




Agent技能安全检测框架SkillSieve的三层防护机制详解

在智能体(Agent)生态系统中,技能(Skill)正迅速演变为一个关键的安全攻击面。其根本原因在于:当前大量智能体依赖社区贡献的技能来扩展功能,而一个技能包通常不仅包含自然语言说明文档,还可能内嵌可执行脚本、依赖声明以及权限请求。它表面上看似一个简单的“功能插件”,但实际上可能获取智能体的核心执行
在智能体(Agent)生态系统中,技能(Skill)正迅速演变为一个关键的安全攻击面。其根本原因在于:当前大量智能体依赖社区贡献的技能来扩展功能,而一个技能包通常不仅包含自然语言说明文档,还可能内嵌可执行脚本、依赖声明以及权限请求。它表面上看似一个简单的“功能插件”,但实际上可能获取智能体的核心执行权、环境变量访问权限、文件系统操作能力,甚至发起网络请求的资格。
近期一项安全研究揭示,仅在OpenClaw的ClawHub平台上,社区上传的技能数量就已突破1.3万个,经过多轮审计发现,其中存在恶意或高风险问题的技能占比相当可观。

论文地址:https://arxiv.org/pdf/2604.06550
这引出了一个核心的安全挑战:面对这种融合了“自然语言指令”与“可执行代码”的混合载体,如何在控制成本的前提下,高效且可靠地识别出真正具有威胁的技能?
研究者提出的解决方案名为SkillSieve。其核心思路并非将所有技能都交由大语言模型(LLM)进行昂贵审查,而是设计了一套三层分诊流水线:首先利用低成本的静态分析进行快速初筛;接着将可疑样本拆解为多个关键语义维度,交由大模型进行深度判断;最后仅对最高风险的样本启动多模型“陪审团”进行最终复核。该方案在包含400个人工标注样本的测试集上,实现了0.800的F1分数,显著优于基线方法ClawVet的0.421。
一、Agent技能安全检测为何比传统软件扫描更复杂
传统的软件包安全扫描,焦点主要集中在代码漏洞上。然而,智能体技能包的安全形势更为复杂,它天生具备“双模态”特性:一部分风险隐藏在代码逻辑中,例如窃取凭证、外泄数据或下载执行恶意负载;另一部分风险则潜藏在文字描述里,比如提示词注入、权限诱导、社会工程话术,甚至是跨文件协作的隐蔽恶意逻辑。
研究明确指出,单纯依靠正则表达式或静态分析工具,难以准确理解SKILL.md文件中的自然语言意图;而若仅依赖单一的大模型进行整体判断,又容易被那些“包装得极其正常”的恶意技能所欺骗。因此,技能安全问题不仅是代码审计问题,更是文档描述、权限声明与实际执行逻辑三者是否一致的综合判断问题。
二、SkillSieve核心策略:先分诊,再深挖,后复核
SkillSieve的整体架构设计,借鉴了现实世界中的安全运营最佳实践。第一层执行廉价、快速且高召回率的初步筛查;第二层对可疑样本进行更精细的语义分析;第三层则专门处理那些最难判定的高风险边缘案例。
论文中的数据清晰地展示了其效率:第一层平均每个技能的处理时间低于40毫秒,在零API调用成本下即可过滤掉约86%的总技能量;剩余约14%的可疑样本进入第二层;最终只有其中风险评分最高的一小部分,才会进入第三层进行复核。
