




python使用pdfplumber库一键提取pdf中的所有超链接

前言
在PDF文档中,可点击的超链接在技术规范中被称为“链接注释”。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
根据PDF标准,链接注释是一种特殊的注释类型。其核心机制定义了用户的可点击区域、指定了跳转目标(可以是外部网页URL,也可以是文档内部的特定页面),并允许设置视觉呈现样式。正是基于这一设计,PDF阅读器才能识别并响应用户的点击交互。
本文将详细介绍如何运用Python中的强大工具——pdfplumber库,来高效、准确地提取这些“隐藏”在PDF文档中的超链接。
pdfplumber库专注于PDF文档的解析与内容提取。无论是文档元数据(如作者、创建时间),还是复杂的结构化内容(如表格、文本、图片),乃至本文重点探讨的超链接,它都能胜任,足以满足绝大多数常规的PDF信息抽取需求。
其安装过程也极为简便,仅需一条pip命令:
pip install pdfplumber
使用 pdfplumber 提取 PDF 超链接的完整指南
提取超链接是pdfplumber的内置功能。每个页面对象都拥有一个.hyperlinks属性,调用该属性即可直接获取当前页面上的所有链接信息,并以结构清晰的字典列表形式返回。
以下是一段基础示例代码。我们使用pdfplumber打开名为“test.pdf”的文件,遍历每一页并通过.hyperlinks属性获取链接数据:
import pdfplumber
with pdfplumber.open(r'./data/test.pdf') as pdf_info:
for page in pdf_info.pages:
links = page.hyperlinks
print(links)
执行上述代码后,你将获得一个结构化的列表,其中包含了链接所在的页码、目标URI地址等关键信息。输出效果类似于下图所示:
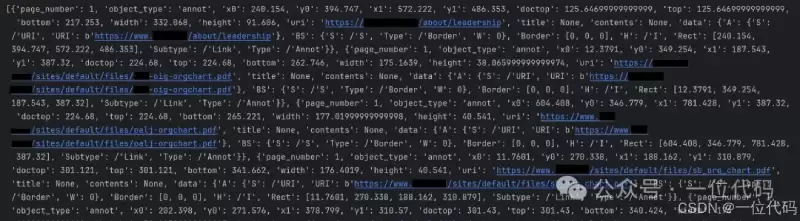
接下来,我们只需从这个字典列表中提取所需的信息(例如URI地址)即可。
下面是一个完整的函数实现。你只需将文件路径替换为你自己的PDF文件完整路径,运行后即可提取文档所有页面中的全部超链接。
import pdfplumber
def get_links(file_path):
res_links = []
with pdfplumber.open(file_path) as pdf_info:
page_number = 0
for page in pdf_info.pages:
page_number += 1
links = page.hyperlinks
if links:
for link in links:
res_link = link.get('uri')
res_links.append(res_link)
print(f'第{page_number}页,共有{len(links)}个超链接!')
else:
print(f'第{page_number}页,不存在超链接!')
return res_links
if __name__=="__main__":
# 文件路径为 pdf 完整路径
res_links = get_links('data/FCC_all.pdf')
print(res_links)
当然,这只是利用Python提取PDF超链接的其中一种高效方法,供各位开发者参考。
进阶技巧与补充方法
核心方法:提取全部超链接
其核心逻辑非常直接:打开PDF文件,遍历每一页,然后从页面的hyperlinks属性中获取uri(即目标网址)。
import pdfplumber
def extract_links(pdf_path):
all_links = []
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
page_links = page.hyperlinks
if page_links:
for link in page_links:
# 每个 link 是一个字典,'uri' 键存储了目标网址
uri = link.get('uri')
if uri:
all_links.append(uri)
return all_links
if __name__ == "__main__":
links = extract_links("你的文件.pdf")
for link in links:
print(link)
若希望明确每个链接的来源页码,可以在遍历时加入页码信息:
for i, page in enumerate(pdf.pages):
links = page.hyperlinks
if links:
print(f"第 {i+1} 页 有 {len(links)} 个链接")
for link in links:
print(f" - {link.get('uri')}")
else:
print(f"第 {i+1} 页 没有链接")
高级应用:灵活处理各类链接
区分处理不同类型的链接
需要注意的是,hyperlinks返回的字典可能不仅包含uri(网页链接)。还可能包含指向PDF文档内部其他页面的链接(键为page),或指向文档内某个命名目标的链接(键为nameddest)。进行区分处理能使脚本更加健壮。
if 'uri' in link:
print(f"网页链接: {link['uri']}")
elif 'page' in link:
print(f"内部链接: 第 {link['page']} 页")
elif 'nameddest' in link:
print(f"命名目标: {link['nameddest']}")
提取链接的锚文本(进阶技巧)
有时,我们不仅需要获取链接指向的地址,还想知道其在PDF中显示的文本内容(例如“点击查看详情”或“访问官网”)。pdfplumber本身未直接提供此功能,但可以通过间接方式实现:利用页面的chars属性(它包含了页面上每个字符的详细信息及其坐标)。基本思路是:首先获取链接的矩形区域坐标(x0, y0, x1, y1),然后筛选出所有位于该区域内的字符,最后将它们组合起来,即可得到链接的显示文本。这虽然涉及坐标计算,但对于处理复杂文档而言,是一项非常实用的技巧。
处理加密的PDF文档
若遇到受密码保护的PDF文件也无需担心。pdfplumber.open()方法提供了password参数,传入正确密码即可正常打开并解析。
with pdfplumber.open("encrypted.pdf", password="你的密码") as pdf:
# ... 正常提取链接
常见问题与注意事项
- 为何提取不到链接?关键概念:pdfplumber提取的是PDF标准定义的“链接注释”对象。如果你的PDF文档中的网址仅以纯文本形式存在(而非可点击的链接对象),那么使用文本搜索或正则表达式进行匹配会是更直接有效的方法。
- 注意
CroppedPage相关的潜在问题:如果你对页面对象执行了裁剪操作,可能会遇到与CroppedPage相关的超链接提取异常。若遇到此类情况,建议尝试将pdfplumber更新至最新版本,或者更稳妥的做法是:直接在原始的、未经裁剪的Page对象上进行链接提取。 - 扫描版PDF的处理限制:必须明确一点:pdfplumber主要适用于计算机直接生成的PDF文档。对于扫描版PDF(即由图片构成的文档),该库无法直接从中提取超链接甚至文本内容。在此类场景下,你需要先借助OCR技术(例如使用
pytesseract等工具)将图片中的文字识别出来,再进行后续的分析与处理。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

