




SSA架构算力骤降千倍成本仅为Opus百分之五

SubQ模型采用全新SSA架构,通过动态选择关键Token计算注意力,将计算量降低千倍,处理1200万Token上下文成本仅为ClaudeOpus的5%。该模型在多项基准测试中性能媲美顶尖模型,由13人团队开发。其突破性设计可能重塑大模型效率范式,但真实性仍需独立验证。
Transformer统治地位悬了!一款SubQ模型带着SAA架构横空出世,1200万上下文成本仅Opus的5%,计算量暴减千倍。
Transformer架构的王座,似乎开始松动了。
最近,一款名为SubQ的AI模型横空出世,其背后全新的架构思路,足以让整个行业侧目。它号称是全球首个基于完全亚二次方稀疏注意力架构(SSA)的模型,能够处理高达1200万Token的上下文长度。

关键在于,SubQ的SSA架构引入了一种“动态选择”机制。它不再像传统Transformer那样,强制计算序列中所有Token之间的关联,而是根据内容本身,智能地筛选出真正需要关注的焦点。这种思路上的根本转变,带来了惊人的效率提升——据称,其计算量相比标准Transformer直接减少了1000倍。
实验数据显示,在处理100万Token的上下文时,SubQ的速度比经过极致优化的FlashAttention-2还要快52倍以上,而成本更是不到Claude Opus的5%。

更令人惊讶的是,打造出这一架构的Subquadratic公司,总部位于迈阿密,整个团队仅有13人。消息一出,便在AI社区引发了激烈讨论。有行业观察者甚至评论道:“如果这一切都是真的,那么Anthropic和OpenAI的估值恐怕要归零了。” 也有人认为,这或许才是大型语言模型未来真正实现规模扩展的正确路径。

Transformer的“原罪”:九年未解的效率困局
自2017年谷歌那篇划时代的论文《Attention Is All You Need》发表以来,Transformer架构便奠定了其在AI领域的统治地位。过去九年,从GPT到Claude,再到Gemini,几乎所有前沿大模型都建立在同一个核心基础之上:密集注意力机制。

然而,这种机制存在一个根本性的效率瓶颈。它的工作方式堪称“暴力”:序列中的每个Token都需要与所有其他Token进行一次关联计算。这就导致了著名的“二次方复杂度”问题——上下文长度每增加一倍,所需的计算量便会飙升四倍。
后果显而易见:输入越长,模型运行就越昂贵、越缓慢,也越容易达到硬件极限。这直接解释了为何当前主流大模型的上下文窗口大多被限制在百万Token级别左右。并非技术上无法做到更长,而是经济上难以承受。SubQ的出现,正是试图从根本上改写这个效率等式。

SSA架构:核心思路是“做减法”
SubQ实现突破的关键,在于其SSA架构——亚二次方稀疏注意力。其设计思路出奇地清晰:既然在训练好的模型中,绝大多数注意力权重都趋近于零,那么为何还要耗费巨量算力去计算它们呢?
SSA采取了一种更聪明的策略。对于每一个查询(Query),模型会基于其内容语义,在长序列中动态地选择出真正值得关注的那些位置,然后仅在这些选定的位置上进行精确的注意力计算。换句话说,它只计算那些有意义的交互,而主动跳过了超过99%的、贡献微乎其微的计算。
这一架构带来了三个核心特性:
线性扩展: 计算量仅随选中的关键位置数量线性增长,而非随整个序列长度呈二次方爆炸。这意味着上下文长度翻倍,成本也大致只翻倍,而非四倍。
内容依赖路由: 模型根据语义相关性决定关注哪里,而非固定的位置偏移。无论关键信息藏在序列的第3个还是第1100万个Token,都能被有效定位。
精确检索: 它不像循环神经网络那样将历史信息压缩成固定维度的状态,而是保留了从原始上下文中任意位置精确检索信息的能力。
本质上,SSA的创新不在于“如何把密集注意力算得更快”,而在于“如何让模型聪明地减少不必要的注意力计算”。

