




/proc 文件系统实战:原来 top、htop 都是靠读文件实现的

一、 proc是什么:假装是文件系统的内核接口 乍一看, proc 就是个普通目录,对吧?但真相是,它压根不在硬盘上。它是一个由内核在内存中实时维护的虚拟文件系统(procfs)。每次你读取 proc 下的一个文件,内核都会现场“生成”对应的数据返回给你,数据是活的。 $ mount | grep
一、/proc是什么:假装是文件系统的内核接口
乍一看,/proc 就是个普通目录,对吧?但真相是,它压根不在硬盘上。它是一个由内核在内存中实时维护的虚拟文件系统(procfs)。每次你读取 /proc 下的一个文件,内核都会现场“生成”对应的数据返回给你,数据是活的。
$ mount | grep proc
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
$ ls /proc
1 42 1234 ... # 数字目录 = 正在运行的进程(PID)
cpuinfo meminfo net sys ... # 系统全局信息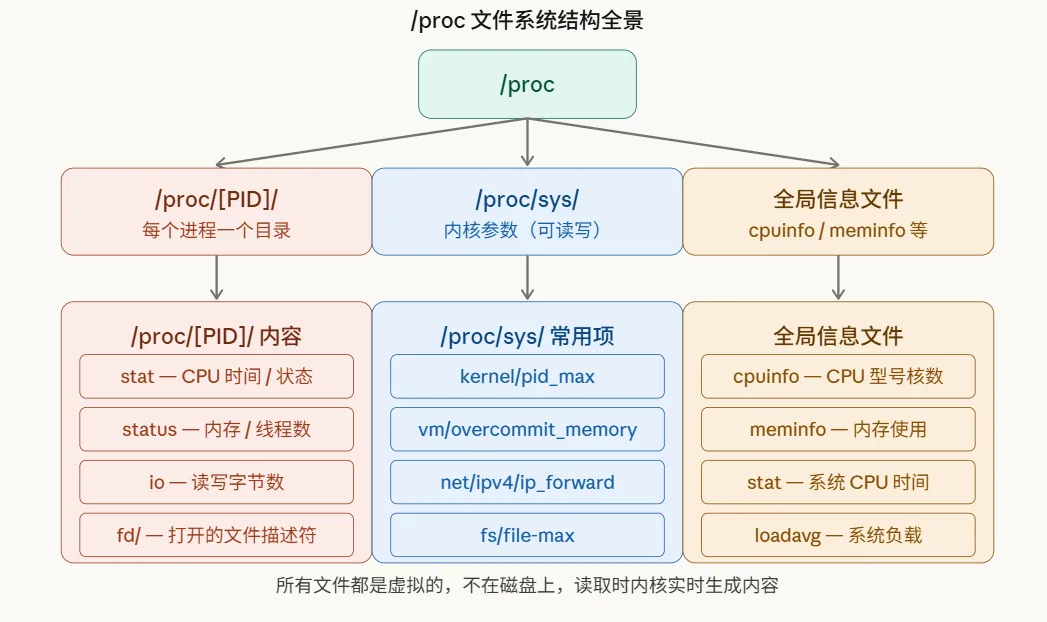
先随手试几个命令,感受一下它的脉搏:
# 当前进程的 PID
echo $$ # 假设是 12345
# 查看进程状态
cat /proc/12345/status
# 查看内存信息
cat /proc/meminfo | head -5
# 查看 CPU 信息
cat /proc/cpuinfo | grep "model name" | head -1
# 查看系统负载(1/5/15 分钟平均负载)
cat /proc/loada vg二、/proc/[PID]/里有什么宝藏?
每个正在运行的进程,在 /proc 下都有一个以自己 PID 命名的专属目录。这里面藏着的,正是 top、htop 这些监控工具的原始数据源。
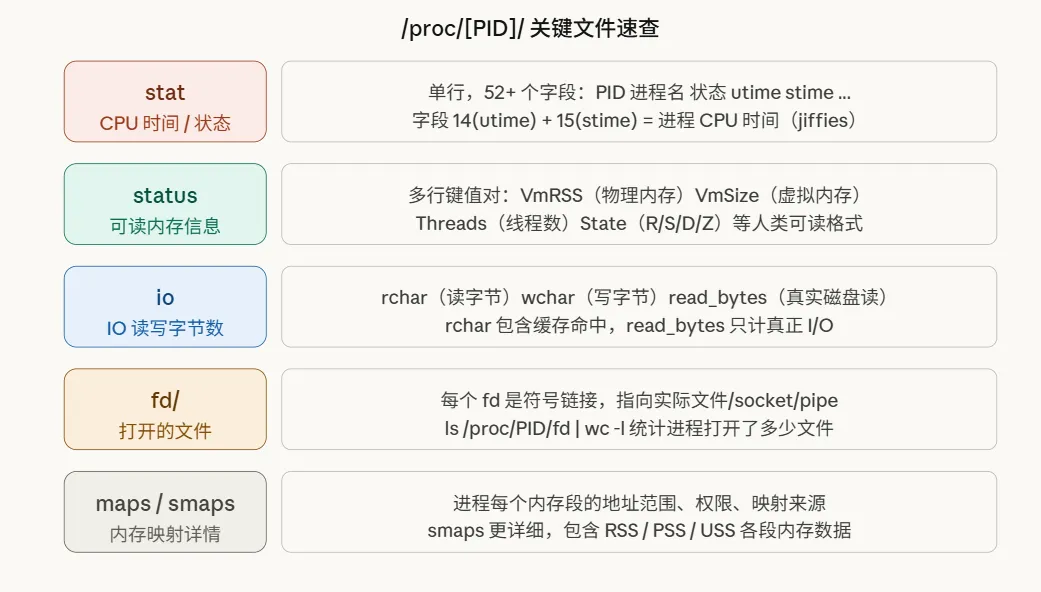
光说不练假把式,我们直接动手看看真实数据长什么样:
# 找到 nginx 的 PID
pidof nginx # 假设是 1234
# CPU 时间(第14、15字段)
cat /proc/1234/stat | awk '{print "utime="$14, "stime="$15}'
# 物理内存(单位 kB)
grep VmRSS /proc/1234/status
# 打开的文件数量
ls /proc/1234/fd | wc -l
# 实际磁盘 IO
cat /proc/1234/io三、CPU 使用率的计算原理:不是直接读出来的
这里有个最常见的理解误区:/proc/[PID]/stat 里并没有直接存储着“CPU 使用率 3.2%”这样的现成数字。
它存储的是进程自启动以来累计消耗的 CPU 时间,单位是 jiffies(1 jiffie 可能是 10ms 或 4ms,取决于内核配置)。那么,top 是怎么算出那个百分比的?答案是:两次采样做差。

