




架构必知:大数据架构精讲(附架构图)

深入&浅出,用5W2H拆解大数据架构核心
今天,咱们开门见山,不兜圈子。无论是技术选型还是架构设计,面对“大数据架构”这个宏大的命题,是不是总觉得概念纷繁、难以抓住重点?别急,这篇文章的目的很直接:帮你从纷繁复杂中理清主线,掌握精髓。
我们的主线非常清晰:先用经典的5W2H分析法,帮你把大数据架构的“为什么”和“怎么做”彻底讲透;然后,我们会逐一拆解 Lambda架构、Kappa架构、湖仓一体架构和数据湖架构这几种主流方案。不仅会展示清晰的架构图,还会剖析其核心流程和实际落地场景,把理论知识和你未来的实践无缝连接起来。

一、庖丁解牛:用5W2H拆解大数据架构
理解任何复杂体系,方法论很重要。用5W2H来拆解大数据架构,堪称一剂“化骨绵掌”。但请记住,所有环节中,有两个关键点必须牢牢抓住:首先是**【Why】**,即这个架构究竟要解决什么业务痛点;其次是**【How】**,如何基于一系列核心技术,组合成那些经典的架构模式。把这二者吃透,你就抓住了牛鼻子。
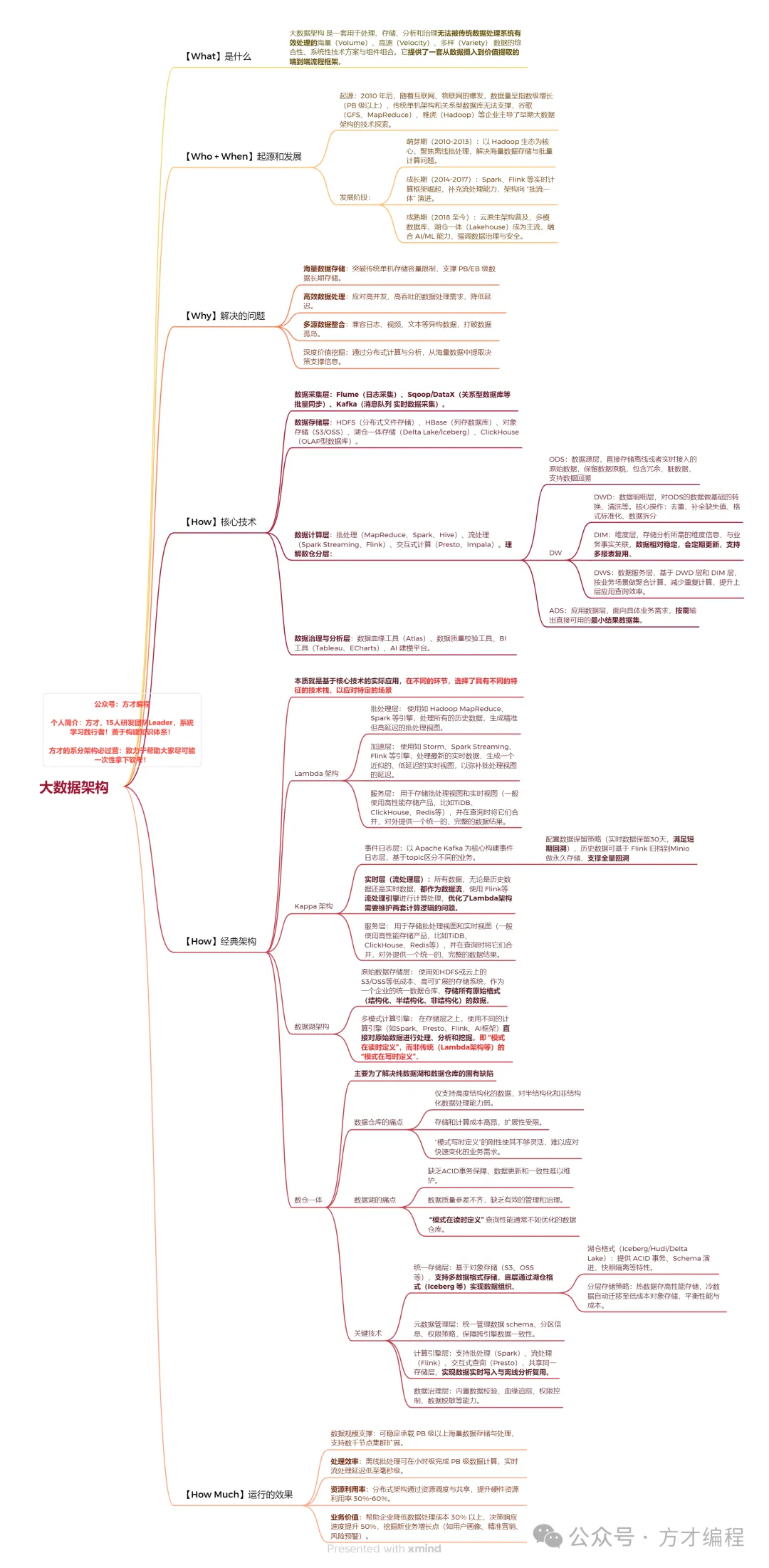
二、架构图鉴:从蓝图到落地
1. Lambda架构:经典的双引擎模式
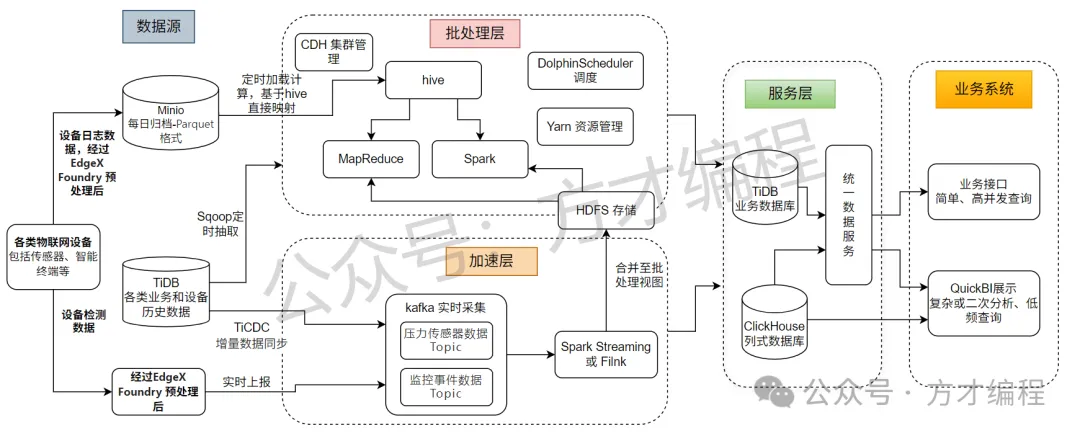
Lambda架构的设计哲学非常巧妙,它用“批处理层”和“流处理层”这一对新老搭档,完美兼顾了数据处理的“准确性”(离线批量)与“时效性”(实时流式)。简单来说,它让历史数据的深度挖掘和当下数据的快速响应得以并行不悖。再加上统一的服务层封装,可以灵活支撑从高并发事务查询到复杂分析报表的各类业务场景。
(1) 数据源层:数据的入口与分流