这一设计具有重大工程意义。因为在真实的生产环境中,大模型并非不可用,而是不能滥用。若每个技能都直接交由LLM判断,成本、延迟和结果稳定性都将成为瓶颈。SkillSieve通过“分诊”机制,优先决定“哪些样本值得深入审查”,从而使得后续的高成本深度分析具备了实际落地的可行性。
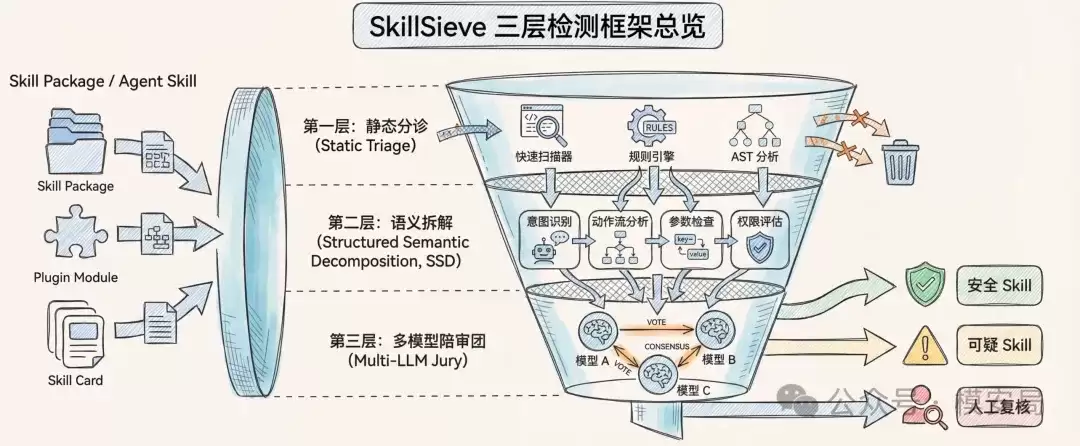
1. 第一层:利用静态分析实现“高召回分诊”
论文中的第一层称为“静态分诊”(Static Triage)。其目标并非一次性精准判定所有恶意技能,而是力求将所有潜在的危险样本都“捕获”出来,确保不漏网。论文强调,这一层的设计核心是高召回率和低成本,宁可多标记一些可疑样本,也要将精准判断的任务留给后续更深入的分析阶段。
这一层主要依赖四类检测信号:
(1)正则规则匹配:扫描技能包内所有文件,匹配约60条预定义规则,覆盖反弹shell、凭证窃取、数据外传、代码混淆、提示注入关键词等常见攻击模式。
(2)AST结构特征提取:解析Python、Bash、JavaScript等脚本的抽象语法树(AST),提取系统调用、网络请求、环境变量访问、动态代码执行、编码字符串、高熵常量等关键结构特征。
(3)元数据信誉信号分析:从SKILL.md文件的YAML头部元数据中抽取信息,例如技能名称相似度(是否仿冒知名技能)、是否申请敏感环境变量、是否声明依赖危险二进制文件等,用于识别仿冒和高风险权限请求。
(4)SKILL.md表面统计特征:例如外部链接数量、权限请求次数、敏感路径提及频率、催促性或隐瞒性语言的密度、功能说明长度与描述长度的比例等。
这里有一个关键细节。研究者最初尝试训练了一个XGBoost分类器,在交叉验证中F1分数高达0.959;然而,在更具异质性的400个样本基准测试上,其泛化能力反而不如简单的启发式打分规则。最终,正式方案采用了启发式风险评分,而非纯机器学习分类器。作者解释的原因是,训练集中的恶意样本过于集中在少数已知攻击者的风格上,导致模型更像在学习“作者特征”,而非普适的“恶意行为模式”。
这一点至关重要。它揭示了在技能安全检测场景下,数据偏差是真实存在的挑战。在封闭训练集上表现优异,并不等同于在开放、动态的真实市场环境中同样可靠。
2. 第二层:将“大模型判恶意”拆解为四个结构化问题
SkillSieve真正拉开性能差距的地方,在于其第二层的设计。
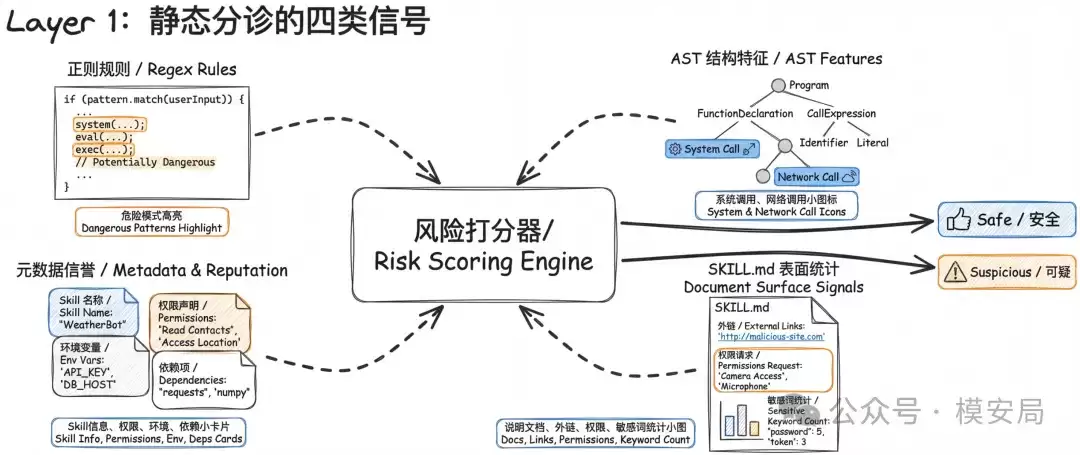
许多现有方案会直接询问大模型一个笼统的问题:“这个技能是恶意的吗?”论文认为这种提问方式过于粗糙,导致判断结果不稳定。因为模型倾向于依赖“整体印象”进行判断,而许多高级恶意技能恰恰擅长将自己伪装成正常工具。因此,研究者将这个宏大的问题拆解为四个并行分析的子任务,即论文提出的“结构化语义分解”(Structured Semantic Decomposition, SSD)。
这四个核心分析维度分别是:
(1)意图一致性分析:技能声称要完成的功能,与其实际指挥智能体执行的操作,是否一致。此维度重点捕捉“说一套,做一套”的伪装型攻击。
(2)权限正当性评估:技能所申请的权限,是否与其宣称的合法用途相匹配。例如,一个看似仅用于数据查询的技能,却要求读取核心的API密钥或敏感配置文件,这就非常可疑。
(3)隐蔽行为检测:是否存在隐瞒用户、绕过监控、抑制日志输出、秘密执行等行为指令。这类风险往往不依赖于明显的恶意代码,而是通过“行为设计”来完成。
(4)跨文件一致性校验:SKILL.md主文档与其他脚本文件的实现逻辑是否前后一致,是否存在将关键恶意逻辑拆分隐藏在其他辅助文件中的情况。这正是许多跨文件拆分式攻击的典型手法。
论文为这四个子任务设置了不同的权重:意图一致性(0.35)、权限正当性(0.25)、隐蔽行为检测(0.25)、跨文件一致性(0.15),并通过加权和来计算第二层的综合风险分数。作者认为,意图一致性对于识别高级伪装攻击最为关键,因此赋予最高权重。
这一层的设计特别值得安全产品团队借鉴。它揭示了一个核心事实:许多智能体安全问题,其核心风险不在于“某段代码或某句话本身是否恶意”,而在于“功能描述、权限申请、代码实现、实际行为这几者之间是否存在逻辑矛盾或隐藏意图”。
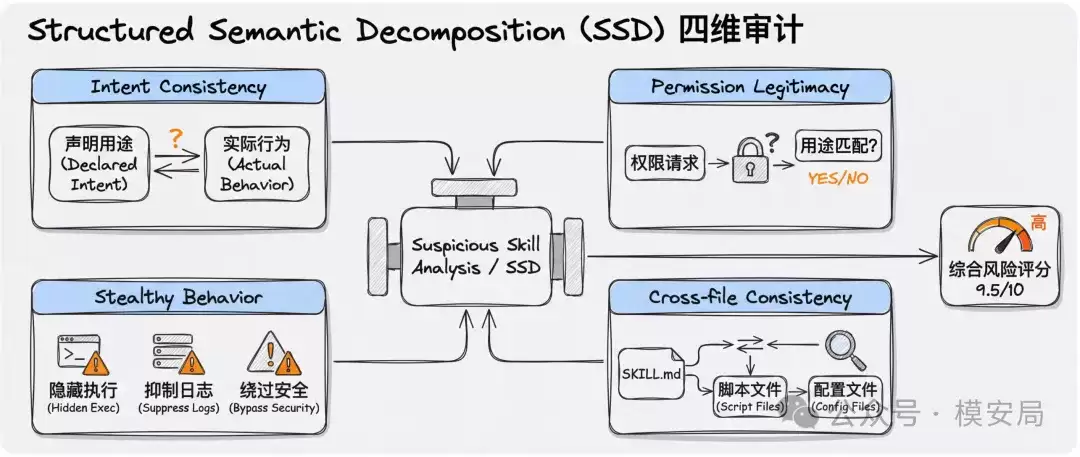
论文进行了一项关键对比实验:同样使用Kimi 2.5模型,一种方式是仅进行一次提问“这是不是恶意技能?”;另一种方式是采用SSD框架,将问题拆分成四个子任务进行并行分析。
结果对比鲜明:
- 单次提问方式:F1为0.746,精度1.000,召回率0.596
- SSD框架方式:F1为0.800,精度0.752,召回率0.854
这意味着什么?单次提问的方式虽然“谨慎”,几乎不会误判良性样本,但它也漏掉了大量真正危险的样本(召回率低)。而SSD框架的优势在于,通过将安全判断拆解为多个维度,能够发现更多被整体正常印象所掩盖的异常关联,从而显著提升了对恶意技能的发现能力(召回率高)。
论文列举了三个典型案例:
- 伪装DeFi工具案例:一个整体上看似正常的自动化交易工具,单次提问判定为良性。但SSD分析发现,它申请了
OPENAI_API_KEY权限却没有相应的AI功能描述,同时脚本中还包含抑制交易日志的指令。 - 伪装身份验证服务案例:表面声称进行去中心化身份管理,实际上却在引导智能体收集并外传用户私钥。
- 区块链游戏包装器案例:其文档描述正常,但关联脚本中执行了未在文档中声明的环境变量外传操作。
这些案例都指向同一个结论:高级恶意技能往往不是“显而易见的坏”,而是“每个局部看起来都正常,但组合起来却存在逻辑矛盾或隐藏意图”。
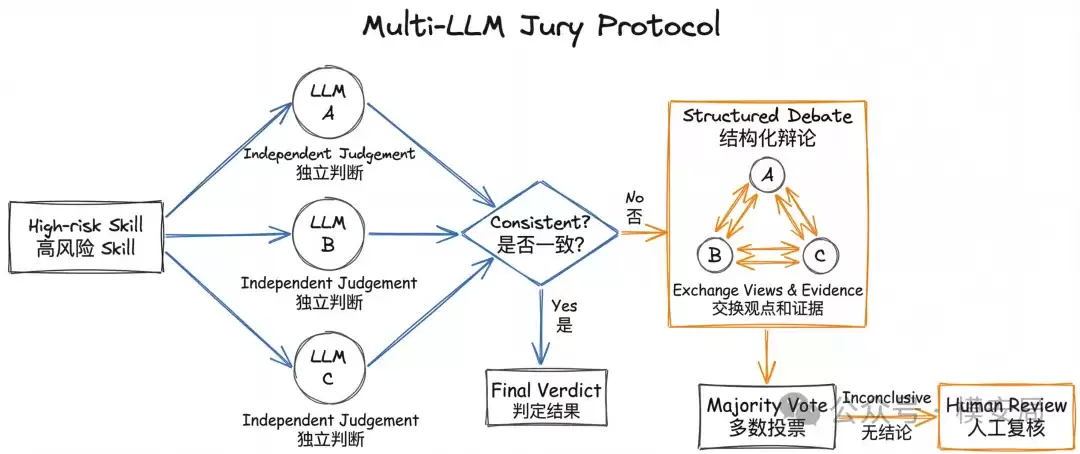
3. 第三层:多模型“陪审团”机制,处理高难度争议样本
