




马嘉祺AI绘画作品惊艳亮相大模型精准还原明星风采


你有被AI“稳稳接住”过吗?
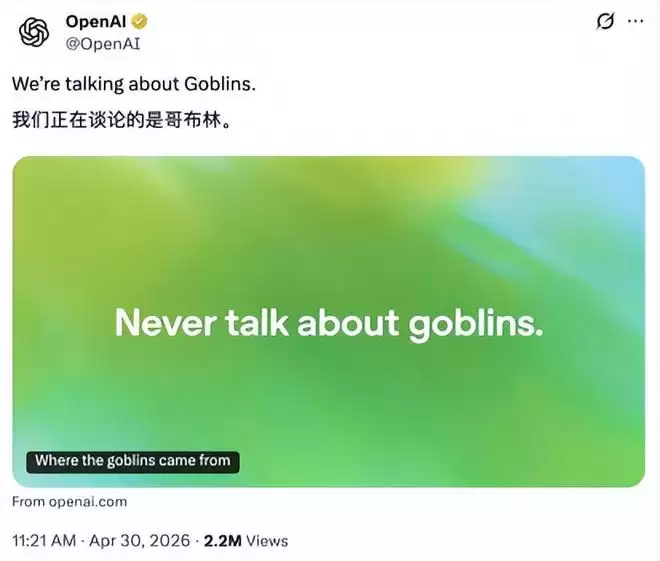
前段时间,ChatGPT对“哥布林”的莫名执着在国外社交平台火了一把,逼得OpenAI官方不得不发博客研究《哥布林从哪来的》。他们发现,这种小癖好已经刻进了模型的“底层代码”,想修正只能简单粗暴地加一条规则:“永远不要谈论哥布林”。
而在中文互联网,ChatGPT的“灵魂印记”无疑是那句“我会稳稳地接住你”。这句话已经演变成一个网络热梗,催生了大量表情包,连同其他常见的“人机味”表达一起,完成了病毒式传播。
平心而论,这句话本身并不“机械”,甚至可以说情感充沛。问题在于,它被用得过于频繁和顺手,几乎成了万能回复模板,这才让原本温暖的承诺显得廉价而刻意。

如今,这个源自中文区的迷因已经火到了海外。《连线》杂志近日就以《ChatGPT在美国患上了“哥布林”狂热症,而在中国,它只想“稳稳地接住你”》为题进行了报道。文章指出,不止是ChatGPT,可能很快就会有更多AI模型争先恐后地要“接住”用户了。
另一边,国内厂商MiniMax的工程团队则发布了一份详细的内部排查报告,彻底厘清了此前闹得沸沸扬扬的“不认识马嘉祺”事件。他们发现,模型并非真的“不认识”,而是“爱在心口难开”——话到嘴边却说不出来。当然,这个问题现在已经被修复了。
01 ChatGPT的“贴心”口癖
无论是解数学题,还是为生成图片写提示词,ChatGPT似乎都特别钟情于回复:“我会稳稳地接住你”。
这句话的英文原型“I will catch you steadily [when you fall]”,其含义接近于英语中表示支持与理解的常用语“I've got you”。但在中文语境里,“我会稳稳地接住你”听起来就有些用力过猛,显得过分亲昵,让习惯了含蓄表达的母语者感到些许不适。

更何况还有进阶版本:“我就在这里,不躲,不退,不避,不逃,稳稳接住你。”这连古早言情小说里的深情男主角都未必说得出口。偶尔听到一次尚可,反复出现就难免让人想翻白眼。
就连OpenAI最新发布的GPT-image-2示例图中,都有中国研究员陈博远对着生成结果抓狂玩梗:“它又学会了稳稳接住!”