一切始于数据源。在典型的物联网场景中,传感器等设备源源不断地产生日志和状态数据。这些数据通过EdgeX Foundry进行初步处理后,会面临一个关键的分流决策:
一条支路通向“记忆库”——数据按日归档至Minio对象存储(通常采用Parquet列式格式),等待离线批处理的召唤;另一条支路则走上“快车道”——实时涌入Kafka等消息队列,为即时分析提供燃料。同时,像TiDB这样的业务数据库,既存储着关键的历史状态,也能通过Sqoop或TiCDC等工具,将数据同步供给批处理或流处理层使用。
(2) 批处理层:稳扎稳打的离线计算
这是处理海量历史数据的主力军。它的任务链条很清晰:从Minio归档库中定时提取数据,借助Hive进行组织与管理,然后由MapReduce或Spark这类分布式计算框架执行繁重的批量计算任务,最终结果沉淀到HDFS中。整个过程由Yarn统一调度资源,由DolphinScheduler之类的工具编排任务流程,确保庞大而复杂的离线作业井然有序。
(3) 加速层:争分夺秒的实时处理
与批处理层的“稳重”相对,加速层追求的是“敏捷”。来自Kafka不同Topic的实时数据流,被Spark Streaming或Flink这样的流处理引擎快速消费、计算。计算结果有两个去向:要么与离线批处理视图合并,形成更全面的数据视角;要么直接输出给下游服务层,以满足对延迟极度敏感的查询需求。
(4) 服务层:数据的统一代言人
处理好的数据如何高效交付给业务?服务层就是关键枢纽。这里通常会采用混合存储策略:用TiDB来应对高并发、强一致的事务型查询;用ClickHouse的列式引擎来加速复杂的多维分析。然后,通过一层统一的数据服务接口,将底层不同的数据源封装起来,向上游业务提供简洁、标准的访问方式。