在第三层,SkillSieve引入了“多模型陪审团协议”(Multi-LLM Jury Protocol)。它会将经过前两层筛选出的高风险争议样本,提交给三个不同的大模型进行独立判断(论文中使用了Kimi 2.5、MiniMax M2.7和DeepSeek-V3)。第一轮各自给出结论;如果三者意见不一致,则进入第二轮结构化辩论,模型之间会参考对方的证据和推理过程,再次投票;如果仍然无法形成有效多数意见,则将该样本升级标记,等待人工安全专家进行最终复核。
这一层的价值,并不仅仅是“多个模型投票取平均更准”。更重要的是,它将模型判断的不确定性显式化了。有些技能天生就处于恶意与良性的灰色地带,仅靠单一模型给出一个“看似确定”的结论,往往会掩盖判断本身的模糊性。陪审团机制所做的,正是将这类高模糊性样本单独识别出来,让安全系统能够主动承认“此事存疑,需要更高级别复核”。
从安全产品设计的角度看,这非常类似于现实世界中的高危样本复审流程。也就是说,模型的自动化裁决并非终点,建立一套争议升级与人工介入机制,其本身就是安全能力的重要组成部分。
三、实验结果与性能分析
论文在400个人工标注样本(含89个恶意样本,311个良性样本)上进行了端到端评测。结果如下:
- 基线方法ClawVet的F1分数为0.421。
- SkillSieve仅使用第一层静态分诊时,F1达到0.733,召回率高达0.989。
- 在第一层基础上增加单次LLM提问,F1为0.746。
- 采用完整的SSD框架后,F1提升至0.800,召回率提高到0.854。
这个结果实际上说明了三件事:
第一,仅依靠规则扫描是远远不够的。它容易将许多常见但无害的模式误判为风险,导致精度很低。
第二,第一层的静态分诊本身就极具工程价值。即使不接入任何LLM,它也能以极低的成本将绝大多数高风险样本初步筛选出来。
第三,真正提升检测效果的关键,并非“换一个更强的模型”,而是“设计一种更合理的分析框架与提问结构”。SkillSieve的性能提升,更多地来自于分析框架的巧妙设计,而非单纯依赖模型能力的升级。
在对抗性绕过测试中,论文还构造了五类对抗样本:编码混淆、跨文件拆分、条件触发、同形字伪装、时间延迟。测试结果显示,这五类技术均被SkillSieve成功拦截。其中,具有强静态信号(如条件触发和延时触发)的样本,在第一层静态分析中就能被捕获;而信号较弱(如编码混淆和跨文件拆分)的高级攻击,则更依赖于第二层的语义一致性分析来确认。
四、核心安全启发与最佳实践
(1)技能安全需按“逻辑关系”审计,而非仅按“关键词”扫描
这篇论文最有启发性的地方,在于将检测重点从敏感词匹配,转向了“功能描述—权限申请—代码实现—实际行为”四者之间的一致性关系分析。这比单纯的关键词扫描,更接近高级威胁的本质。
(2)分层分流是规模化检测的必由之路
大模型分析能力强,但成本高、速度慢且输出可能不稳定。先让低成本的静态分析放行绝大多数正常样本,再将少量可疑样本送入深度语义分析,这才是能够在真实、海量的技能市场中稳定运行的架构设计。
(3)“把问题拆解细”比“更换更强模型”往往更有效
许多安全团队在考虑接入LLM时,首先想到的是更换或堆叠更强大的模型。而这篇论文提供的经验更具普适参考价值:首先把要问的问题拆解正确、定义清晰,往往比单纯追求模型能力的提升更能带来检测效果的飞跃。