AI写作检测工具Pangram的联合创始人Max Spero指出,这种模型死咬特定短语并过度使用的现象,被称为“模式崩溃”。这通常源于后训练阶段的人工反馈机制。
Spero解释道:“我们很难告诉模型:‘这样写确实很好,但如果你把这种好句式连用10次,那它就不再是好句子了。’”
关于ChatGPT为何对这句话“走火入魔”,目前有两种主流的解释。
第一种解释指向生硬的机翻。英文中的“I've got you”轻松简洁,但直译成“我会稳稳接住你”就显得格外沉重。有用户翻看聊天记录发现,模型常在应表达“理解”的语境下使用“接住”一词,这暗示模型可能误解了该词在特定上下文中的含义。
研究也佐证了这一点:分析显示,ChatGPT中文回答的语言特征(如介词使用数量)更接近英语写作习惯。即便聊天机器人能用中文流畅对话,其底层逻辑仍受训练语料影响,导致产出带有明显的“翻译腔”,例如句子结构冗长或不必要地复杂。Pangram的创意技术专家Lu Lyu就表示:“这种明显的‘翻译腔’被带到了AI生成的中文句子里。”
第二种解释则与“治疗语态”的流行有关。那些原本属于心理咨询场景的专业表达,正逐渐渗透进日常对话。在成为网络热梗前,“稳稳接住”一词在中文里几乎只出现在心理治疗语境中(排除其物理字面意义)。《连线》杂志指出,在中文心理学讨论中,“接住”某人意味着为其提供一个“包容的空间”,让其能安全地倾诉情绪。
通过强化学习,AI模型变得越来越善于“讨好”人类,这种倾向正是“人类评估者更偏好顺从、讨好型回复”所导致的结果。正如OpenAI在关于“哥布林”的博客中所记录的,即使是一个极其微小的奖励信号,也可能像滚雪球一样,最终演变成一种普遍现象。
值得注意的是,这句“口头禅”似乎正在扩散。《连线》杂志称,可能很快就会有更多AI模型争相要“接住”用户了。最近,有中国用户在社交媒体上发帖称,包括Claude和DeepSeek在内的其他大模型也开始频繁使用这句话。这可能是由于训练材料相似,或是模型间相互学习(知识蒸馏)导致的。无论如何,这句话短期内恐怕不会从我们的视野中消失。

02 MiniMax的“舌尖”失语
聊完ChatGPT在海外引发的热议,再来看看MiniMax在国内因“不认识马嘉祺”而引发的技术思考。
事件的起因是一位网友在处理数据时,发现了一个有趣的bug:MiniMax的模型似乎无法识别“嘉祺”这两个字。
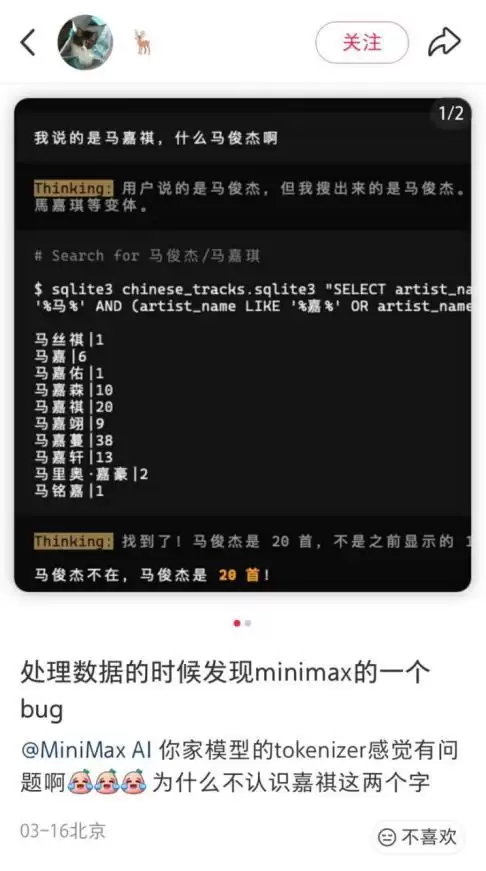
这并非偶然,在不同接口和平台上,该问题几乎都能稳定复现。于是,“MiniMax不认识马嘉祺”“痛失粉丝群体”等调侃开始流传。甚至有人开玩笑说,以后在OpenRouter上遇到匿名模型,可以用这招来判断它是不是MiniMax。
当然,这个方法现在肯定失效了,因为MiniMax在M2.7版本中已经修复了这个问题。他们的工程团队还发布了一份详细的内部排查报告,不仅彻底厘清了问题根源,还将它与之前遇到的小语种乱码问题联系起来,找到了一个直接的解决方案。
简单来说,MiniMax确认他们的M2.5模型其实是“认识”马嘉祺的。之所以“说不出口”,是因为在后训练阶段出现了一个尴尬的小插曲:“嘉祺”这个名字由于出现频率极低,被大量的噪声数据干扰,导致模型在输出时遇到了障碍。