减少的计算开销,直接转化为了实实在在的速度优势。
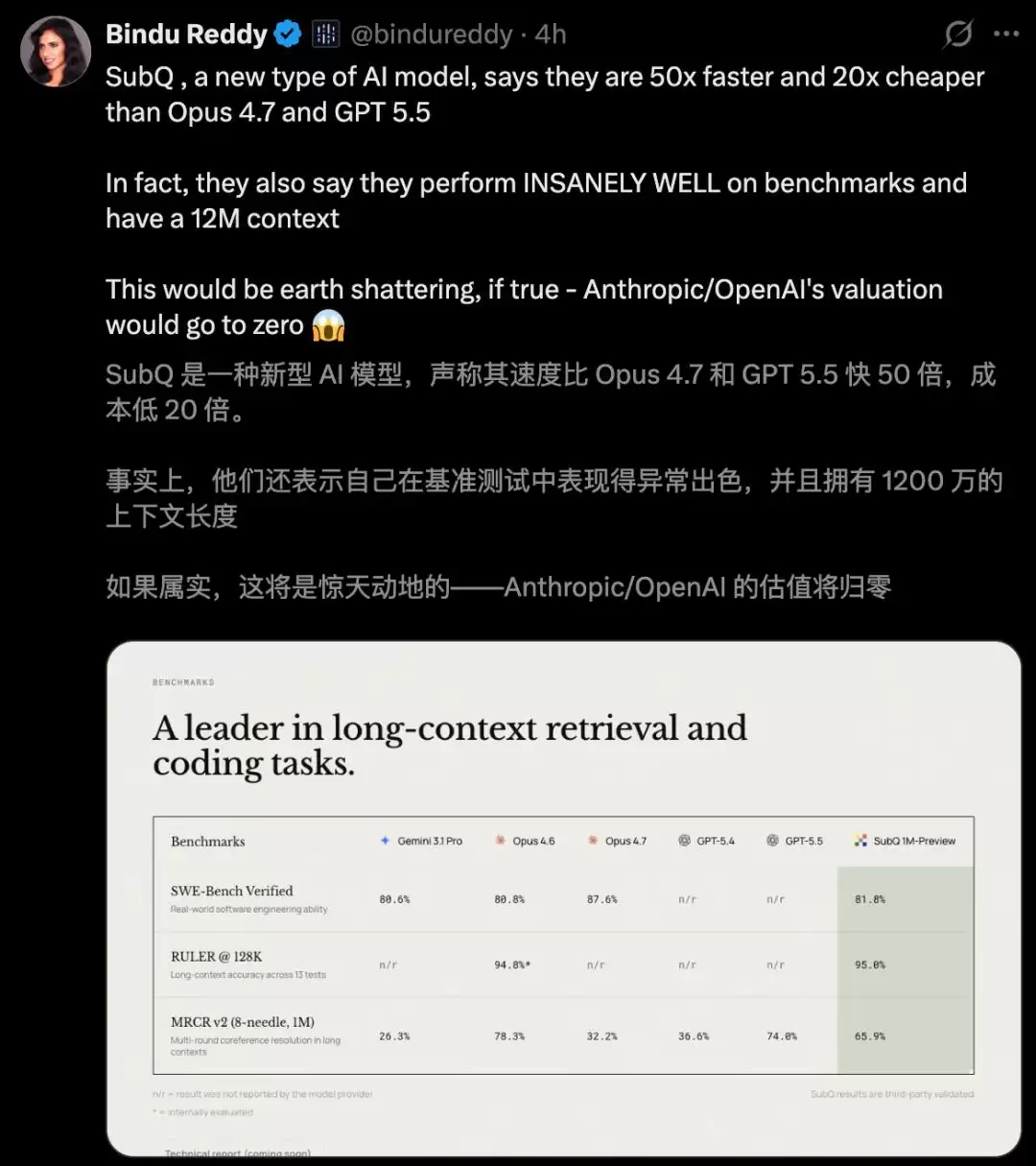
性能实测:速度与成本的碾压式优势
Subquadratic公司公布的一系列基准测试数据,每一项都极具冲击力。
在100万Token的序列长度上,SSA架构相比标准的密集注意力配合FlashAttention-2优化,速度快了52.2倍。随着上下文增长,优势呈指数级扩大:在12.8万Token上快7.2倍,25.6万Token上快13.2倍,51.2万Token上则达到23倍。这完美印证了SSA的线性扩展特性——传统方法越长越慢,而SSA则越长越显划算。