(5) 业务系统层:价值最终落地
架构的价值,最终体现在业务应用上。服务层的接口在这里被直接调用:对于设备状态查询这类简单但高并发的需求,走业务接口;对于需要深度钻取、可视化展现的分析报表,则由QuickBI等工具接入,满足业务人员的自助分析需求。
2. Kappa架构:流处理的统一视野
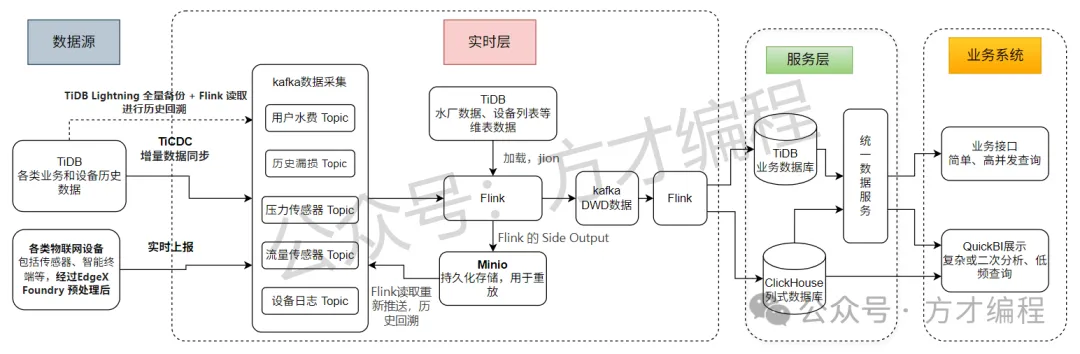
Kappa架构可以看作是Lambda架构的一个精简与进化版本。它的核心思想是“万物皆流”,通过强大的流处理引擎来处理所有数据。理解了Lambda的双路径设计后,Kappa的“单一路径”理念就更容易把握了,这里不再赘述其相似的数据流转细节。
3. 湖仓一体架构:融合的智慧
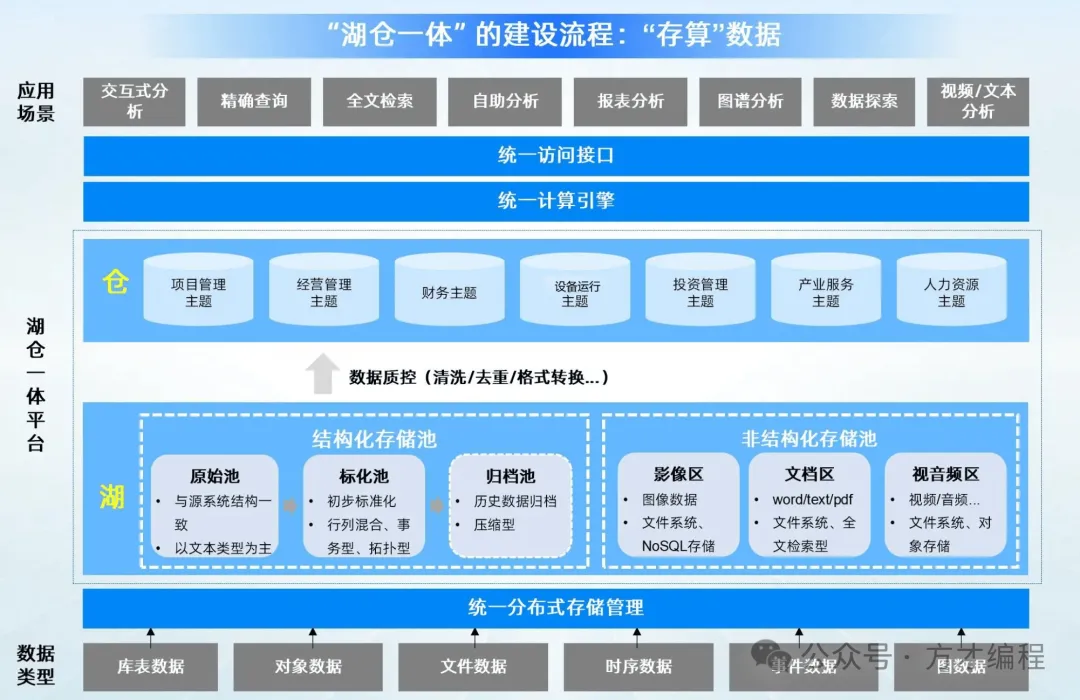
“湖仓一体”是近年来大数据领域的一个热门趋势,旨在融合数据湖的灵活性与数据仓库的治理能力。上图清晰地展示了这种融合架构,我们可以从四个层面来理解它。
(1) 数据源层:包罗万象的原材料
这一层如同一个开放的港口,接纳各式各样的数据“货物”:从传统的库表结构化数据,到文档、图片等非结构化对象,再到时序数据、事件流乃至描述复杂关系的图数据。多样性是它的主要特征。
(2) 湖仓一体平台层:核心的融合体
这是整个架构的“心脏”,它由“湖”和“仓”有机组成。
① “湖”——多样化的原始存储池:它又分为两部分。结构化存储池像是一个数据加工流水线,包含保存原始样貌的“原始池”、经过初步标准化的“标化池”以及用于长期压缩存放的“归档池”。非结构化存储池则像专业仓库,分门别类地存放影像、文档、音视频等数据。
