




复旦智院联合开源BARD-VL多模态扩散模型实现新突破

多模态大模型的竞争已进入新阶段:追求更强性能的同时,必须兼顾更快的推理速度。当前,基于自回归范式的视觉语言模型(VLM)在理解能力上不断突破,但其“逐词生成”的串行解码机制也带来了显著的推理延迟和高昂的部署成本。在文档解析、多模态智能体等需要生成长文本的实际应用场景中,速度瓶颈正严重制约着模型的可用性与普及。
免费影视、动漫、音乐、游戏、小说资源长期稳定更新! 👉 点此立即查看 👈
相比之下,扩散模型凭借其并行解码的先天优势,理论上能通过同时生成多个词元来大幅提升效率,被视为长文本生成的理想解决方案。然而,一个核心挑战始终存在:如何将性能顶尖的自回归VLM高效、无损地转换为扩散VLM,确保其强大的多模态能力在转换后得以保留?这已成为学术界与工业界共同关注的关键课题。
近期,一项名为BARD的创新研究为此提供了新思路。该工作由上海科学智能研究院联合上海创智学院、复旦大学等团队共同完成,提出了一套全新的桥接转换框架。其核心目标是:将预训练好的自回归VLM,高效地转化为同架构的扩散VLM,从而释放并行解码的巨大潜力。实验表明,基于Qwen3-VL转换得到的BARD-VL模型,在多项基准测试中保持甚至超越了原模型性能,同时实测解码吞吐量最高提升达3倍,实现了效率与性能的双重突破。

1、现状与挑战:自回归的瓶颈与扩散模型的困境
自回归VLM在各类多模态任务上表现卓越,这已是不争的事实。然而,随着生成序列长度的增加,串行解码带来的计算负担和响应延迟,已从理论问题演变为实际落地的主要障碍。
扩散多模态模型通过并行更新整个文本块,被视为提升生成效率的有效路径。但在实践中,研究者发现,若简单地将成熟的AR模型直接转换为大块扩散模型,其核心能力往往会出现显著衰退。这种性能损失的根源在于两种范式内在的“监督信号不匹配”:自回归模型习惯于在清晰的前文语境下预测下一个词;而扩散模型则需要学会从被噪声干扰的、模糊的状态中,恢复出正确的词元序列。
这种根本性差异,使得直接进行知识迁移的效果常不理想。因此,多模态生成领域面临着一个两难选择:自回归模型能力强但速度慢,扩散模型速度快却可能牺牲精度。如何实现“鱼与熊掌兼得”,已成为推动模型走向大规模实际应用的关键。
2、BARD 核心机制:搭建范式平滑迁移的「桥梁」
BARD的巧妙之处在于,它并未选择从零训练一个原生扩散模型,而是设计了一套系统化的桥接方案,将“能力继承”与“效率提升”两个目标进行解耦与分别优化。
2.1 渐进式监督块合并

为避免从“逐词生成”直接跳跃到“大规模并行生成”可能引发的学习困难,BARD引入了一种渐进式策略。具体而言,模型并非一步到位,而是从预训练好的AR模型出发,先构建一个并行粒度极小的扩散模型作为起点。随后,按照(4,8,16,32)这样的序列,逐步扩大并行解码的文本块大小。在每一步中,模型只需学习如何将相邻的两个小预测块合并成一个更大的块,这极大地降低了学习难度,确保了转换过程的平稳与可靠。
2.2 阶段式扩散蒸馏
针对前述的“监督错位”难题,BARD创新性地重新设计了蒸馏目标。它并未使用原始的自回归模型作为教师,而是巧妙地让前一阶段已训练好的扩散模型来指导当前阶段。由于学生模型与教师模型均运行在相同的扩散机制下,两者的“推理语言”相通,监督信号自然更加精准匹配。实验证明,在块大小为32的设置下,这种扩散蒸馏方法在MMMU、RealWorldQA等多个核心评测指标上的提升幅度,显著超越了传统的自回归蒸馏。
2.3 工程优化:应对长序列训练的实用策略
除了架构创新,BARD在工程实现上也进行了深度优化,以切实解决长序列训练中的挑战。
首先是混合噪声调度器。传统的掩码扩散模型擅长补全缺失信息,但纠错能力较弱。BARD在掩码噪声的基础上,额外引入了对可见词元的均匀破坏。这使得模型在训练中同时掌握了“信息补全”与“错误修正”两项关键技能,显著增强了其在复杂多模态场景下的鲁棒性与泛化能力。
其次是内存友好的训练布局。多模态序列通常包含海量的视觉词元,对训练显存构成巨大压力。BARD采用了高效的序列打包布局,将输入上下文、干净的响应文本以及被噪声干扰的响应文本封装在同一个序列中,并通过精心设计的注意力掩码来确保信息流的正确隔离。这一优化,大幅提升了长序列多模态任务的训练效率与可行性。
3、实验结果:性能与效率的双重验证
研究团队基于高质量数据进行了充分训练,并在7项核心多模态评测基准上进行了全面验证。
3.1 综合能力对比