算力消耗的降低更为惊人。在100万Token下,注意力部分的浮点运算次数减少了62.5倍;当序列长度达到1200万Token时,这一数字飙升到了近1000倍。

成本对比则更为直观。在RULER 128K基准测试上,SubQ的调用成本约为8美元,而达到相近效果的Claude Opus则需要2600美元,两者相差超过300倍。
最关键的是,这些速度和成本优势,并未以牺牲模型能力为代价。在多项核心基准测试中,SubQ表现出了强大的竞争力:
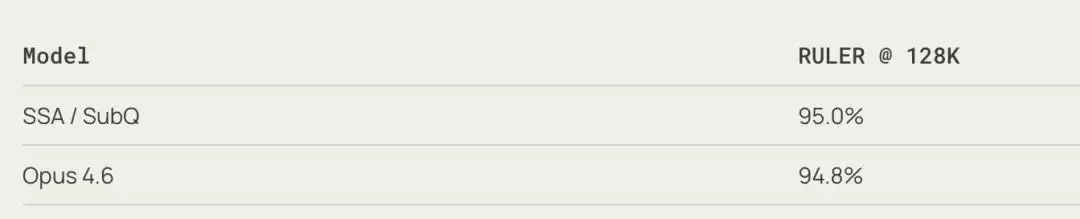
- RULER 128K(长上下文理解): SubQ得分95%,略高于Opus 4.6的94.8%。
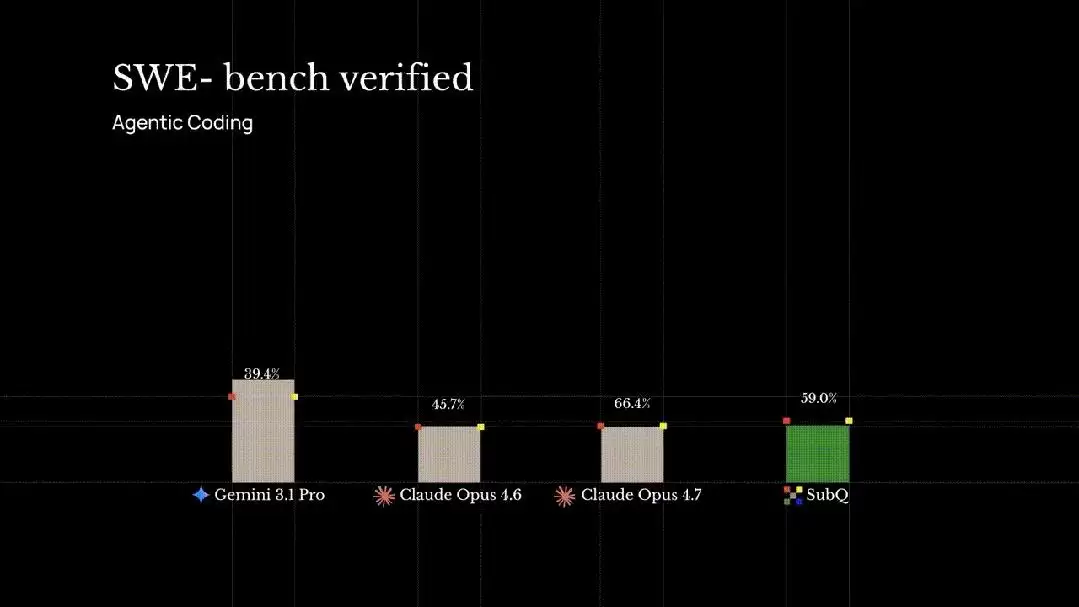
- SWE-Bench Verified(代码工程任务): SubQ得分81.8%,超过了Opus 4.6的80.8%。
- MRCR v2(长上下文信息检索): SubQ获得65.9%,虽低于Opus 4.6的78%,但显著超越了GPT-4o的39%和Gemini 1.5 Pro的23%。
综合来看,这组数据揭示了一个令人震撼的事实:一家尚处于种子轮阶段的初创公司,以其架构创新,用不到行业巨头5%的成本,在多项关键任务上达到了与顶尖模型持平甚至超越的水平。