Go语言中Struct Tag详解:XML解析必备的字段标签机制
Go语言Struct Tag深度解析:XML数据绑定与字段映射的核心机制 Struct Tag是Go语言为结构体字段附加元数据的核心语法,广泛应用于XML、JSON等数据序列化场景。它通过反引号包裹的键值对进行声明,本质上是指导编码器与解码器如何精确映射结构体字段与外部数据格式。缺少它,Go程序将无

c#如何调用Python脚本_c#Python脚本的最佳实践与常见坑点
C 调用Python脚本:最佳实践与常见坑点解析 使用 Process Start 调用 Python 脚本:最直接但需注意路径与环境 在大多数情况下,Process Start 是实现C 调用Python脚本最快捷的方案。它无需引入额外的NuGet包,也不强制要求Python解释器必须配置在系统环

c#如何定义常量_c#定义常量的3种方式
C 常量定义:const、static readonly与静态类的实战指南 在C 编程实践中,常量的定义是基础但至关重要的环节。选择不当的常量声明方式,可能会为项目引入难以察觉的隐患。本文将深入解析C 中定义常量的三种核心方式:const、static readonly以及使用静态类进行封装,帮助你

c#如何使用MEF框架_c#MEF框架的正确用法与注意事项
CompositionContainer 初始化失败常因类型反射加载失败,主因是程序集版本 框架不匹配、DLL未显式加载或缺失部署依赖;Import为null则多因Catalog未包含对应Export、路径错误或契约不一致。 为什么 CompositionContainer 初始化失败常报“Unab

C#怎么压缩并解压ZIP文件_C#如何管理压缩包【实战】
C 怎么压缩并解压ZIP文件_C 如何管理压缩包【实战】 说到在C 里处理ZIP文件,一个核心原则是:System IO Compression 是最稳妥的 ZIP 压缩方案。这意味着,你需要显式设置压缩级别为 CompressionLevel Optimal,使用正确的 ZipArchiveMod








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
