




OmniShow – 字节联合港中文、港大等开源的视频生成模型

OmniShow是什么
视频生成领域近期迎来了一项重大突破——OmniShow。这款由字节跳动携手香港中文大学、莫纳什大学及香港大学共同开源的多模态人-物交互视频生成模型,堪称“全能型选手”。其核心能力在于,能够将静态图片转化为动态视频,并精准响应多种模态的指令控制。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
该模型之所以引发业界广泛关注,在于其实现了RAP2V(参考图+音频+姿势到视频)端到端生成框架的首次完整落地。这意味着,文本、图像、音频、姿势这四种输入条件能够被模型统一理解与处理。尤为值得一提的是,仅凭一个约123亿参数的模型,它便能稳定生成长达10秒的高质量视频。其背后采用的门控局部上下文注意力等创新技术,有效保障了音视频的精确同步。在权威的HOIVG-Bench基准测试中,OmniShow已在多项核心任务上取得了最优成绩。
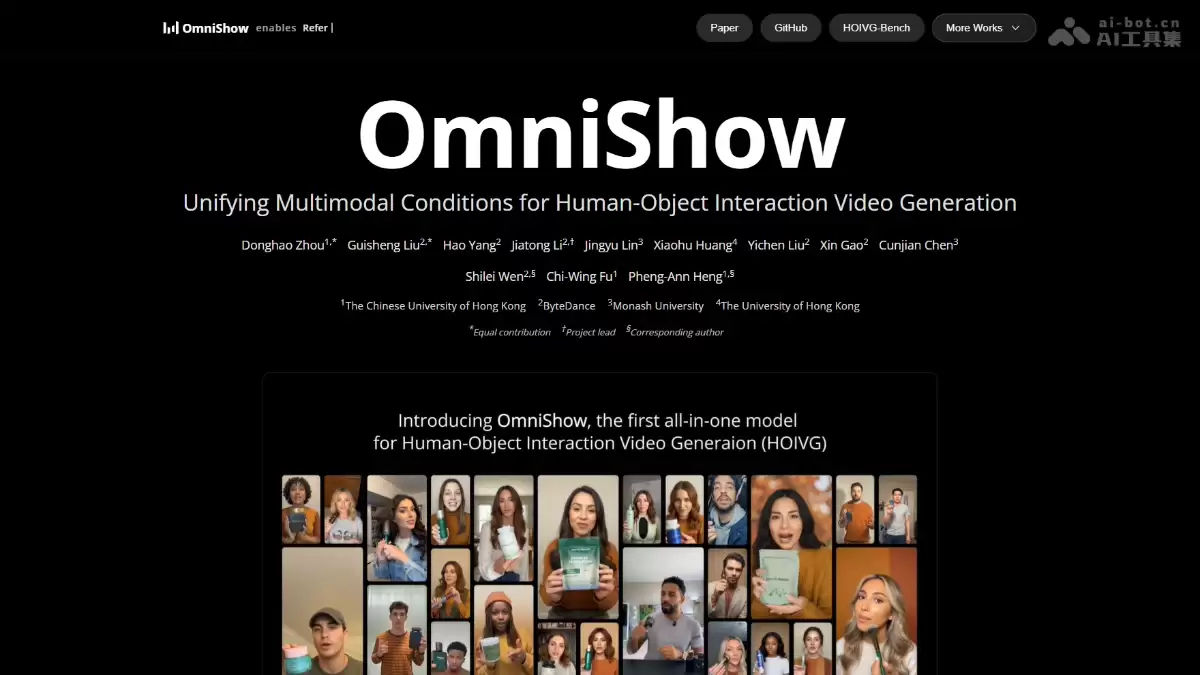
OmniShow的主要功能
那么,这款“全能模型”具体能实现哪些功能?其核心能力可归纳为以下四个方面:
全模态条件输入:这是OmniShow的基石。作为首个完整的RAP2V框架,它能够同时接收并融合四种模态的输入:参考图像(定义人物或物体的外观)、驱动音频(控制语音或音效)、姿势信号(指导肢体动作轨迹)以及文本描述(提供场景上下文)。这为创作者提供了一套完整的“控制面板”,实现了对生成视频内容的全方位精确把控。
多任务统一生成:一个模型,覆盖多种视频生成任务。通过灵活组合不同的输入条件,OmniShow在单一架构内即可胜任:仅凭参考图生成视频(R2V)、用音频驱动数字人说话(RA2V)、用姿势序列驱动动画(RP2V),以及最全面的全模态精确控制(RAP2V)。用户无需在不同工具间切换,极大提升了创作效率。
高质量长视频合成:生成长视频并保持时序一致性一直是技术难点。OmniShow原生支持一次性生成长达10秒的连续视频,在确保角色外观稳定不“崩坏”的同时,实现了口型、表情和肢体动作与音频节奏的高度同步,输出画质达到了可直接应用于商业场景的水准。
物体替换与视频混剪:这项功能为创意编辑开辟了新路径。你可以在保留人物优美舞姿的前提下,轻松替换她手中的道具;或者从A视频提取姿势、从B视频提取物体、从C图片提取人物参考,重新组合成一个全新的创意视频。这种强大的灵活性,显著降低了专业级视频合成的技术门槛。
OmniShow的技术原理
支撑如此强大功能的,是三项关键的技术创新:
统一通道条件注入:如何将多种控制信号高效、无干扰地输入模型?OmniShow采用了一种巧妙的方案:直接在通道维度将参考图像和姿势信号拼接,然后注入预训练好的视频生成基础模型。这种方法的最大优势在于,它在引入精确的外观和动作控制时,最大程度地保留并利用了基础模型原有的高质量生成能力,避免了底层能力的破坏。
门控局部上下文注意力:音视频不同步是视频生成领域的常见难题。OmniShow的解决方案是引入一个可学习的“门控”向量,配合掩码注意力机制。这相当于为模型配备了一个智能调度器,使其能动态判断音频特征应重点影响面部的嘴部区域,还是身体的肢体动作区域,从而实现了像素级的同步精度,有效解决了多模态特征融合时的冲突与干扰问题。
解耦-联合训练策略:针对不同任务训练数据不均衡的问题,OmniShow采用了两阶段训练策略:首先,为R2V(图生视频)和A2V(音频生视频)等子任务分别训练专用模型,打好各自的“基本功”;然后,通过权重插值技术将这些子模型融合,再在混合数据上进行联合微调。这套方法高效整合了异构数据集,使得模型在面对全模态输入时,依然能保持出色的生成一致性与鲁棒性。
如何使用OmniShow
对于开发者和研究人员,上手使用OmniShow的流程相当清晰:
获取开源代码:首先,访问项目官方GitHub仓库,将代码克隆至本地开发环境。随后,请仔细阅读README文档,并按照指引完成所有必要的依赖库和环境配置。
准备多模态输入:根据您希望完成的具体视频生成任务,准备好相应的素材。这可能包括:定义主体外观的参考图像、作为驱动源的音频文件、描述动作序列的姿势数据,以及补充场景信息的文本描述。
执行视频生成:最后,调用模型提供的API接口或运行指定的推理脚本,将组合好的多模态条件输入模型。经过短暂的计算,一段最长10秒的高质量人-物交互视频便会生成,您只需保存输出结果即可。
OmniShow的关键信息和使用要求
在深入应用之前,有必要了解该项目的几个关键事实:
项目定位:这是一个由字节跳动与三所顶尖高校联合推出的行业级开源模型,旨在为复杂的人与物体互动场景提供一套完整、统一的视频生成解决方案。
技术规模:模型参数量为123亿(12.3B)。这一规模在同类模型中展现出极高的效率,例如,它小于HuMo-17B(170亿)和Phantom-14B(140亿),却在多项性能指标上实现领先,意味着其对计算资源的需求更为友好,部署成本更低。