凭借1200万Token的超长上下文能力,SubQ可以轻松将整个代码库、长达数月的项目记录或长期运行的智能体状态一次性输入处理,而成本据说仅为传统方法的五分之一。

如果其宣称的性能经得起独立验证,这无疑是Transformer架构问世以来,最具碘伏潜力的突破之一。
13人团队:小公司的大野心
Subquadratic公司成立于2024年,目前已获得2900万美元的种子轮融资,估值达到5亿美元。公司由两位联合创始人领导:CEO Justin Dangel和CTO Alexander Whedon。

其研究团队虽仅有11人,但全部拥有博士学位,成员背景来自Meta、谷歌、牛津大学、剑桥大学、Adobe等顶尖机构。一个有趣的细节是,这家公司前身名为Aldea,最初专注于语音模型,后来才全面转向注意力架构的基础研究。
此次发布,Subquadratic一次性推出了三条产品线:
- SubQ API: 提供完整的1200万Token上下文处理能力。
- SubQ Code: 一个命令行编码智能体,能够将整个代码库作为上下文进行分析。
- SubQ Search: 一款深度研究工具,发布初期将免费提供。
行业反响:碘伏性突破还是过度营销?
SubQ的发布迅速在AI社区内引发了两极分化的讨论。正如一位AI从业者所言,SubQ面临两种极端的可能性:它要么是Transformer以来最重要的架构突破,要么就可能成为AI领域的“Theranos”(指曾轰动一时后被证实为骗局的血液检测公司)。

支持者认为这是2026年最令人兴奋的AI发布之一,Subquadratic可能找到了萨姆·奥特曼曾预言的那种“另一个架构”的重大突破。许多人对这种从根本上提升效率的路径表示期待。