② “仓”——主题化的数据集市:这里的数 据已经历了清洗、转换等质控流程,并按照项目管理、财务、设备运行等明确的业务主题组织起来。这样一来,业务人员能够像在超市选购商品一样,快速找到所需的数据品类。
(3) 统一计算与存储管理层:强大的中台能力
这一层为上层应用提供了“一站式服务”。统一的分布式存储管理负责调度所有底层资源;统一的计算引擎(如Spark、Flink)支撑各类分析任务;统一的访问接口则屏蔽了底层的技术复杂性,让应用开发更聚焦于业务逻辑。
(4) 应用场景层:数据的价值绽放
架构的终极目标是赋能业务。在这里,数据通过多种形式转化为洞察:无论是交互式的即席查询、精准的报表分析,还是基于图谱的关系挖掘,甚至是利用AI对视频、文本进行智能分析,丰富的数据服务让业务创新成为可能。
4. 数据湖架构:原始的包容力
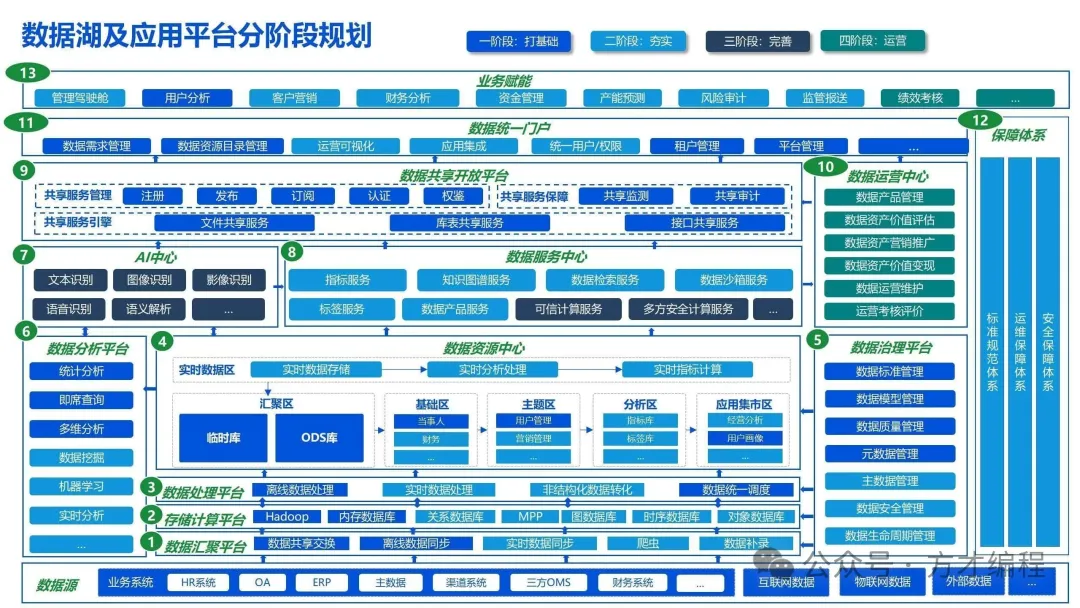
这张来自网络的架构图非常完整,可以作为大数据平台建设的通用参考。实际上,前面几种架构中的许多公共组件(如数据摄入、存储管理)的思想,都能在这里找到映射。
看到这里,相信你已经能体会到那句话的真意:不同的架构,其本质就是围绕核心的业务目标(Why),在数据流转的各个环节(How),选用了具备不同特征的技术栈进行组合。数据湖架构与湖仓一体架构的主要区别,也在于此:数据湖更强调对原始、多类数据的“低成本、无障碍存储”,而湖仓一体则在存储的基础上,更强化了“数据治理、质量保证和高效分析”的能力。结合前面的解读,理解数据湖架构的核心思想应该已经水到渠成。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

