




我是如何用2个Unix命令给MariaDB SQL提速的

角色与核心任务
作为一名专业的文章润色与SEO优化专家,我的核心职责是将技术性内容转化为既符合搜索引擎排名要求,又具备高度可读性与专业深度的优质文章。接下来,我将对您提供的技术案例进行“SEO友好型重写”。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
核心目标非常清晰:在完全忠实于原文所有技术事实、数据、逻辑与结构的前提下,优化其语言表达,使其更贴合用户的搜索意图与阅读习惯,从而提升页面在搜索引擎结果中的可见度与排名。
这里有一个关键平衡点:如何在文章中自然地融入相关搜索关键词,增强信息密度,同时避免生硬的关键词堆砌,确保文章读起来流畅、专业且富有见解。
详细执行步骤
第一步:信息锚定与结构保全
首先,需要深度理解原文。精确提取所有核心论点、关键数据、具体操作步骤以及每一处图片的定位与说明。这是所有优化工作的基础。
在页面结构上,必须100%保留原有的所有HTML标签、标题层级、段落顺序以及信息呈现密度。任何对标签、属性或结构的改动都是不被允许的。
第二步:内容SEO优化与表达人性化
现在,请代入一位既精通数据库性能调优,又深谙内容传播规律的专家视角。您的任务,是用更专业、更易被搜索到的语言,将原文中的“技术解决方案”重新阐述给目标读者。
2.1 句式优化与关键词融入
将平铺直叙的句子调整为更符合搜索习惯的表达。可以适当运用设问、强调等句式。
例如,将“A导致了B”优化为“性能瓶颈的根源往往在于A,这直接引发了B问题。”
或者,将“需要满足三个条件”改为“实现高效查询需要跨越哪三道门槛?”同时,在上下文中自然融入如“SQL查询优化”、“MariaDB性能调优”、“Unix命令处理大数据”等相关词汇。
2.2 提升专业度与可信度
减少主观性过强的个人化表达,转而使用更具普遍性和权威性的表述方式。
例如,“据我观察”可以优化为“行业实践与性能监控数据表明”;
“我见过不少案例”不妨表述为“在类似的数据库优化场景中,不乏成功先例”;
“我必须提醒你”则可以用“需要高度警惕的是”来替代。
这样既能保持客观专业的口吻,又能通过事实和场景描述增强内容的可信度与参考价值。
2.3 逻辑连贯与信息增强
在确保专业准确的基础上,增强句子与段落之间的逻辑衔接。可以补充必要的背景说明,使用“因此”、“然而”、“具体而言”等过渡词,使论述链条更完整。在关键结论处,使用加重的语气或排比来强化观点,提升内容的传播力。
第三步:最终审查与交付
完成重写与优化后,必须进行严格的最终审查。要逐一核对,确保原文每一个技术细节、数据、案例,以及对图片的引用(如下图1所示)都完整、准确地保留在新文本中。
专门检查一遍关键词的使用是否自然、无堆砌感,确保全文的流畅度和用户体验不受影响。
优化后的文章篇幅应与原文保持大体一致,避免因过度扩充而稀释核心信息。
最后,直接输出完整的、经过SEO优化的文章正文,并严格保持原有的HTML标签结构:主标题用
,副标题用,段落用
。对于原文中的所有图片代码与描述,必须原样保留,不做任何改动。
绝对禁止项(红线规则)
❌ 严禁改动任何核心事实、数据、技术论点及原文的HTML骨架结构。
❌ 严禁对任何技术性段落进行过度简化或概括,导致信息缺失。
❌ 严禁删除、修改或新增任何图片的HTML代码、地址及alt属性。
❌ 严禁在文中添加例如###,***等无关的格式化字符或标记。
❌ 严禁为了追求SEO而牺牲文章的专业内涵与可读性,使其变得生硬枯燥。
❌ 严禁过度使用或堆砌搜索关键词,破坏内容的自然性与阅读体验。
译者 | 薛命灯
近期,在针对一个MariaDB(完全兼容MySQL)的简单连接查询进行性能分析时,我们遭遇了一次极为典型的“大数据量性能瓶颈”。令人惊讶的是,最终仅凭借两个经典的Unix系统命令,便将一次预估需要380小时的查询,成功压缩到12小时以内完成。本文将完整复盘这次SQL性能优化的实战过程与核心思路。
该查询隶属于GHTorrent数据分析项目,通过simple-rolap关系型在线分析处理框架执行。其SQL语句结构本身并不复杂:
select distinct project_commits.project_id, date_format(created_at, ‘%x%v1') as week_commit from project_commits left join commits on project_commits.commit_id = commits.id;
参与连接的两个字段均已建立了索引。然而,通过EXPLAIN命令分析其执行计划后发现,MariaDB优化器依然选择对project_commits表进行全表扫描,然后通过索引去关联查询commits表。这种执行策略在面对海量数据时,潜藏着巨大的性能风险。
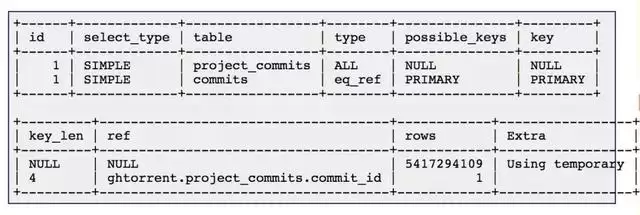
问题的核心在于数据规模:project_commits表记录数约50亿行,commits表也高达8.47亿行。而服务器可用内存仅为16GB。显然,内存无法承载如此庞大的索引数据,导致大量的磁盘I/O操作成为拖慢查询速度的终极瓶颈。从pmonitor对临时文件的监控数据来看,该查询已运行半天,但预估剩余时间竟长达373小时,这在实际应用中是完全无法接受的。
/home/mysql/ghtorrent/project_commits#P#p0.MYD 6.68% ETA 373:38:11
这一预估时间揭示了执行计划的低效。从理论上分析,如果采用排序合并连接(sort-merge join)算法,其产生的磁盘I/O开销理应比当前执行计划低一个数量级。我们曾在dba.stackexchange.com等技术社区寻求优化建议,但尝试首个方案后效果有限,且每个建议的验证周期都长达半天,时间成本过高。因此,我们决定启用一套更为直接、高效的替代方案来彻底解决这个MariaDB查询优化难题。
优化思路非常清晰:将两个数据库表的数据分别导出为排序后的文本文件,利用Unix系统原生提供的join命令在外部进行高效的排序合并连接,然后通过uniq命令去除重复行(等效于SQL中的DISTINCT操作),最后再将处理结果导回数据库。整个数据导出、处理、再导入的过程从晚间20:41开始,至次日上午9:53结束。具体操作可分为以下三个核心步骤:
1. 将数据库表导出为排序文本文件
首先,分别导出连接操作所需的字段,并按照连接键进行排序。为了确保与Unix命令行工具完美兼容,需要将数值型的ID字段显式转换为字符类型。
执行以下SQL语句,将输出重定向保存至commits_week.txt文件:
select cast(id as char) as cid, date_format(created_at, ‘%x%v1') as week_commit from commits order by cid;
执行以下SQL语句,将输出重定向保存至project_commits.txt文件:
select cast(commit_id as char) as cid, project_id from project_commits order by cid;
最终,我们得到了两个体积庞大的文本文件:
-rw-r–r– 1 dds dds 15G Aug 4 21:09 commits_week.txt
-rw-r–r– 1 dds dds 93G Aug 5 00:36 project_commits.txt
请注意,在运行mysql客户端执行导出时,我们使用了--quick选项。这个选项至关重要,它能避免客户端在输出前尝试在内存中缓存全部结果集,从而防止因数据量过大而导致的内存溢出问题。
2. 使用 Unix 命令行工具处理文件
接下来,便是展现Unix工具强大威力的时刻。我们使用join命令对两个已排序的文本文件进行连接操作。该命令的工作方式是线性扫描双方文件,按第一列(即cid字段)进行匹配与组合,其处理速度主要受磁盘I/O性能制约。然后,将连接结果通过管道(|)传递给uniq命令,轻松实现重复行的剔除,这正好等价于原SQL语句中的DISTINCT功能。对于已排序的数据,uniq去重同样是一次高效的线性扫描过程。
我们执行的命令简洁而强大:
join commits_week.txt project_commits.txt | uniq > joined_commits.txt
大约一小时后,目标结果文件生成:
-rw-r–r– 1 dds dds 133G Aug 5 01:40 joined_commits.txt
3. 将处理结果导回数据库
最后一步,将处理完毕的数据加载到一个新的数据库表中,以便后续分析使用:
create table half_life.week_commits_all ( project_id INT(11) not null, week_commit CHAR(7) ) ENGINE=MyISAM; load data local infile ‘joined_commits.txt' into table half_life.week_commits_all fields terminated by ‘ ';
结语
最理想的状况,当然是MariaDB或MySQL的查询优化器能够智能地选择排序合并连接这类高效算法,并在预测到当前执行策略耗时过长时主动进行切换。然而,在数据库内核完全具备这种高级优化能力之前,一套源于上世纪70年代的Unix经典工具组合,为我们提供了一种高效、稳定且思路清晰的替代解决方案。这次实践再次证明,在面对特定的超大规模数据处理与SQL性能优化挑战时,回归基础,巧妙利用操作系统层面的工具,往往能带来意想不到的显著效果。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