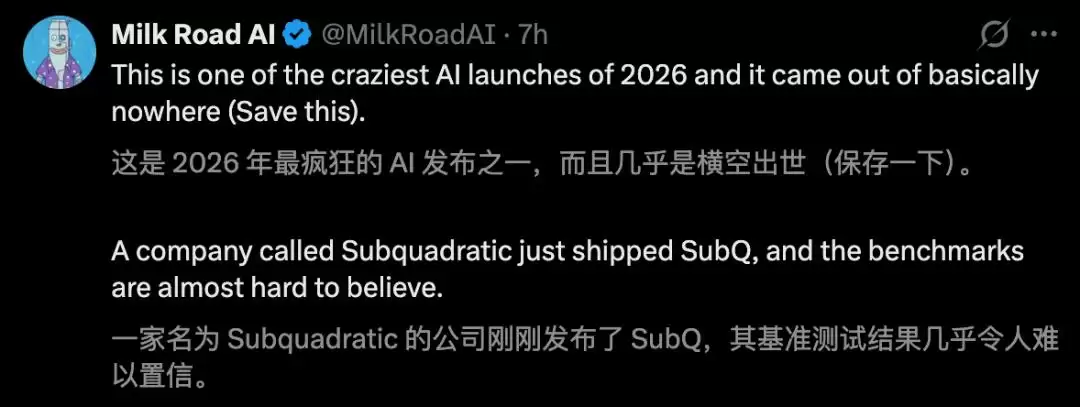
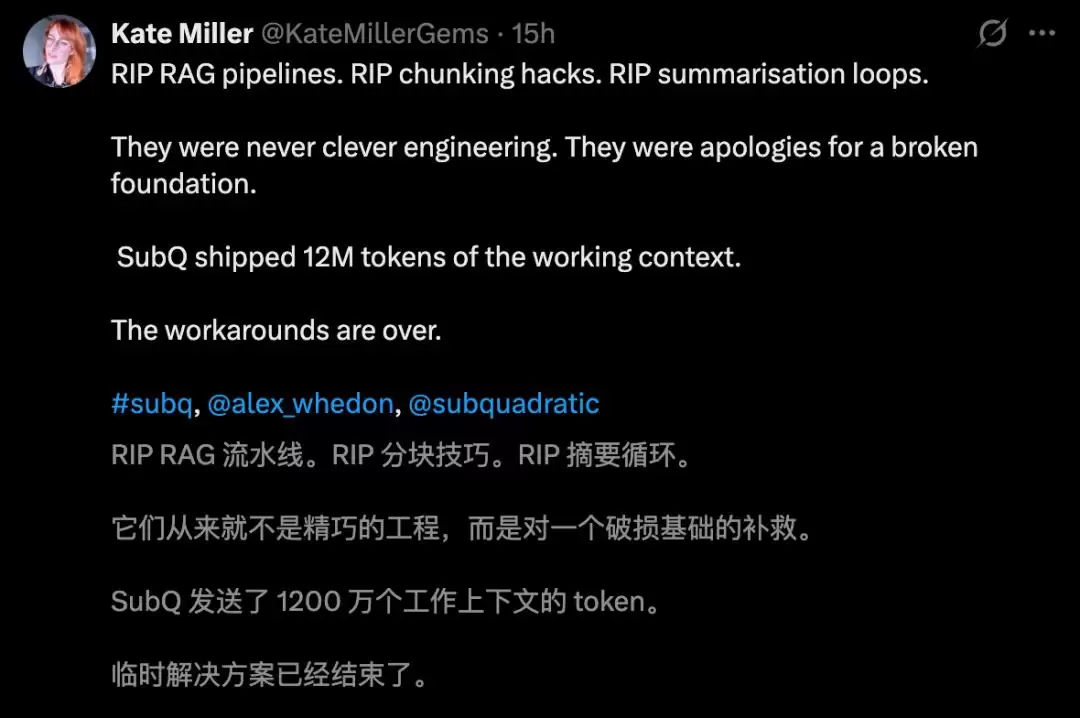
然而,怀疑论者的声音同样尖锐。有人质疑其技术真实性,尤其是在审视了创始人的背景后,认为这可能是一场营销噱头。

