




通过KeepAlived搭建MySQL双主模式的Mysql集群图文教程

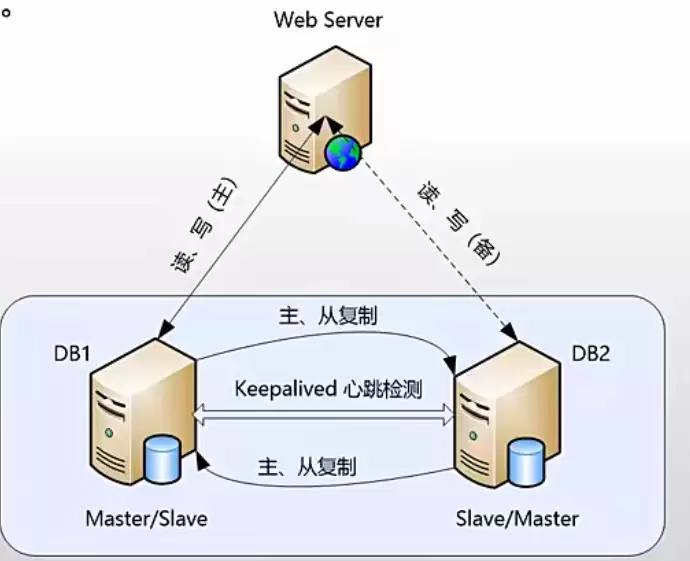
MySQL主主互备模式架构图
这个架构的核心思路,是利用MySQL的复制技术,让两台服务器互为“主”和“从”。简单来说,就是DB1把DB2当作自己的主库来同步数据,同时DB2也把DB1当作自己的主库。这样一来,数据就在两台机器间实现了双向同步,为高可用打下了基础。不过,这里有个关键点:虽然两台服务器互为主从,但为了保证数据绝对一致,同一时刻只能有一台服务器接受写入操作,另一台则处于只读状态。自动故障切换的任务,我们交给KeepAlived来完成。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
MySQL主主互备环境说明
操作系统:redhat MySQL : mysql8.0.42 Keepalived : Keepalived2.2.8 两台主机:172.16.213.181(DB1)、172.16.213.189 ( DB2 )
无损半同步复制—抢占模式过程
配置过程
- 配置之前关闭防火墙和selinux。也可放行
- 在进行互相备份的时候,需要将数据库保持一致
如果DB1上已经存在数据,那么在搭建主主互备之前,必须确保DB2的数据与DB1完全一致。操作的第一步,是在DB1上锁定数据库并备份数据。执行下面这条SQL语句:
mysql>FLUSH TABLES WITH READ LOCK; Query OK, 0 rows affected (0.00 sec)
注意,执行这个命令的终端不能关闭,否则锁会立即释放。我们需要在这个终端保持连接的状态下,另开一个终端,直接打包MySQL的数据目录。具体操作如下:
[root@DB1 ~]# cd /usr/local/mysql [root@DB1 mysql]# tar zcvf data.tar.gz data [root@DB1 mysql]# scp data.tar.gz DB2:/usr/local/mysql
将数据包传输到DB2并解压后,分别重启DB1和DB2上的MySQL服务。
这里有个细节需要特别注意:如果两个数据库是通过直接拷贝数据文件得来的,那么必须修改其中一台服务器的UUID。UUID文件位于MySQL数据目录下的auto.cnf中,务必确保两个库的UUID不同,否则复制会出问题。
- 修改mysql的配置文件为无损半同步复制(yum安装的方式,配置文件在/etc/my.cnf)
- 主节点服务器DB1配置如下:
[mysqld] datadir=/usr/local/mysql/data socket=/tmp/mysql.sock log-error=/usr/local/mysql/logs/mysqld.log pid-file=/usr/local/mysql/logs/mysqld.pid gtid_mode=ON #方便维护 enforce_gtid_consistency=ON #确保复制正确性 server-id = 1 #节点的标识 log-bin=mysql-bin #启用mysql-bin日志文件 relay-log = mysql-relay-bin #启用中继日志文件 replicate-wild-ignore-table=mysql.% #忽略备份系统库 replicate-wild-ignore-table=test.%#忽略备份表 replicate-wild-ignore-table=information_schema.% #忽略备份表 plugin_load = "rpl_semi_sync_source=semisync_source.so;rpl_semi_sync_replica=semisync_replica.so" #加载指定的插件 rpl_semi_sync_source_enabled=1 #开启插件 rpl_semi_sync_replica_enabled=1 #开启插件 log_replica_updates=ON
- 备节点服务器DB2配置如下:
[mysqld] datadir=/usr/local/mysql/data socket=/tmp/mysql.sock log-error=/usr/local/mysql/logs/mysqld.log pid-file=/usr/local/mysql/logs/mysqld.pid gtid_mode=ON #方便维护 enforce_gtid_consistency=ON #确保复制正确性 server-id = 2 #节点的标识 log-bin=mysql-bin #启用mysql-bin日志文件 relay-log = mysql-relay-bin #启用中继日志文件 replicate-wild-ignore-table=mysql.% #忽略备份系统库 replicate-wild-ignore-table=test.%#忽略备份表 replicate-wild-ignore-table=information_schema.% #忽略备份表 plugin_load = "rpl_semi_sync_source=semisync_source.so;rpl_semi_sync_replica=semisync_replica.so" #加载指定的插件 rpl_semi_sync_source_enabled=1 #开启插件 rpl_semi_sync_replica_enabled=1 #开启插件 log_replica_updates=ON
- 主节点创建数据库备份用户(修改为自己的网段)
CREATE USER 'repl_user'@'192.168.123.%' IDENTIFIED WITH mysql_native_password BY 'Fe216474@';
- 主节点执行授权(修改为自己的网段)
GRANT REPLICATION SLA VE, REPLICATION CLIENT ON *.* TO 'repl_user'@'192.168.123.%';
- 备用服务器运行实现主从复制的脚本(在备用节点的mysql中执行,记得修改为自己配置的信息)
CHANGE REPLICATION SOURCE TO SOURCE_HOST = '192.168.123.129', #主节点配置ip SOURCE_USER = 'repl_user', #主节点创建的用户 SOURCE_PASSWORD = 'Fe216474@', #主节点创建的密码 SOURCE_AUTO_POSITION = 1;
- 启动备用服务器DB2从库并查看是否启动成功
START SLA VE; mysql> SHOW SLA VE STATUS\G;
当看到如下输出时,就说明DB2到DB1的复制链路已经成功建立了。

