




MySQL|从SQL到数据的完整路径

一、引文
最近正在梳理MySQL的面试要点,索性开个专栏,把每天的学习心得记录下来。内容主要参考了小林coding和Ja vaGuide。今天深入了解了MySQL的架构和执行流程,没想到一条看似简单的SQL语句,在MySQL内部竟然要经历如此复杂的旅程。
二、MySQL 执行流程
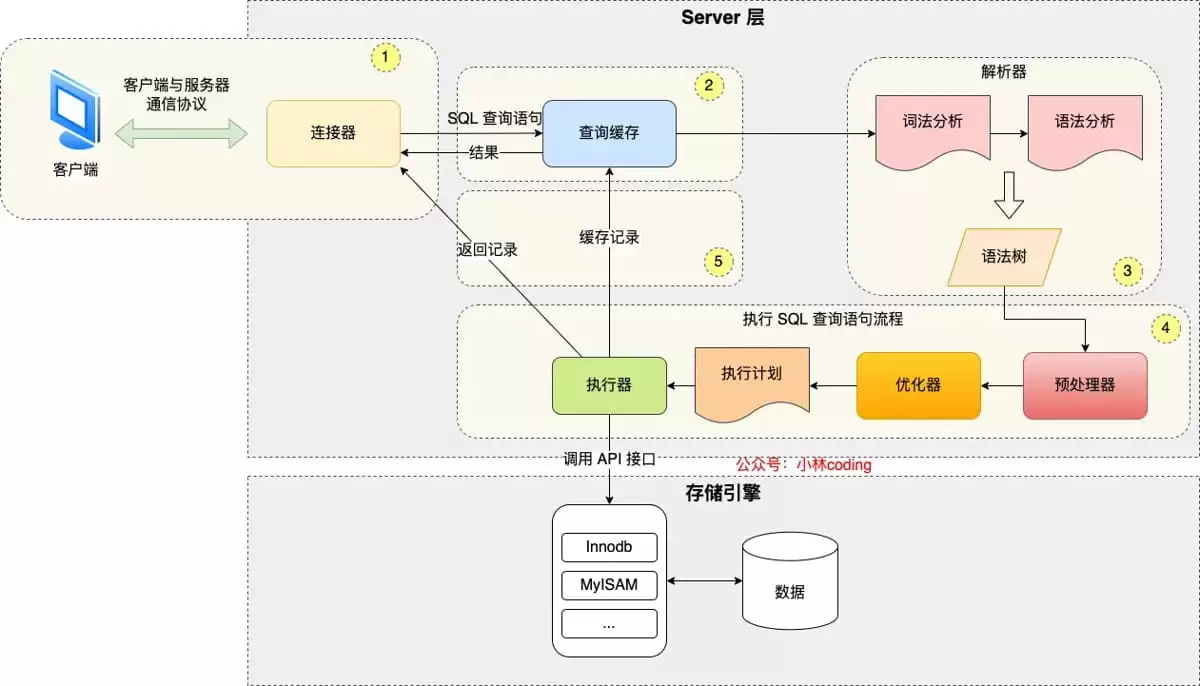
总的来说,MySQL的执行流程可以清晰地划分为两大层:服务层和存储引擎层。服务层负责“想”和“指挥”,涵盖了从建立连接到最终执行计划的生成;而存储引擎层则负责“干”,具体执行数据的存取操作。
1.服务层
(1)连接器
旅程的起点,是连接器。它的核心任务,就是为客户端(比如你的Ja va应用或者TablePlus这样的图形化工具)与MySQL服务端之间架起一座桥梁。这个过程,始于TCP的三次握手。
连接建立后,第一道关卡便是身份验证:校验用户名和密码。只有凭证正确,连接才会被正式建立。此时,连接器会将该账号对应的权限信息加载到内存中。这意味着,此后在这个连接的生命周期内,所有操作都将基于此刻记录的权限来执行,后续即使管理员修改了该账号的权限,只要连接不断开,当前连接依然沿用旧的权限。
说到连接,就不得不提长连接和短连接。短连接意味着“用完即弃”:执行一条SQL,连接就断开。而长连接则允许在一个连接会话中执行多条SQL。这两者的性能差异,可谓天壤之别。
为什么频繁创建连接代价高昂?原因在于那层层叠叠的“握手”开销:网络层的TCP三次握手、MySQL协议握手、可能的TLS/SSL握手,以及每次连接时MySQL都需要从系统表中查询并加载用户权限到内存。因此,在生产环境中,使用连接池来管理长连接是标准做法。
连接与内存的关系也极为密切。默认情况下,每个新连接都会对应创建一个工作线程,即便这个线程处于休眠(Sleep)状态,也会占用内存。为了避免大量线程导致内存溢出和CPU频繁的上下文切换,MySQL提供了线程池(Thread Pool)功能,用少量线程服务大量连接,从而有效控制资源消耗。
一个连接占用的内存,主要分为两大块:固定内存和临时内存。
(1) 固定内存 (Thread Static Memory)
这部分内存在连接建立时分配,直到连接断开才释放,是连接的“基础开销”:
- 线程栈 (Thread Stack):用于存储线程执行时的局部变量、函数调用栈等信息,大小由参数
thread_stack控制(默认约256KB)。 - 连接信息:存储用户、权限、当前数据库等会话状态信息。
- 网络缓存 (Net Buffer):用于暂存客户端发送的SQL和服务器返回的结果,大小由
net_buffer_length参数控制。