这下就明白了,为什么 top 默认每 3 秒刷新一次。它每隔 3 秒做一次快照,然后用进程在这 3 秒内消耗的 CPU 时间增量,除以系统在这 3 秒内的总 CPU 时间增量,从而得到这 3 秒内的平均 CPU 使用率。系统总 CPU 时间从 /proc/stat 读取,进程 CPU 时间则来自 /proc/[PID]/stat。
四、动手实现:迷你进程监控器
纸上得来终觉浅,现在我们把上面的知识串起来,写一个真正能跑的迷你进程监控工具,核心逻辑不到100行。
#include
#include
#include
#include
typedef struct {
long utime, stime; // 进程 CPU 时间
long total_cpu; // 系统总 CPU 时间
long vm_rss; // 物理内存 KB
long rchar, wchar; // IO 读写字节
} ProcInfo;
// 读进程 CPU 时间(/proc/PID/stat 第14、15字段)
void read_proc_stat(int pid, ProcInfo *info) {
char path[64];
snprintf(path, sizeof(path), "/proc/%d/stat", pid);
FILE *f = fopen(path, "r");
if (!f) return;
// 跳过前13个字段,读第14(utime)和第15(stime)
long dummy; char name[256]; char state;
fscanf(f, "%ld %s %c %ld %ld %ld %ld %ld %ld %ld %ld %ld %ld %ld %ld",
&dummy, name, &state,
&dummy, &dummy, &dummy, &dummy, &dummy,
&dummy, &dummy, &dummy, &dummy, &dummy,
&info->utime, &info->stime);
fclose(f);
}
// 读系统总 CPU 时间(/proc/stat 第1行)
long read_total_cpu() {
FILE *f = fopen("/proc/stat", "r");
long user, nice, system, idle, iowait, irq, softirq;
fscanf(f, "cpu %ld %ld %ld %ld %ld %ld %ld",
&user, &nice, &system, &idle, &iowait, &irq, &softirq);
fclose(f);
return user + nice + system + idle + iowait + irq + softirq;
}
// 读物理内存(/proc/PID/status 中的 VmRSS)
void read_memory(int pid, ProcInfo *info) {
char path[64], line[128];
snprintf(path, sizeof(path), "/proc/%d/status", pid);
FILE *f = fopen(path, "r");
while (fgets(line, sizeof(line), f)) {
if (strncmp(line, "VmRSS:", 6) == 0) {
sscanf(line, "VmRSS: %ld", &info->vm_rss);
break;
}
}
fclose(f);
}
// 读 IO 字节数(/proc/PID/io)
void read_io(int pid, ProcInfo *info) {
char path[64], line[128];
snprintf(path, sizeof(path), "/proc/%d/io", pid);
FILE *f = fopen(path, "r");
if (!f) return; // 需要 root 才能读其他用户的 io
while (fgets(line, sizeof(line), f)) {
if (strncmp(line, "rchar:", 6) == 0) sscanf(line, "rchar: %ld", &info->rchar);
if (strncmp(line, "wchar:", 6) == 0) sscanf(line, "wchar: %ld", &info->wchar);
}
fclose(f);
}
int main(int argc, char *argv[]) {
if (argc < 2) { printf("用法: %s \n", argv[0]); return 1; }
int pid = atoi(argv[1]);
ProcInfo prev = {}, curr = {};
while (1) {
read_proc_stat(pid, &prev);
prev.total_cpu = read_total_cpu();
read_memory(pid, &prev);
read_io(pid, &prev);
sleep(1); // 采样间隔 1 秒
read_proc_stat(pid, &curr);
curr.total_cpu = read_total_cpu();
read_memory(pid, &curr);
read_io(pid, &curr);
// 计算 CPU 使用率
long proc_delta = (curr.utime + curr.stime) - (prev.utime + prev.stime);