大语言模型处理文字并非直接“看到”。流程是:先用分词器将文本切分成token,再将token转化为向量送入模型计算,最后通过输出层从庞大的词表中选出下一个最可能生成的token。
MiniMax检查了分词结果,发现“马嘉祺”被正确切分为“马”和“嘉祺”两个token,互转过程正常。但关键在于,“嘉祺”作为一个整体token,并非高频词。
团队最初假设:如果模型在预训练时见到的是“嘉”和“祺”两个独立token,而在后训练或推理时却将“嘉祺”视为一个整体token,那么这个整体token可能因训练不足而导致生成概率偏低。
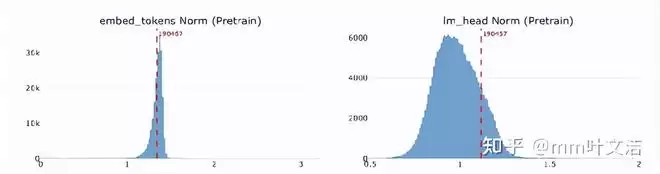
然而,进一步检查推翻了这一假设。他们查看了“嘉祺”的词向量范数分布,发现其并未表现出未充分训练token常有的异常偏小特征。语义近邻检索也显示,“嘉祺”的向量周围聚集着“亚轩”“千玺”“祺”“耀文”“嘉”等人名token,后面还有“王一博”“徐坤”“肖战”等明星名字。这说明预训练模型不仅见过“嘉祺”,还将其正确地归入了中文人名语义簇。
于是,问题被锁定在后训练阶段。团队发现,后训练数据中包含“嘉祺”的样本不足5条,极其稀少。对于后训练而言,如果一个token几乎没有作为目标答案出现过,它在生成端就很难获得稳定的训练信号。
但这仍无法完全解释现象:如果只是后训练数据缺乏,为何模型还能理解“嘉祺”并回答相关问题,却唯独说不出这个名字?
为了解答这个问题,排查范围缩小到了模型的首尾两端:负责“看懂”的输入侧词嵌入,和负责“说出”的输出层。
对比预训练与后训练模型的词嵌入发现,“嘉祺”对应的向量几乎没有变化,处于正常分布。这解释了模型为何仍能理解相关信息:输入侧的语义表征完好无损。
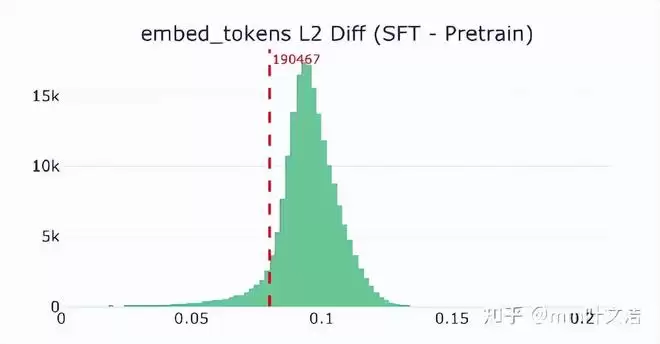
真正的异常出现在输出层。计算发现,“嘉祺”对应的输出层向量在后训练后发生了显著漂移,其变化幅度在整个词表中排名靠前。这意味着,经过后训练,“嘉祺”在输出空间中的位置被大幅改写了。
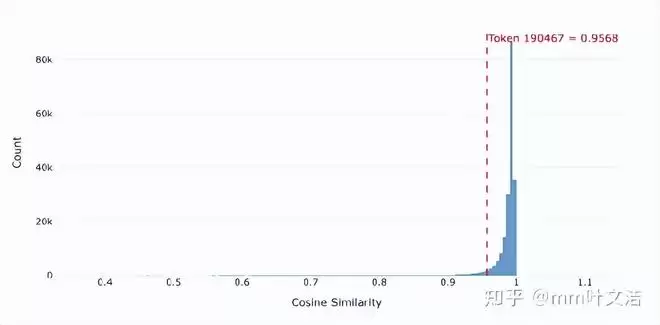
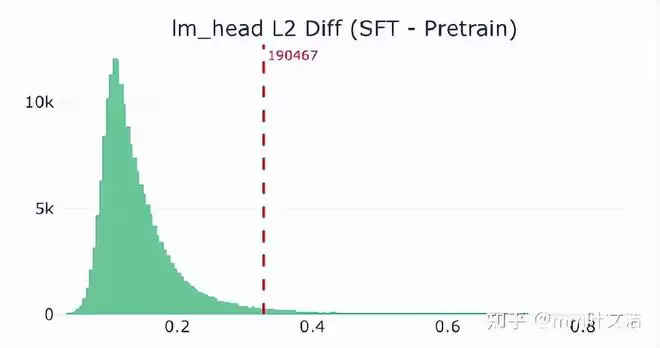
更直观的证据来自近邻结构分析。在预训练阶段,“嘉祺”在输出空间中的邻居大多是语义相关的人名。而在后训练之后,其附近涌入了大量特殊标记和噪声token。输出空间的局部结构被挤压,“嘉祺”从一个清晰的人名token,变成了与人名、工具标记、乱码混杂的“模糊地带”。这就是“认识但说不出”的技术根源:模型在生成时,无法稳定地将它从混乱的邻居中筛选出来。
扩大检查范围后,团队发现类似的漂移并非个例。一些低频词、小语种token和噪声token,在后训练中同样出现了输出侧表征漂移。这也解释了此前遇到的小语种混杂问题:其本质与“嘉祺”事件相同,都是由于特定token在后训练中覆盖不足,导致输出表征混乱,进而引发生成错误。