(2) 会话级临时内存 (Session Private Memory)
这部分是导致内存波动的“元凶”。当连接执行复杂SQL时,MySQL会按需动态申请:
- 排序缓冲区 (Sort Buffer):执行
ORDER BY或GROUP BY时使用。 - 连接缓冲区 (Join Buffer):执行多表关联查询时使用。
- 临时表内存 (Memory Temporary Table):存放复杂查询产生的中间结果。
- 结果集缓存:在将数据发送回客户端前暂存数据。
关键点在于:这些内存是按需分配的。一个不涉及排序的查询,就不会动用 sort_buffer。但风险也在于此:如果这些缓冲区参数设置过大,当成千上万的连接同时执行复杂操作时,内存可能被瞬间耗尽。
管理与回收机制
(1) 空闲连接的管理
一个执行完任务的长连接会进入 Sleep 状态。此时:
- 保留资源:基础的线程栈和网络缓存依然被占用。
- 释放资源:执行SQL时申请的临时内存(如
sort_buffer)会被释放。 - 超时断开:通过
wait_timeout参数控制。空闲时间超过此值的连接会被服务器强制断开,以回收资源。
(2) 线程缓存 (Thread Cache)
为了减少频繁创建和销毁线程的开销,MySQL实现了线程缓存机制:
- 连接断开时,其线程不会被销毁,而是放入缓存池。
- 当新连接到来时,直接从池中取出一个现成线程复用。
- 缓存池大小由
thread_cache_size参数控制。
掌握几个常用指令,有助于洞察连接状态:
show processlist // 查看当前所有客户端连接的情况
show variables like 'wait_timeout' // 查看客户端连接的最大空闲时长
show variables like 'max_connections' // 查看MySQL允许的最大连接数
kill connection id // 终止指定ID的连接
(2)查询缓存
连接建立后,客户端发送的SQL语句首先会被解析第一个字段,以判断类型。如果是SELECT查询,便会路由到查询缓存模块。
查询缓存以键值对(K-V)形式存储数据,Key是完整的SQL查询语句,Value是该语句的查询结果。如果当前SQL命中了缓存,结果便可直接返回,省去了后续所有步骤。
乍一看,这个设计很像Redis,似乎很美好。但仔细推敲就会发现问题:MySQL表中的数据是频繁更新的,一旦底层数据发生变化,对应的所有缓存条目就会立即失效,需要重建。想象一下,一个重建成本很高的缓存,刚建好,表数据又变了,缓存一次都没用上就被清除了,这无疑是巨大的资源浪费。正因如此,从MySQL 8.0开始,查询缓存功能被彻底移除了。
(3)解析器