long total_delta = curr.total_cpu - prev.total_cpu;
double cpu_pct = total_delta > 0 ? (double)proc_delta / total_delta * 100.0 : 0.0;
// 计算 IO 速率(字节/秒)
long read_rate = curr.rchar - prev.rchar;
long write_rate = curr.wchar - prev.wchar;
printf("\033[2J\033[H"); // 清屏
printf("PID: %d\n", pid);
printf("CPU: %.1f%%\n", cpu_pct);
printf("内存: %ld KB (%.1f MB)\n", curr.vm_rss, curr.vm_rss / 1024.0);
printf("读 IO: %ld B/s\n", read_rate);
printf("写 IO: %ld B/s\n", write_rate);
printf("FD 数量: ");
fflush(stdout);
// 统计打开的文件描述符数量
char fd_path[64];
snprintf(fd_path, sizeof(fd_path), "ls /proc/%d/fd 2>/dev/null | wc -l", pid);
system(fd_path);
prev = curr;
}
return 0;
} 编译并运行它:
gcc -O2 -o minimon minimon.c
./minimon 1234 # 监控 PID 为 1234 的进程你会看到类似这样的实时输出:
PID: 1234
CPU: 12.3%
内存: 45312 KB (44.3 MB)
读 IO: 8192 B/s
写 IO: 4096 B/s
FD 数量: 23五、/proc的其他实用技巧
快速查看进程完整命令行:
cat /proc/1234/cmdline | tr '\0' ' '
# 输出示例:/usr/sbin/nginx -g daemon off;查看进程打开了哪些文件/连接:
ls -la /proc/1234/fd
# 输出示例:
# lrwxrwxrwx 0 -> /dev/null
# lrwxrwxrwx 1 -> pipe:[12345]
# lrwxrwxrwx 3 -> socket:[67890]
# lrwxrwxrwx 4 -> /var/log/nginx/access.log读取/修改内核参数(无需重启):
# 查看最大文件描述符数
cat /proc/sys/fs/file-max
# 开启 IP 转发(Docker/K8s 必须开)
echo 1 > /proc/sys/net/ipv4/ip_forward
# 等价于 sysctl -w net.ipv4.ip_forward=1查看系统整体内存使用:
cat /proc/meminfo
# MemTotal: 16384000 kB
# MemFree: 2048000 kB
# Cached: 4096000 kB ← Page Cache
# Buffers: 512000 kB
# ...查看所有进程的内存总使用量(比 free 命令更精确):
# 把所有进程的 VmRSS 加起来
grep VmRSS /proc/*/status 2>/dev/null | awk '{sum+=$2} END {print sum/1024 " MB"}'六、高频面试题精析
Q:/proc目录里的文件真的存在磁盘上吗?
不存在。/proc 是 procfs 虚拟文件系统,挂载在内存里。读取一个 /proc 文件时,内核会实时生成对应数据返回;写入某些文件(如 /proc/sys/ 下的文件)则会直接修改内核参数。这些文件没有 inode 对应的磁盘块,用 ls -l 看大小显示为 0,但内容是实时、真实的。
Q:top显示的 CPU 使用率是怎么算出来的?
top 定期读取 /proc/[PID]/stat(获取进程 CPU 时间)和 /proc/stat(获取系统总 CPU 时间),进行两次采样。然后用进程 CPU 时间的增量,除以系统总 CPU 时间的增量,得到百分比。这就是为什么刚启动 top 时,通常需要等待一个刷新周期(比如3秒)后,数据才会变得准确。
Q:VmRSS和VmSize有什么区别?
VmSize 是进程的虚拟内存大小——它包括了所有映射的地址空间,但其中大部分可能并没有对应的物理内存页。VmRSS(Resident Set Size)则是实际占用的物理内存——即已经加载到 RAM 中的页面。监控内存使用率时应该看 VmRSS,VmSize 通常会因为包含大量共享库和映射空间而显得虚高。
Q:为什么有些进程的/proc/[PID]/io读不了?
读取其他用户进程的 io 文件需要 root 权限(或 CAP_SYS_PTRACE 能力)。读取自己进程的 io 则无需特殊权限。这是内核出于安全考虑的设计——IO 数据能够揭示进程的行为模式,不应随意暴露给非特权用户。
七、结语
/proc 堪称 Linux 系统最透明的一扇窗。内核把自己几乎所有的运行时状态,都以文件的形式陈列于此,对任何有权限的读者开放。
我们日常使用的 top、htop、ps、lsof、netstat 等工具,本质上都是 /proc 的“读者”和“翻译官”。现在,你不仅知道了它们的数据从何而来,也掌握了亲手打造专属监控工具的能力。下次再看到进程指标跳动时,你看到的将不再是一个神秘的数字,而是一段可以直接触摸和计算的数据流。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