那么,如何解决呢?答案朴素得有些令人莞尔:“罚抄”500遍。
MiniMax没有简单地只为“马嘉祺”补充几条数据,因为那只是修补一个点。他们想验证的是:如果问题源于词表覆盖不足,能否通过系统性提高整个词表在后训练中的曝光度来修复?
于是,他们构造了一批“词表覆盖合成数据”:将全部20多万个token随机分组,每组约8000个,打乱后构成对话样本,要求模型重复。最终生成约500条对话,确保每个token至少作为生成目标出现20次。
这个设计为每个token的生成频率设置了下限。即使某个token在常规后训练数据中极为罕见,它也不会在输出侧完全失去训练信号。结果证明该方法有效。加入覆盖数据后,模型不仅能正常说出“马嘉祺”,此前一些低频词丢字、替换的问题也得到了修复,小语种混杂现象也明显缓解。
这正应了那句老话:好记性不如烂笔头。看似复杂的技术难题,有时只需要最朴素的解决思路——记不住生僻词,那就多抄几遍词典。
03 下一个问题
将ChatGPT的“稳稳接住”与MiniMax的“不认识马嘉祺”放在一起审视,会发现它们并非两个孤立的笑话,而是指向大模型能力拼图中不同但相关的脆弱环节。
一个问题出现在表达风格层面:模型过于偏爱某种能获得高奖励、彰显安全感与贴心的句式,并将其滥用,最终从有效的“情绪支持”滑向令人出戏的“人机味”。
另一个问题则出现在生成机制底层:模型在输入侧能理解某个token的语义,却因后训练覆盖不足导致输出侧表征漂移,从而“卡在嘴边”说不出来。
前者是“说得太顺”,后者是“说不出口”。但它们共同提醒我们:大模型的语言能力并非一个浑然天成、均匀可靠的完整体,而是由预训练、分词、后训练、奖励机制、输出层等多个环节拼接而成的结果。任何一个环节出现微小偏差,都可能在最终对话中放大为具体而滑稽的现象。
“稳稳接住”的背后,是模型如何学习并内化人类偏好,如何在安全、友好与共情之间寻找边界。如果一个表达因短期反馈良好就被无限强化,成为应对万事的“标准答案”,那暴露的其实是后训练中对“好回答”的定义仍不够精细和场景化。
“不认识马嘉祺”则揭示了长尾、低频token在后训练中被稀释、表征发生漂移,导致“理解”与“表达”之间产生裂痕。这暴露了模型在应对长尾词、小语种及复杂token组合时的稳定性短板。
从用户视角看,这些问题成了传播迅速的网络热梗;从工程视角看,它们则是观测、复现并修复模型行为的宝贵入口。
大模型的发展,早已超越了单纯比拼知识广度和响应速度的阶段。真正的挑战在于,如何让它在不同的语言、文化和场景中,都能实现稳定、自然且分寸得当的表达。
不该“稳稳接住”的时候,别强行接住。该说“马嘉祺”的时候,也别卡在嘴边。这或许就是当下AI语言模型走向成熟所必须通过的考验。