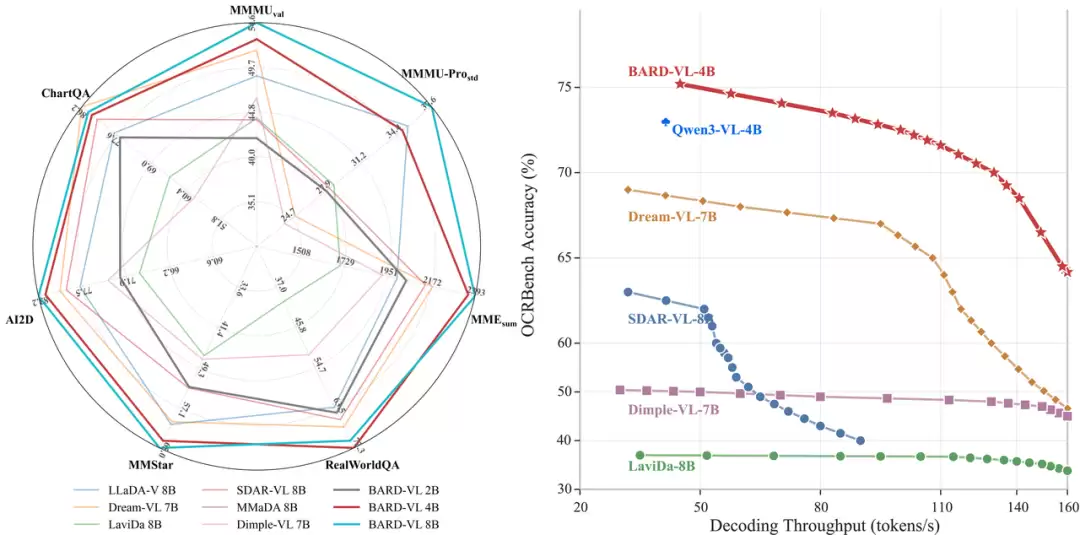
具体来看,在40亿参数规模下,BARD-VL相比原版Qwen3-VL 4B,在7项评测中有5项表现更优。在80亿参数规模下,提升更为全面,在7项评测中领先了6项。与同期其他开源扩散VLM进行横向比较,BARD-VL 8B在这套评测集上全面超越了LLaDA-V 8B,其40亿版本也在所有7项评测上超过了Dimple-VL。这充分证明,桥接转换不仅成功保留了原模型的知识,更在多个维度实现了性能的超越。
3.2 推理效率分析
更为关键的是,这些性能提升并非以牺牲速度为代价换来的。效率分析曲线显示,BARD-VL 4B在很宽的解码吞吐量区间内,都能保持更高的任务准确率。在一个具体的票据信息抽取示例中,BARD-VL仅需6次扩散迭代即可得到准确结果,而原始的自回归模型则需要35步串行解码。对于文档理解、表单处理等天然的长输出任务,这种并行解码带来的效率优势,已非常接近实际生产部署所期待的改进目标。

4、结论与展望
BARD工作的核心价值在于,它有力地证实了一个重要观点:高性能的自回归模型与高效的扩散解码范式,并非不可兼得。通过精心设计的桥接框架,我们可以系统地将AR模型积累的丰富知识,平滑迁移到更高效的并行架构之中。尽管当前实验主要基于Qwen系列模型展开,但其展现出的良好可扩展性与鲁棒性,无疑为未来开发更高效的多模态智能体和长上下文交互系统指明了清晰的技术方向。
这项工作的深远意义还体现在其与垂直领域大模型的结合潜力上。例如,团队正在深耕的“炎黄”中华文明大模型,旨在服务于历史、考古等人文社科研究。而此次开源的BARD-VL所代表的先进扩散底座能力,正可助力此类领域大模型在追求极致性能的同时,获得更优的推理效率,从而真正赋能复杂的科研分析与实际应用场景。对于所有在模型能力、推理速度与部署成本之间寻求最佳平衡点的研究者和开发者而言,BARD提供了一条极具参考价值的技术路径与可行性验证。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

黄仁勋批评硅谷AI巨头制造末日恐慌
英伟达CEO黄仁勋公开批评硅谷部分科技领袖渲染AI末日恐慌,认为其出于“上帝情结”与功利目的,误导公众并阻碍行业发展。他否定AI将取代大量工作的威胁论,强调AI是创造新机遇的生产力工具。同时指出美国社会对AI的过度恐惧抑制了创新,而亚洲市场则以更务实态度推动技术落地。

复旦智院联合开源BARD-VL多模态扩散模型实现新突破
BARD-VL提出一种桥接框架,通过渐进式监督块合并与阶段式扩散蒸馏,将预训练自回归视觉语言模型高效转换为扩散模型。该方法在保持性能的同时,实现最高3倍的解码吞吐量提升,显著降低了生成延迟。

Midjourney生成探险家遗迹氛围图的详细教程
在Midjourney生成探险家与遗迹图像时,可通过四维结构设计提示词,聚焦风化痕迹、生物侵蚀等细节以增强真实感,结合动态交互与多尺度污染元素构建叙事,或采用第一人称视角提升临场感,从而营造出富有张力与可信度的考古探索氛围。

ChatGPT为何频繁提及哥布林 AI军备竞赛面临哪些挑战
ChatGPT用户发现其回复频繁提及“哥布林”,尤其在“书呆子”风格下更明显。OpenAI调查后承认,这是模型训练中强化学习机制导致的意外偏差,反映了AI行业在快速迭代中测试不足的困境。类似“砍一刀”等词汇怪癖也表明,奖励机制可能使模型行为难以预测和控制,成为当前大语言模型的普遍问题。

Claude的八大独特优势ChatGPT无法替代
如果你同时深度使用过Claude和ChatGPT,大概率会察觉到一种微妙的差异:它们带来的工作体验,并不完全相同。 一个能在单次对话中处理海量文档,另一个在图像生成和实时搜索上更游刃有余。一个可以直接在聊天窗口里搭建出可交互的应用原型,另一个则更多时候将代码交付给你自行运行。 这些差异并非营销话术,








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
相关攻略
 2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
2015-03-10 11:25
2015-03-10 11:05
2021-08-04 13:30
2015-03-10 11:22
2015-03-10 12:39
2022-05-16 18:57
2025-05-23 13:43
2025-05-23 14:01
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程































 热门话题
热门话题