- 接下来配置反向复制,即从DB1复制到DB2。在DB1上执行下面命令,创建复制用户并授权(请修改为自己的信息)
CREATE USER 'repl_user'@'192.168.123.%' IDENTIFIED WITH mysql_native_password BY 'Fe216474@';
GRANT REPLICATION SLA VE, REPLICATION CLIENT ON *.* TO 'repl_user'@'192.168.123.%';
- 在DB1上执行脚本,指向DB2作为其主库
CHANGE REPLICATION SOURCE TO SOURCE_HOST = '192.168.123.100',#从节点的ip SOURCE_USER = 'repl_user', #从节点创建的用户 SOURCE_PASSWORD = 'Fe216474@', SOURCE_AUTO_POSITION = 1;

- 通过yum的方式安装keepalived
yum install keepalived
安装完成后,进入其配置文件目录:
cd /etc/keepalived/
- 为了让Keepalived能感知MySQL状态,需要先准备一个检测脚本check_sla ve.pl(记得修改其中的密码和连接信息)
#!/usr/bin/perl -w
use DBI;
use DBD::mysql;
# CONFIG VARIABLES
$SBM = 120;
$db = "mysql";
$host = $ARGV[0];
$port = 3306;
$user = "root";
$pw = "123456";
# SQL query
$query = "show sla ve status";
$dbh = DBI->connect("DBI:mysql:$db:$host:$port", $user, $pw, { RaiseError => 0,PrintError => 0 });
if (!defined($dbh)) {
exit 1;
}
$sqlQuery = $dbh->prepare($query);
$sqlQuery->execute;
$Sla ve_IO_Running = "";
$Sla ve_SQL_Running = "";
$Seconds_Behind_Master = "";
while (my $ref = $sqlQuery->fetchrow_hashref()) {
$Sla ve_IO_Running = $ref->{'Sla ve_IO_Running'};
$Sla ve_SQL_Running = $ref->{'Sla ve_SQL_Running'};
$Seconds_Behind_Master = $ref->{'Seconds_Behind_Master'};
}
$sqlQuery->finish;
$dbh->disconnect();
if ( $Sla ve_IO_Running eq "No" || $Sla ve_SQL_Running eq "No" ) {
exit 1;
} else {
if ( $Seconds_Behind_Master > $SBM ) {
exit 1;
} else {
exit 0;
}
}