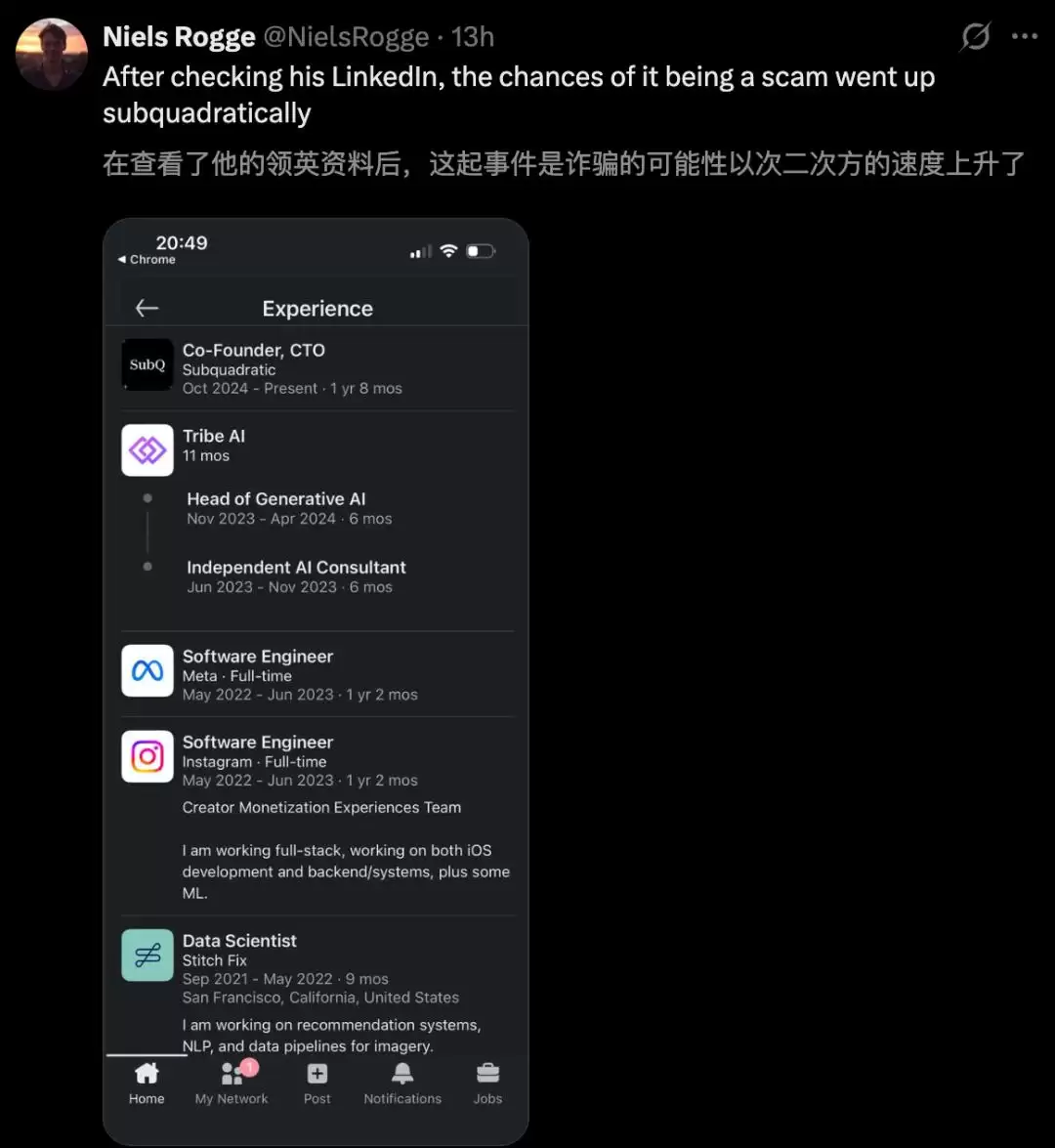
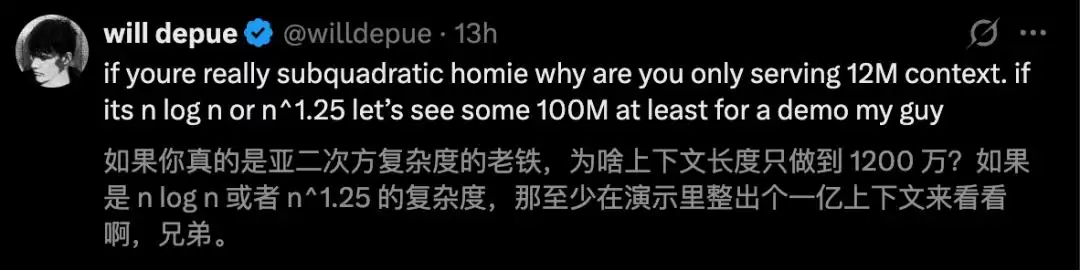
前OpenAI研究员Will Depue更是连续发文指出,SubQ的技术“几乎可以确定是基于Kimi或DeepSeek已有的稀疏注意力模型进行的微调”,而非其宣称的全新架构。

