话成为焦点。Unity中国首席执行官张俊波在专访中揭示了一条独特的技术演进路径。其最新发布的AI OS 3D空间交互系统,旨在从根本上重塑车内的人机交互范式。 该系统的核心理念,是通过先进的3D可视化技术,将分散于各个独立应用的功能,整合进一个统一的立体空

达摩院平扫CT肠癌无感检测模型全球首发登顶刊
在癌症早筛领域,一项突破性进展引发广泛关注。近日,欧洲肿瘤内科学会官方期刊《肿瘤学年鉴》正式发表了一项重要研究,该研究由阿里巴巴达摩院携手广东省人民医院等权威机构共同完成,其核心成果是一款名为DAMO COCA的结直肠癌AI筛查模型。这项研究的最大亮点在于,它首次在国际上实现了一种“无感化”筛查模式

酷态科与中电科机器人战略合作 首款原型机5月2日亮相
科技领域迎来重磅合作。4月28日,酷态科正式宣布与中电科机器人有限公司达成独家战略合作伙伴关系。此次合作是消费电子能源解决方案专家与特种机器人技术领军者的强强联合,双方将共同开拓极具前景的未来赛道——外骨骼机器人。 此次合作迅速引发行业关注,其亮点在于成果已迅速落地。官方信息显示,双方联合研发的外骨








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