学霸港姐王嘉慧晒美照颜值体态双在线气质出众
2024年港姐五强王嘉慧晒出写真,身形清瘦线条紧致,气质出众。她分享长期健身塑造体态,并立下目标:计划2027年挑战HYROX综合体能赛事,展现突破极限的决心。她表示将为此加强训练,追求更完美自我。

理想汽车负责人称张雪819三缸机解决国产大排量摩托瓶颈
这几天,中国摩托车圈最火的话题,莫过于张雪机车在 WSBK 赛场上拿下的那个冠军——这可是中国摩托第一次在这个国际顶级赛事里站上最高领奖台。一时间,张雪 820RR 这台车成了话题中心,大家热议的焦点,自然是它搭载的那台直列三缸发动机:最大马力 135PS,零百加速只要 2 81 秒,数据相当硬核。

鸿蒙智行6月车型销量问界第一尚界跃居第二
鸿蒙智行6月零售:问界30199台居首,尚界Z7系列跃升第二,智界、享界、尊界随后。总交付50624台,环比增9 7%;上半年累计24万台,同比增18 6%。

吉利银河M7中型电混SUV本月上旬预售下旬上市
吉利银河M7正式登场,携硬核实力进军中级电混SUV市场。4月3日官方确认,新车将于本月上旬开启预售,下旬正式上市。作为银河M系列首款中级电混SUV,其核心参数令人瞩目:纯电续航达225km,综合续航突破1730km。 简单来说,新车可视为银河L7的改款升级,前脸采用银河M9家族式设计语言,双色车身设

捷豹路虎因车顶饰条脱落隐患召回部分进口揽胜及揽胜运动版
近日,国家市场监督管理总局发布了一则重要召回信息。2026年4月7日,捷豹路虎(中国)投资有限公司正式备案了召回计划,涉及部分进口路虎揽胜和揽胜运动版车型,引起了广泛关注。 根据召回编号S2026M0038V:自2026年6月1日起,捷豹路虎将召回2024年1月18日至2025年11月27日期间生产








- 热门数据榜



 相关攻略
相关攻略
 2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:09
2026-07-09 14:09
2026-07-09 14:09
2026-07-09 14:09
热门教程
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:10
2026-07-09 14:09
2026-07-09 14:09
2026-07-09 14:09
2026-07-09 14:09
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