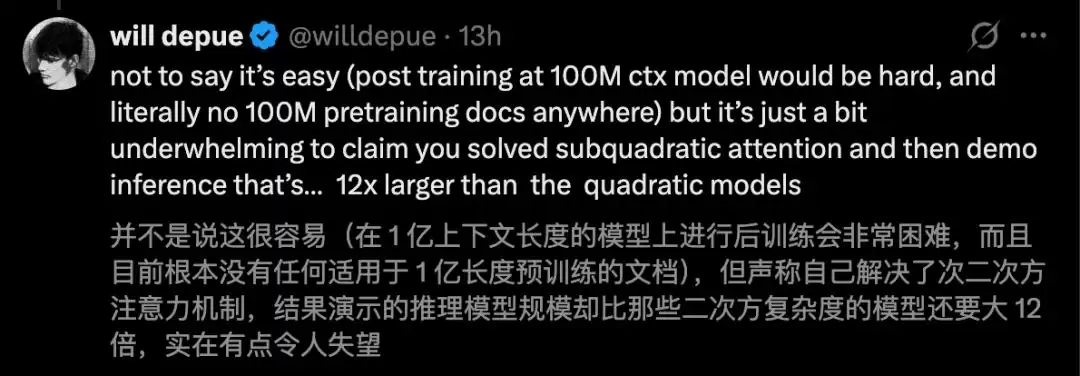
AI领域见证过太多“发布会即巅峰”的故事,华丽的PPT演示与真实世界的大规模可靠部署之间,往往存在一条巨大的鸿沟。但另一方面,正因为这项技术潜在的碘伏性如此巨大,整个行业也无法对其视而不见。最终的答案,恐怕要等到详细的技术报告公开、并由第三方机构进行独立的基准测试复现后,才能真正水落石出。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

先导智能交付海外首条全极耳圆柱电芯产线助推欧洲豪车电气化转型
先导智能成功交付海外首条全极耳圆柱电芯产线,用于欧洲顶尖豪华车品牌德国诺德林根电池工厂。产线搭载自研智能系统,实现单电芯100%在线溯源,AI视觉检测识别潜在风险,焊接不良率和运营成本均降低30%。

八位堂Xbox机械键盘新版新增RGB背光
八位堂推出Retro87机械键盘Xbox版,采用初代Xbox透明绿外壳,首次加入RGB背光,提供八种模式。键盘为87键布局,搭载凯华JellyfishX开关,内置2000mAh电池,续航达200小时。同步发布RetroR8鼠标,配备PAW3395传感器和充电底座。键盘现已在亚马逊开启预售,售价119 99美元,2025年1月16日发货。

天硕V60 256GB SD卡 高速稳定的卓越品质 开启存储新境界
天硕V60256GBSD卡具备256GB容量,读取260MB s、写入150MB s,支持4K60P视频录制。采用长江存储闪存与自研主控,达到IP68三防等级,兼容主流相机,集成纠错编码与磨损均衡技术,为专业影像创作提供可靠存储方案。

i扫地机器人全球热销 高端市场占有率30%
杉川机器人全球高端扫地机器人市场占有率达30%,获广东省制造业单项冠军。公司全球出货超千万台,拥有多项专利。其净水循环与空气制水技术实现终生不用加清水、倒污水,突破传统使用瓶颈。

荣耀笔记本X Plus系列全新配色定档12月2日
荣耀笔记本XPlus系列将于12月2日发布,推出浅海蓝新配色,搭配银色品牌标识,主打轻薄机身。该系列首发搭载酷睿第二代英特尔酷睿5处理器,续航提升。荣耀CEO预告明年将全面布局PC领域。同期荣耀300系列也将发布。








- 热门数据榜



 相关攻略
相关攻略
 2026-07-11 15:04
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:02
2026-07-11 15:02
热门教程
2026-07-11 15:04
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:03
2026-07-11 15:02
2026-07-11 15:02
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程
