核心能力:其最显著的标签是“首个完整支持RAP2V的端到端统一框架”。它能够同时接收并联合处理参考图像、音频、姿势序列和文本描述这四种模态的输入信号,实现真正的多模态可控生成。
生成质量:模型原生支持生成10秒连续视频,并通过创新的门控注意力机制,确保口型、表情、动作与音频的同步精度达到行业领先标准,视频观感流畅自然。
性能表现:在自建的HOIVG-Bench综合测试中,OmniShow在R2V、RA2V、RP2V及RAP2V四项核心任务上均取得了当前最优(SOTA)结果,是目前唯一能胜任全模态输入的领先方案,综合性能突出。
OmniShow的核心优势
综合来看,OmniShow的竞争力主要体现在以下几个维度:
全模态统一架构:这是其最大的差异化优势。一个端到端框架原生支持四种模态的任意组合输入,用户无需像“搭积木”一样拼接多个专用模型,简化了工作流程,也提升了复杂任务下多条件协同控制的效率与效果。
极致参数效率:以更少的参数实现了更强的性能。12.3B的模型规模在多项任务上击败了参数更大的竞争对手,这直接转化为更低的推理成本和更快的生成速度,对于实际商业部署和广泛应用非常有利。
单一模型多任务覆盖:“一专多能”的特性显著降低了使用门槛。无论是制作数字人播报、驱动姿势动画,还是进行全模态控制的创意视频生成,都无需切换不同模型,保证了创作流程的连贯性与灵活性。
音视频精确同步:同步效果是数字人生成真实感的生命线。其创新的注意力机制在Sync-C指标上达到了8.612的高分,确保了口型与语音的高度吻合,这是提升视频观感真实性的关键所在。
长视频原生生成:不同于需要滑动窗口拼接的生成方式,它能一次性输出长达10秒的连贯视频。这不仅保证了时间线上的动作流畅度,也更好地维持了角色外观、光照和场景背景的一致性。
OmniShow的项目地址
对OmniShow感兴趣,希望深入了解或亲自尝试的读者,可以通过以下官方渠道获取资源:
项目官网:https://correr-zhou.github.io/OmniShow/ 这里通常包含了技术论文、演示视频、案例展示和最新项目动态。
GitHub仓库:https://github.com/Correr-Zhou/OmniShow 所有开源代码、预训练模型权重及详细的使用说明文档均在此处提供。
OmniShow的同类竞品对比
| 对比维度 | OmniShow | HuMo-17B | Phantom-14B |
|---|---|---|---|
| 参数规模 | 12.3B(最轻量) | 17B(+38%) | 14B(+14%) |
| 支持任务 | R2V / RA2V / RP2V / RAP2V(全模态) | R2V / RA2V(无姿势) | 仅 R2V(无音频/姿势) |
| 架构特点 | 端到端统一框架,单模型多任务 | 专用人-物交互模型,需配合其他工具 | 基础参考图生成模型 |
| R2V 质量(NexusScore) | 0.389(SOTA) | 0.346(低 11%) | 0.366(低 6%) |
| RA2V 同步(Sync-C) | 8.612(SOTA) | 8.028(低 7%) | 不支持 |
| RP2V 精度(PCK) | 0.460(SOTA) | 不支持 | 不支持 |
| 视频时长 | 原生 10 秒 | 通常 5-8 秒 | 通常 5 秒 |
| 应用场景 | 数字人、动画、物体替换、混剪全覆盖 | 有限的人-物交互 | 静态外观迁移 |
从对比中可以清晰看到,OmniShow在参数效率、任务完备性、生成质量和视频长度上建立了全面的综合优势。
OmniShow的应用场景
如此强大的技术,最终将落地于广泛的实用场景。OmniShow的潜力在以下几个领域尤为突出:
电商产品展示:固定一个模特展示动作,通过替换参考图,即可快速生成模特穿着不同服装、佩戴不同首饰的展示短视频。这将极大提升电商平台的商品视频化制作效率与视觉吸引力。
数字人短视频制作:输入一张人物照片和一段语音,即可生成口型同步、表情自然的说话或唱歌视频。这对于虚拟主播、社交媒体内容创作者、在线教育讲师而言,是一个高效且低成本的内容生产工具。
创意视频混剪:其强大的多模态重组能力允许创作者进行天马行空的二次创作。例如,将电影A中的打斗姿势、广告B中的产品、网红C的形象,合成一个全新的创意短片,极大拓展了内容创作的边界与想象力。
互动娱乐与游戏:结合实时动作捕捉设备,用户的姿势可以瞬间驱动游戏角色或虚拟形象的动画,实现真正的全身姿态控制。这能为互动游戏、虚拟现实(VR)体验带来更高的沉浸感与参与度。
广告与营销内容生成:品牌方可以精确控制代言人的形象、台词音频和特定肢体动作,批量生成风格统一、个性定制化的广告视频素材,实现营销内容的降本增效与快速迭代。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