马斯克买下Cursor后,OpenAI和Claude还能留在平台上吗?
7月3日消息,SpaceX以600亿美元收购AI编程工具Cursor,交易还未完成,一个现实问题已经摆在台面上:收购之后,Cursor还能不能继续支持OpenAI和Anthropic的模型?据《连线》(Wired)报道,Cursor(由Anysphere公司开发)一直是市场上为数不多允许用户在不同A

Kimi图像理解图形化模块与DFRobot行空板为视障人士开启新“视”界
一位创客开发了一款基于Kimi图像理解功能的辅助项目,旨在利用人工智能技术帮助视障人士更好地感知周围环境。该项目通过精准识别图像中的文字、颜色和物体形状等信息,为视障群体提供更便捷的环境感知能力。该项目结合硬件设备与Kimi的图像理解能力,将视觉信息转化为可理解的反馈,帮助视障人士更自信地融入社会生

谷歌Gemini 3.5 Pro曝200万Tokens上下文,前端赶超Fable 5
IT之家 7 月 7 日消息,消息源 @HarshithLucky3 昨日(7 月 6 日)在 X 平台发布推文,爆料称谷歌计划 7 月 17 日发布 Gemini 3 5 Pro 模型,支持 200 万上下文窗口,引入全新“深度思考”推理模式等。定位方面,消息称 Gemini 3 5 Pro 模型

Grok AI模型将仅适配搭载AMD锐龙处理器的特斯拉车型,而英特尔芯片的旧款车型无缘升级
Grok系统已成功入驻特斯拉,车载人工智能助手终于成为现实,让车主能借助人工智能技术大幅提升驾乘体验。不过当前部署存在一个限制条件:Grok的AI模型仅支持搭载AMD锐龙处理器的信息娱乐系统,而采用英特尔方案的旧款车型则因性能不足无缘该功能。虽然这在一定程度上限制了Grok在特斯拉车型的覆盖范围,但

三星Galaxy S25 Edge发布 5.8mm超薄旗舰手机
5月13日,三星电子正式发布了年度旗舰机型——Galaxy S25 Edge。这款新机作为Galaxy S系列的超薄形态开拓者,机身厚度仅5 8毫米(不含摄像头模组),配合钛金属边框,将高端智能手机的设计标准再次推向新高度。可以说,它既延续了Galaxy系列一贯的创新基因,又在多项技术环节上为行业树








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-07 15:57
2026-07-07 15:10
2026-07-07 14:45
2026-07-07 14:45
2026-07-07 14:01
2026-07-07 14:00
2026-07-07 14:00
2026-07-07 14:00
热门教程
2026-07-07 15:57
2026-07-07 15:10
2026-07-07 14:45
2026-07-07 14:45
2026-07-07 14:01
2026-07-07 14:00
2026-07-07 14:00
2026-07-07 14:00
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