缓存未命中(或MySQL 8.0之后),SQL语句就来到了解析器。解析器的工作分为两步:
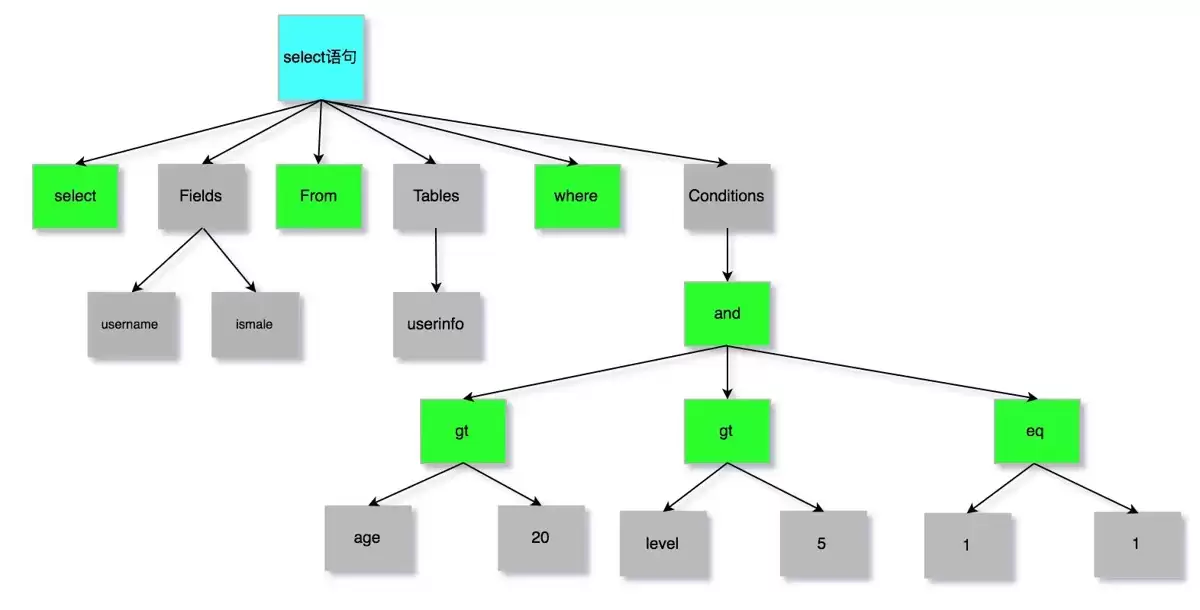
第一步,词法分析。 将输入的SQL字符串“切割”成一个个有意义的词元(Token),识别出哪些是关键字,哪些是用户自定义的标识符。例如,对于这样一条简单SQL:
SELECT name FROM userInfo
经过分析,会得到4个Token,其中包含2个关键字:
| 关键字 | 非关键字 | 关键字 | 非关键字 |
|---|---|---|---|
| select | name | from | userInfo |
第二步,语法分析。 在识别出词汇之后,解析器会基于MySQL的语法规则,检查这些Token组成的句子是否合法。如果语法正确,就会构建出一棵“语法树”,这棵树清晰地定义了SQL的类型、操作的表、涉及的字段等信息。如果语法有误(比如把SELECT拼成了SELECT),此时就会抛出经典的错误:You ha ve an error in your SQL syntax。
(4)预处理器
语法正确并不意味着语义正确。解析器生成的语法树,还会交给预处理器进行“语义检查”。预处理器会验证表名、字段名是否真实存在,确保查询的对象是有效的。如果表或字段不存在,就会在此阶段报错。此外,预处理器还会进行一些“扩展”工作,比如将
SELECT *中的*符号,具体展开为表上的所有列名。经过预处理后,会生成一棵新的、更精确的解析树,供后续步骤使用。
(5)优化器
如果说MySQL是一个智能系统,那么优化器就是它的“大脑”。当一条SQL存在多种可能的执行路径时(比如可以用A索引,也可以用B索引;多表关联时可以先查A表再关联B表,也可以反过来),优化器的职责就是从中选出它认为成本最低的那一个。
- 选择索引:当表上有多个索引时,决定使用哪一个。
- 决定连接顺序:在多表关联查询时,决定先查哪张表,后查哪张表。
- 核心目标:在保证结果正确的前提下,寻找执行成本(通常是磁盘I/O和CPU计算开销)最低的方案,并最终生成一个详细的执行计划。
看到优化器选择索引的案例,可能有些朋友对B+树索引、回表、覆盖索引这些概念有些生疏了。别担心,我们一起来快速回顾一下:
Q:两种 B+ 树索引的区别
在InnoDB存储引擎中,根据叶子节点存放内容的不同,索引分为两类:
主键索引(聚簇索引 - Clustered Index)
- 键值:表的主键
id。 - 叶子节点内容:存放的是完整的行记录数据。
- 特点:“索引即数据”。找到了主键,就相当于拿到了这行所有字段的值。
二级索引(辅助索引 - Secondary Index)
- 键值:建立索引的列(例如