接手 十万行遗留代码?用 Claude 帮你快速拆解 Spring Boot 复杂业务
如何借力 Claude 快速拆解复杂的 Spring Boot 业务代码 面对一个刚接手的历史遗留项目,打开代码仓库的瞬间,那种感受恐怕很多同行都经历过: Controller层像迷宫,层层嵌套,入口难寻;Service方法动辄几百行,逻辑纠缠在一起;Mapper的调用链条深不见底;更棘手的是,一个

三大工具横评:Pandas/Polars/DuckDB 怎么选?不同数据规模最优解汇总
一份“接地气”的工具选择指南:Pandas、Polars与DuckDB,新手别再纠结了 面对海量数据,是不是总觉得手头的工具“差点意思”?今天这篇文章,咱们就掰开揉碎聊聊数据处理工具的选择。聚焦于核心定位、速度、语法和适用场景这四个维度,并结合不同的数据规模,为你提供一份清晰、可执行的“行动路线图”

踩坑!MySQL这个参数让应用直接崩了,90%的DBA都忽略了!
因MySQL参数“GIPK”引发的线上故障:一次完整的排查与避坑指南 今天,咱们来复盘一个源自MySQL参数的典型线上故障,并把整个过程掰开揉碎了讲清楚。这坑踩一次就够,希望后面的分享能帮你稳稳绕开。 做技术,最怕什么?怕的就是环境不一致。测试环境风平浪静,一到生产就“原地爆炸”,这种事儿可不少见。

/proc 文件系统实战:原来 top、htop 都是靠读文件实现的
一、 proc是什么:假装是文件系统的内核接口 乍一看, proc 就是个普通目录,对吧?但真相是,它压根不在硬盘上。它是一个由内核在内存中实时维护的虚拟文件系统(procfs)。每次你读取 proc 下的一个文件,内核都会现场“生成”对应的数据返回给你,数据是活的。 $ mount | grep

Vibe Coding正在杀死开源软件,让软件供应链风险悄然升级
什么是Vibe Coding? 如果要为2025年的开发者圈选一个年度热词,“Vibe Coding”(氛围编码)肯定名列前茅。这可不是什么玄乎的概念,它精准地描述了一种正在席卷整个行业的真实工作流:开发者不再事无巨细地敲下每一行代码,而是转向用自然语言向AI助手“描述”需求——选什么库、实现什么功








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