脚本准备好之后,接下来修改Keepalived的主配置文件keepalived.conf,别忘了将配置中的网卡名称换成你自己服务器的(可以通过ifconfig命令查看)。
- 从节点的keepalive.conf配置:
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script check_httpd {
script "killall -0 httpd"
interval 2
}
vrrp_instance HA_1 {
state BACKUP #主节点是MASTER
interface ens33 #记得更换为自己的网卡ifconfig查看
virtual_router_id 80
priority 80#主节点的权重需要设置高一些
advert_int 2
authentication {
auth_type PASS
auth_pass qwaszx
}
notify_master "/etc/keepalived/master.sh "
notify_backup "/etc/keepalived/backup.sh"
notify_fault "/etc/keepalived/fault.sh"
track_script {
check_httpd
}
virtual_ipaddress {
192.168.123.80/24 dev ens33 #记得更换为自己的网卡ifconfig查看
}
}
- 主节点的keepalive.conf配置:
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script check_httpd {
script "killall -0 httpd"
interval 2
}
vrrp_instance HA_1 {
state MASTER #
interface ens33 #记得更换为自己的网卡ifconfig查看
virtual_router_id 80
priority 100#主节点的权重需要设置高一些
advert_int 2
authentication {
auth_type PASS
auth_pass qwaszx
}
notify_master "/etc/keepalived/master.sh "
notify_backup "/etc/keepalived/backup.sh"
notify_fault "/etc/keepalived/fault.sh"
track_script {
check_httpd
}
virtual_ipaddress {
192.168.123.80/24 dev ens33 #记得更换为自己的网卡ifconfig查看
}
}
验证数据备份
- 在从库创建数据库
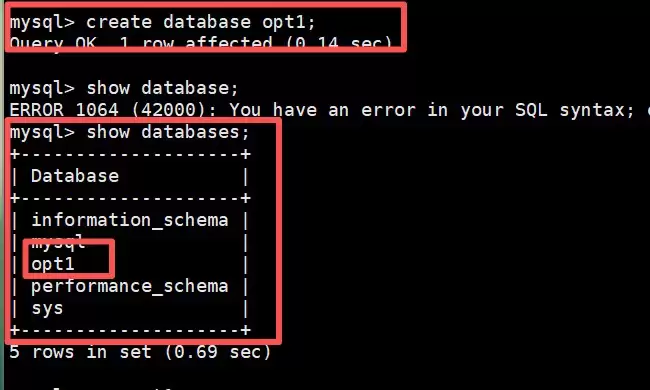
- 主库查看是否存在
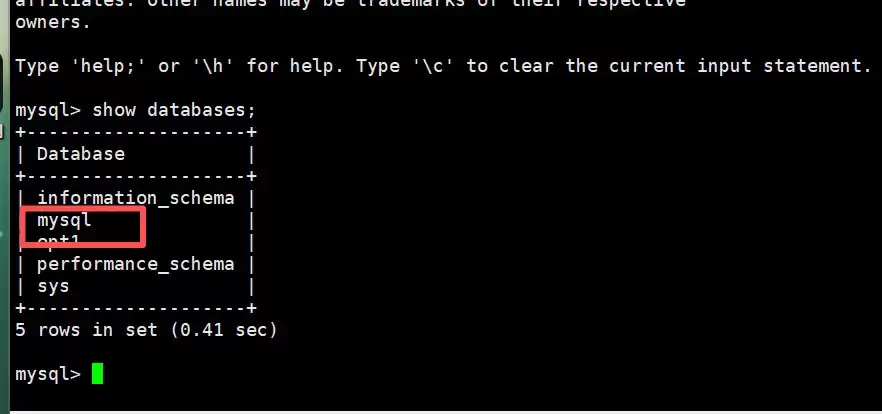
可以看到,数据已经成功同步,主从复制配置生效。
- 验证数据库的故障转移
现在,我们来模拟主库故障。在主库DB1上执行systemctl stop mysqld.service,停止MySQL服务。