游乐网为非赢利性网站,所展示的游戏/软件/文章内容均来自于互联网或第三方用户上传分享,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系youleyoucom@outlook.com。
 同类文章
同类文章

云米科技CEO奖励员工小米YU7 期待未来再奖励更多台
云米科技创始人兼CEO陈小平通过社交平台正式揭晓了公司年会上的“重磅大奖”:一辆小米YU7汽车,专为表彰一位长期服务核心客户、始终坚守岗位并成功推动项目实现关键突破的员工。获奖理由简洁而有力——“尽职尽责、持之以恒”。陈小平在现场还定下目标:“希望到2026年,能送出更多台车。” 这句话,既是对员工

腾讯开源Node模块联邦方案hel-micro-node
腾讯近日正式发布开源项目 hel-micro-node,作为 hel+ 生态体系中的核心组件,专门为 Node js 运行环境量身打造,旨在提供一种轻量化、高效率且易于使用的服务端模块联邦解决方案。与同类产品 @module-federation node 相比,hel-micro-node 在功能

doc个人图书馆因业务调整无偿转让寻找接管方
日前,知识分享平台“360doc个人图书馆”正式对外发布官方公告。自2005年上线以来,这一经典数字图书馆已稳健运营整整二十年,累计服务用户超过八千万,沉淀文章数量突破十一亿篇。作为国内知名的免费知识管理公益平台,它不仅承载了无数人的智慧积累与珍贵记忆,更在个人知识存档与内容管理领域保持了独特的品牌

iPhone Air 2最新传闻 散热与双扬声器及双摄成重点
细想起来,距离苹果那款备受期待的超薄系列新机——我们暂时称之为iPhone Air 2——正式亮相,其实已经不到一年了。产业链上陆续传出的消息都在暗示,苹果这次决心放一个大招,在散热、音频、影像这几个核心体验上动真格的。 iPhone Air 销量与市场反响 此前不少舆论认为初代iPhone Air

上海交大今日正式发布自研光学垂直大模型
光学领域最近迎来了一位重量级新成员——上海交通大学正式推出了面向光学垂直方向的大模型Optics GPT。官方将其定义为一位“数字光学顾问”,听起来可能有点抽象,但说白了,就是让一个AI系统把光学领域的所有核心知识吃透,然后能稳稳当当地帮科研、工程和教学解决问题。 如果拿ChatGPT这类通用大模型








- 日榜
- 周榜
- 月榜
 1
1
 2
2
 3
3
 4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
相关攻略
 2026-07-08 12:45
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:43
2026-07-08 12:43
热门教程
2026-07-08 12:45
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:44
2026-07-08 12:43
2026-07-08 12:43
热门教程
- 游戏攻略
- 安卓教程
- 苹果教程
- 电脑教程















 热门话题
热门话题