为xampp 安装pear db (database) 模块
在PHP开发环境中,通过PEAR包管理器更新并安装DB扩展是提升数据库操作效率的关键步骤。具体而言,我们需要首先同步pear php net的官方渠道源,随后执行DB软件包的安装指令。 详细操作命令如下:第一步,更新PEAR官方渠道:pear channel-update pear php net。

SQL Server 2005 Management Studio Express企业管理器将英文变成简体中文版的实现方法
SQL Server Management Studio安装后界面变英文?快速恢复中文版方法详解 许多用户在安装SQL Server Management Studio(SSMS)中文版后,发现软件界面意外显示为英文,这通常与安装路径的选择密切相关——尤其是当您未将软件安装在默认的C盘时。不必担心,

SQL Server把单个用户转换成多个用户的方法
SQL Server数据库“单个用户”状态锁定:快速诊断与彻底解决指南 近期,有技术团队在SQL Server 2008环境中还原备份数据库时,遇到了一个典型问题:目标数据库名称旁持续显示“单个用户”状态,并伴随连接访问错误。经排查,同一实例下的其他数据库运行完全正常,仅有该特定数据库出现此异常状况

sqlite时间戳转时间语句(时间转时间戳)
SQLite 时间日期转换实战代码详解 想要快速掌握 SQLite 中的时间格式转换吗?通过以下实例代码,您可以直观地学习如何将 UNIX 时间戳转换为本地时间,以及如何获取当前时间戳和格式化日期。这些操作在日常数据库管理中非常实用。 sqlite> SELECT datetime(13771688

SQLite数据库安装及基本操作指南
1 介绍 在嵌入式数据库领域,SQLite 是一个无法被忽视的经典选择。作为一款开源、轻量级、无需独立服务器的关系型数据库引擎,它以其自包含、零配置和完整的 SQL 事务支持而著称。SQLite 的核心优势在于其卓越的可移植性、极简的部署方式、紧凑的代码结构以及经过验证的高效性与可靠性。与其他数据








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