name)。 - 叶子节点内容:存放的是对应记录的主键值。
- 特点:它不包含完整数据。通过二级索引查到记录,你只能得到主键ID。
Q:什么是“回表”?
来看一个典型场景:
SELECT price FROM product WHERE name = 'apple';
- 查询首先在 二级索引 (name) 的B+树中找到
apple。 - 从叶子节点拿到对应的 主键 id(假设是1)。
- 关键动作:为了获取
price字段,系统必须拿着id=1再去 主键索引 的B+树里查一遍。
这个“回到主键索引再查一次”的过程,就叫做“回表”。回表意味着额外的磁盘I/O,是影响查询性能的常见因素。
Q:什么是覆盖索引?
覆盖索引不是一种新的索引类型,而是一种理想的查询现象:
当一个索引已经包含了查询语句所需的所有字段时,MySQL就可以直接从索引中获取数据,完全避免回表。
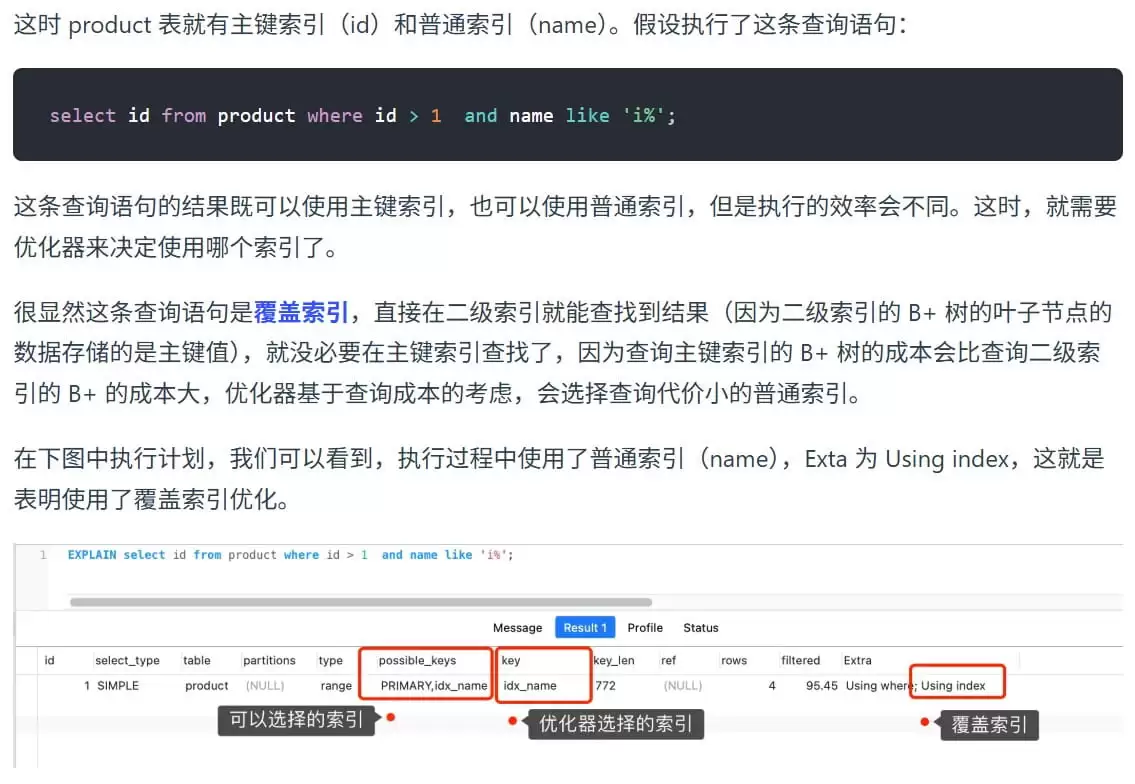
结合图中的例子理解:
查询语句:SELECT id FROM product WHERE id > 1 AND name LIKE 'i%';
- 查询所需字段:
id(SELECT部分)和name(WHERE条件部分)。 - 二级索引
name的内容:它按name排序,且叶子节点里存的就是id。 - 结论:这个
name索引已经“覆盖”了查询需要的全部信息(name和id)。
此时发生的情况是:
MySQL只需要扫描 name 这棵B+树,就能过滤出满足 i% 条件的记录,并直接从索引中取出 id 返回。它根本不需要去访问主键索引。这就是“覆盖索引”带来的性能红利。
复习完这些概念,再回头看优化器的选择就豁然开朗了。它之所以选择使用普通索引(name),正是为了利用“覆盖索引”优化。主键索引的叶子节点存储了整行数据,体积更大,扫描时产生的I/O自然也更多。而本次查询只需要 id 字段,它恰好存在于二级索引的叶子节点中。选择二级索引,既能利用索引快速定位,又能避免回表,一举两得。
想要查看优化器为你的SQL制定的执行计划,可以使用这个命令:
explain + 查询 SQL 语句 // 输出这条SQL语句的详细执行计划
(6)执行器
拿到最优执行计划后,就轮到执行器上场了。它的工作很直接:按照计划执行SQL。
- 权限校验:在执行具体操作前,会再次确认当前连接的用户对目标表是否有相应的操作权限(这是一个安全兜底)。
- 调用接口:根据执行计划,循环调用存储引擎层提供的各种API,完成数据的读取或写入。
这里提一个高级优化点:索引下推。这是一种能够减少回表操作的查询优化策略,其核心思想在于,将部分本应由Server层进行的过滤判断,“下推”到存储引擎层去完成。