此时观察从库DB2的日志信息。
- 远程登录mysql,验证故障切换
这里有个前提:如果你需要远程创建用户,记得先临时关闭配置文件/etc/my.cnf中关于忽略系统库复制的设置,否则复制账户无法创建。如下图所示:
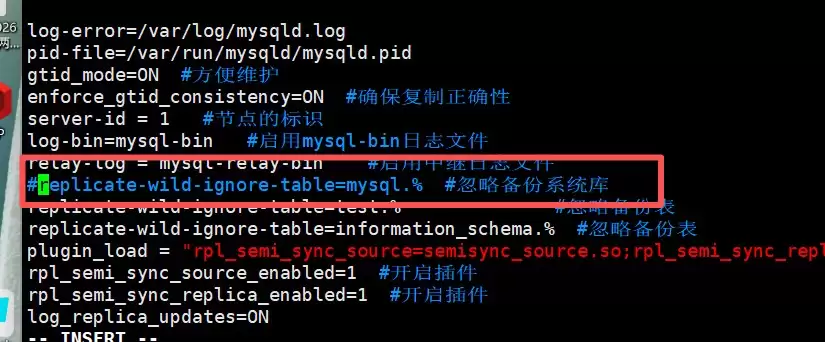
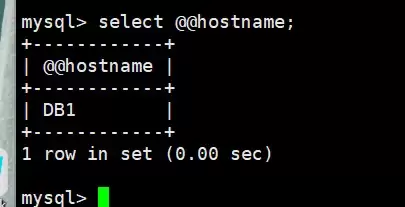
当DB1故障后:
[root@localhost keepalived]# systemctl stop mysqld.service
从远端查询数据库,显示连接正常:
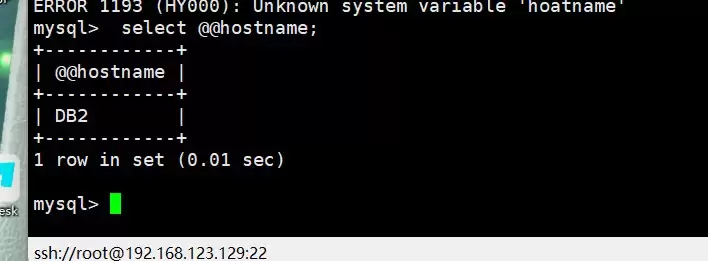
至此,故障自动切换验证完成,VIP已成功漂移到健康的DB2节点。
无损半同步复制—不抢占模式过程
不抢占模式的配置与上述抢占模式大体相同,区别在于主库选举策略。它不依赖初始优先级强行抢占,而是根据状态进行选举。只需要修改两个地方:
- 将两台服务器的keepalive.conf配置文件中的
state都改为BACKUP,并添加nopreempt参数。
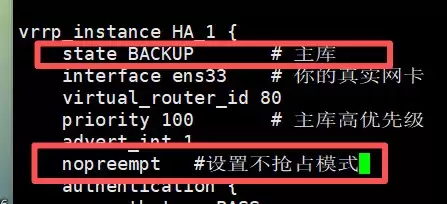
- 修改完成后,重启keepalived服务使其生效。
systemctl restart keepalived
总结
通过以上步骤,我们完成了一个基于MySQL双主复制与Keepalived的高可用集群搭建。这种架构不仅实现了数据的双向同步,还通过虚拟IP(VIP)和自动故障检测机制,保证了数据库服务在单点故障时的业务连续性。无论是选择抢占模式还是不抢占模式,核心都在于根据实际业务场景,权衡故障恢复的速度与服务的稳定性。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

如何恢复RMAN备份期间产生的未归档在线日志_不完全恢复与Flashback的结合应用
为什么不能直接用 RECOVER DATABASE 恢复到备份结束时刻? 这里有个关键点常常被忽略:标准的RMAN全库备份(backup database),默认是不会去碰那些尚未归档的在线重做日志的。问题恰恰就出在这里——那些标记为 CURRENT 或 ACTIVE 的日志文件里,很可能躺着备份操

怎么防止开发人员通过MongoDB GUI工具误删生产表
MongoDB Compass 能删除生产集合是因为其本质是 mongosh 的图形封装,所有操作均通过标准驱动协议执行,若连接生产集群且用户具备 dropCollection 权限,点击“Drop Collection”即直接执行,无二次确认。 为什么 MongoDB Compass 也能删掉生产

如何优化SQL防御规则库_根据实际应用场景迭代规则
SQL注入规则越加越多反而拦截不准?是时候换个思路了 一个常见的误区是,将SQL注入防御视为“黑名单补丁”的堆砌。每当发现一种新攻击手法,就匆忙添加一条正则规则。这种做法的直接后果,便是规则库的无限膨胀,动辄上千条规则相互交织,不仅导致误报率飙升,更让那些精心构造的绕过攻击得以隐蔽地漏网。问题的核心

MongoDB分片迁移时出现"Lock busy"错误怎么办_锁争用与高负载下的重试策略
MongoDB分片迁移时出现 "Lock busy "错误怎么办:锁争用与高负载下的重试策略 遇到分片迁移时蹦出的“Lock busy”错误,确实让人头疼。这背后,往往不是简单的死锁,而是一场围绕配置服务器(config server)或目标分片元数据写锁的并发争夺战。想想看,当集群里同时跑着大量chu

如何配置RAC私有网络的Jumbo Frames_MTU 9000提升缓存融合传输效率
私有网卡支持MTU 9000需硬件、驱动、交换机端到端协同;仅操作系统设MTU无效,RAC须停集群统一配置并验证UDP巨帧流量与分片情况。 私有网卡是否真的支持 MTU 9000?先查硬件和驱动 不少团队一上来就直接修改 ifconfig 或者执行 ip link set mtu 9000,结果发现








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