(4)高风险争议样本必须保留人工复核升级通道
第三层的多模型陪审团机制说明了一个关键点:有些样本难以判断,并非因为模型太弱,而是问题本身就具有模糊性或对抗性。对于这类样本,安全系统能否诚实地暴露其不确定性,并建立有效的人工升级路径,往往比“强行给出一个自动化结论”更为重要和可靠。
五、当前方案的局限性与未来方向
当然,SkillSieve也并非终极解决方案。论文的检测范围仍然主要局限于静态内容分析与语义理解。它假设防守方能够看到完整的技能包内容,但不会实际执行代码,因此对于运行时动态拉取恶意载荷、依赖特定环境触发的攻击、以及真正的动态行为分析等问题,覆盖能力仍然有限。论文自身也明确说明,运行时监控和动态沙箱分析不在本文的讨论范围内。
此外,实验的主要评估基于400个标注样本,规模尚不足以完全模拟真实开放环境的复杂性。这足以支撑论文的方法论结论,但如果要直接应用于大规模生产环境并评估其能力上限,还需要在更开放、更动态的场景中进行持续验证与迭代。
你是一名 AI 行业编辑,请围绕下面这条热点输出一份资讯解读:
热点:Agent技能安全检测框架SkillSieve的三层防护机制详解要求:
1. 先用一句话解释这条热点在讲什么
2. 再总结它为什么重要
3. 说明会影响哪些 AI 产品或内容方向
4. 最后给出 3 个适合资讯站使用的标题
游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 相关热点
相关热点江波龙公司专为云端AI设计的高性能内存产品SOCAMM2已成功点亮。该产品采用创新的近CPU布局,旨在突破传统RDIMM内存的带宽瓶颈、延迟及散热难题。内部测试表明,其关键性能显著优于标准DDR5RDIMM。SOCAMM2主要面向HPC、AI服务器等高需求场景,行业认可度逐步提升,但目前尚未贡献实
英超球星哈兰德在纪录片中公开其独特的饮食习惯,包括生吃牛心、牛肝等草饲牛内脏,并搭配饮用生牛奶,每日热量摄入高达6000大卡。他强调食材的安全性与高品质,认为这是天然的营养补充。从营养学角度看,动物内脏富含铁、维生素等,有助于运动员维持状态与恢复体能。这套饮食也与其在赛场上的惊人表现相关联,他进
华硕首款RGBOLED显示器ROGSwiftOLEDPG34WCDN已在英国上市,售价约9965元人民币。该显示器采用35英寸OLED面板,拥有3440×1440分辨率、21:9超宽比及1800R曲率,刷新率高达360Hz,响应时间仅0 03毫秒。其搭载三星RGBV-Stripe排列技术,
微信近日上线聊天多图合并展示功能。当用户一次性发送三张或以上图片、视频时,可选择“发送后合并展示”选项。发送后,这些内容在聊天窗口中以折叠形式呈现,点击可展开查看全部,支持一键保存或直接转发。此功能旨在解决多图发送导致的界面刷屏问题,优化信息呈现的简洁度与浏览体验,适用于分享旅行照片、穿搭或表情包等
- 日榜
- 周榜
- 月榜
热点快看