如图所示,使用索引下推前后的关键区别,在于对 reward = 1000000 这个条件的判断时机。在没有索引下推时,存储引擎根据索引找到主键ID后,需要先回表取出完整数据行,再由Server层判断该条件。而启用索引下推后,这个判断被提前到了存储引擎层。存储引擎在扫描索引时,就可以利用索引中包含的 reward 信息进行过滤,对于不满足条件的记录,直接跳过,从而避免了大量不必要的回表操作,显著提升了查询性能。
2.存储引擎层
存储引擎层,是数据真正“安家”的地方。MySQL采用了插件式的存储引擎架构,常见的引擎有支持事务的InnoDB(目前默认引擎)和不支持事务的MyISAM等。
- 执行器每调用一次引擎的API,引擎就会根据指令,去磁盘(或内存中的Buffer Pool)查找对应的数据页,并将结果返回给执行器。
- 不同存储引擎的数据组织方式、索引实现、事务支持等特性各不相同,这也是MySQL灵活和强大的体现。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

用Qwen大模型为MySQL查询推荐最佳可视化图表
如何用Qwen大模型为MySQL查询自动推荐最佳可视化图表 你是否希望从MySQL查出的销售数据自动生成柱状图,而不是对着满屏数字发呆?刚写完一条SELECT语句,却不确定该使用折线图还是热力图来展示时间趋势?或者你把查询结果复制进Excel后才想起,其实散点图更能说明问题。这些场景是不是很熟悉?

MongoDB 4.0事务处理机制底层原理详解
MongoDB4 0多文档事务深度复用WiredTiger引擎原生多行事务能力,基于快照隔离和MVCC机制。事务启动获取clusterTime,读操作基于固定快照,写冲突在提交时检测。oplog异步刷盘可能影响持久性,生产环境需启用journal并控制事务超时。

Qwen大模型助力MySQL敏感数据脱敏与隐私保护
借助Qwen大模型一键生成合规的MySQL脱敏SQL语句 先看一个真实业务场景:你需要在MySQL中对姓名、手机号、身份证号这类敏感字段进行合规脱敏,且脱敏逻辑要具备可复用性、可审计性、可回溯能力。此时直接打开Qwen的Web界面或调用API,输入一条清晰指令就能搞定——例如:“请为MySQL表us

数据库里最反直觉的陷阱:NULL不等于空,90%新手踩过坑
NULL是数据库中表示“未知”的特殊标记,而非空值或0。它引入三值逻辑,导致用=NULL查不出数据、COUNT(column)忽略NULL、运算结果全为NULL、NOTIN遇NULL返回空、排序位置因数据库而异。正确处理需用ISNULL判断、COALESCE赋默认值、NOTEXISTS替代NOTIN,建表时尽量设置NOTNULL。

Qwen大模型生成MySQL性能优化量化对比报告测评
Qwen大模型能够基于两份CSV文件,自动生成一份包含QPS、延迟等8项核心指标的MySQL优化量化对比报告。您只需导出规范的CSV数据,使用特定提示词触发解析,再将结果转为HTML或PDF格式即可交付。此外,通过三步验证流程,可确保所有数据真实可信,满足技术评审要求。需要一份能直接用于技术评审或D








- 日榜
- 周榜
- 月榜



 相关攻略
相关攻略
 2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:08
2026-07-07 07:08
热门教程
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:09
2026-07-07 07:08
2026-07-07 07:08
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
